基于Gensim的文本相似度计算
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Gensim的文本相似度计算相关的知识,希望对你有一定的参考价值。
参考技术A Gensim 是一个Python的自然语言处理库,所用到的算法,如 TF-IDF (Term Frequency–Inverse Document Frequency), 隐含 狄利克雷分配 (Latent Dirichlet Allocation,LDA), 潜在语义分析 (Latent Semantic Analysis,LSA) 或 随机预测 (Random Projections)等, 是通过检查单词在训练语料库的同一文档中的统计共现模式来发现文档的语义结构,最后转化成向量模式,以便进行进一步的处理。此外,Gensim还实现了word2vec功能,能够将单词转化为词向量。语料(corpus) 是一组原始文本的集合,用于无监督地训练文本主题的隐层结构。语料中不需要人工标注的附加信息。在Gensim中,Corpus通常是一个可迭代的对象(比如列表)。每一次迭代返回一个可用于表达文本对象的稀疏向量。
向量(vector) 是由一组文本特征构成的列表。是一段文本在Gensim中的内部表达。
词典(dictionary) 是所有文档中所有单词的集合,而且记录了各词的出现次数等信息。
模型(Model) 是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。
用一个实验去理解:
# -*- coding: UTF-8 -*-
from gensim import corpora,similarities,models
import jieba
classGensimExp(object):
def__init__(self,documents,test_document,Type,feature_num,best_num):
self.raw_documents = documents
self.test_document = test_document
self.SimCalType = Type
self.num_features = feature_num
self.num_best = best_num
defCalSim(self):
corpora_documents = []
#分词
foritem_textinself.raw_documents:
item_seg = list(jieba.cut(item_text))
corpora_documents.append(item_seg)
# 生成字典和语料
dictionary = corpora.Dictionary(corpora_documents)
# 计算每一条新闻对应的bow向量
corpus = [dictionary.doc2bow(text)fortextincorpora_documents]# 迭代器
ifself.SimCalType =='Similarity-tfidf-index':
# 统计corpus中出现的每一个特征的IDF值
tfidf_model = models.TfidfModel(corpus)
corpus_tfidf = tfidf_model[corpus]
self._similarity = similarities.Similarity(self.SimCalType, corpus_tfidf, \
num_features=self.num_features,num_best=self.num_best)
test_cut_raw = list(jieba.cut(self.test_document))
test_corpus = dictionary.doc2bow(test_cut_raw)
# 根据训练后的model,生成IF-IDF值,然后计算相似度
self._test_corpus=tfidf_model[test_corpus]
elifself.SimCalType =='Similarity-LSI-index':
lsi_model = models.LsiModel(corpus)
corpus_lsi = lsi_model[corpus]
self._similarity = similarities.Similarity(self.SimCalType, corpus_lsi, \
num_features=self.num_features,num_best=self.num_best)
test_cut_raw = list(jieba.cut(self.test_document))
test_corpus = dictionary.doc2bow(test_cut_raw)
self._test_corpus=lsi_model[test_corpus]
self.Print_Out()
defPrint_Out(self):
string ='The Most Similar material is '
fortplinrange(len(self._similarity[self._test_corpus])):
iftpl != len(self._similarity[self._test_corpus]) -1:
string = string + str(self._similarity[self._test_corpus][tpl][0]) \
+'('+ str(self._similarity[self._test_corpus][tpl][1]) +'),'
else:
string = string + str(self._similarity[self._test_corpus][tpl][0]) \
+'('+ str(self._similarity[self._test_corpus][tpl][1]) +')'
print(string)
if__name__=='__main__':
raw_documents = [
'0 1月19日,中信集团与腾讯在深圳签署战略框架协议,宣布将推进云和大数据、区块链、人工智能等技术领域的业务合作,积极探索实体产业的数字化转型升级路径。',
'1 浦发银行公告称,公司成都分行因违规办理信贷业务等违规行为被银监会罚款4.62亿元,处罚金额已全额计入2017年度公司损益,对公司的业务开展及持续经营无重大不利影响。 ',
'2 【浦发回应浦发成都分行违规被罚4.62亿:深感愧疚】从浦发银行总行方面了解到,浦发银行对于成都分行发生的违规发放贷款案件深感愧疚;对于监管部门的查处表示坚决支持和接受,同时将以此为鞭策强化自身管理,坚持从严治行,在未来的经营发展中始终将依法合规经营作为立行之本。(一财)',
'3 苏试试验公告,公司1332万股首次公开发行前已发行股份将于1月24日解禁,占公司总股本的10.61%;解禁日实际可上市流通股份为1221.5万股,占总股本的9.73%。本次申请解除股份限售的股东有苏州试验仪器总厂和钟琼华、陈晨、武元桢、陈英等4位自然人股东。',
'4 波士顿科学和国药控股子公司据悉参与竞购XIO旗下的Lumenis。',
'5 苏宁云商回复深交所问询函:苏宁金融研究院于2017年7月正式成立区块链实验室,该实验室针对区块链技术及其在金融行业的应用进行研究,旨在利用区块链技术为苏宁金服业务及苏宁银行业务提供技术支撑。苏宁银行区块链国内信用证信息传输系统采用联盟链方式,只在联盟银行之间免费使用,不对外直接提供服务,该系统无直接收入产生。',
'6 龙马环卫公告,公司1.60亿股首次公开发行限售股将于1月26日上市流通,涉及股东包括现任董事、监事及高管张桂丰等17人。',
'7 航天工程公告,公司3.24亿股首次公开发行限售股将于1月29日上市流通,涉及股东为中国运载火箭技术研究院、航天投资控股有限公司、北京航天动力研究所、北京航天产业投资基金(有限合伙)及全国社会保障基金理事会转持二户。',
'8 大千生态公告,公司与江苏大千设计院有限公司组成的联合体,预中标高淳区东坝镇特色田园乡村建设项目EPC总承包项目,项目投资估算约1.4亿元。项目的顺利实施,将对公司本年度的经营业绩产生积极影响。',
'9 1954年2月19日,苏联最高苏维埃主席团,在“兄弟的乌克兰与俄罗斯结盟300周年之际”通过决议,将俄罗斯联邦的克里米亚州,划归乌克兰加盟共和国',
'10集友股份公告,公司预计2017年实现净利润与上年同期相比,将增加约4250万元至5300万元,同比增加约80.49%-100.37%,上年同期实现盈利5280.38万元。本期收入较上期增长较多,营业利润较上期增长;收到的政府补助及理财收益等非经常性损益事项对公司净利润的影响约为3200万元。',
'11【千山药机:大股东质押股票跌破平仓线】千山药机公告,第一大股东、实控人之一刘祥华合计持有公司14.83%股权。目前,刘祥华共质押公司13.78%股权。刘祥华质押给国泰君安证券的2980.8万股股票已跌破平仓线。公司目前正在被证监会立案调查,根据有关规定,公司在被立案调查期间大股东不得减持(包括股权质押平仓)公司股份。因此本次刘祥华质押的股票跌破平仓线不会导致公司实际控制权发生变化。',
'12天马精化:子公司拟逾亿元控股中科电子,加码供应链管理发展战略。',
'13超华科技公告,于近日收到参股子公司贝尔信员工通知,反馈贝尔信公司近期与其董事长郑长春无法取得联系。截至目前,公司亦尚无法与贝尔信董事长郑长春取得联系。经与贝尔信主要股东商议,经贝尔信董事会审议通过后将由贝尔信现有管理层组成临时工作小组,以维持贝尔信正常生产和经营秩序。公司全面开展对贝尔信的核查,以维护上市公司及股东的利益。',
'14胜宏科技公告,公司预计2017年实现盈利2.8亿元-2.9亿元,同比增长20.65%-24.96%,上年同期盈利2.32亿元。报告期内,公司预计非经常性损益对净利润的影响约1000万-1300万元。',
'15东旭光电公告,控股股东东旭集团员工成长共赢计划已完成对公司股票的购买,总计购买公司股票1119.01万股,占总股本的0.2%,成交金额合计约1.02亿元,成交均价约9.12元/股。'
]
Obj1 = GensimExp(raw_documents,'数字化转型升级路径','Similarity-tfidf-index',600,5).CalSim()
Obj2 = GensimExp(raw_documents,'违规办理信贷业务','Similarity-tfidf-index',600,3).CalSim()
Obj3 = GensimExp(raw_documents,'本期收入较上期增长较多','Similarity-LSI-index',400,2).CalSim()
实验结果:
由于语料库不多,选择返回相似的文本个数较少,不过也能大致看出判断是正确的。(PS:分词的过程中没有进行停用词处理)
参考:
https://radimrehurek.com/gensim/tutorial.html
python 用gensim进行文本相似度分析
http://blog.csdn.net/chencheng126/article/details/50070021
参考于这个博主的博文。
原理
1、文本相似度计算的需求始于搜索引擎。
搜索引擎需要计算“用户查询”和爬下来的众多”网页“之间的相似度,从而把最相似的排在最前返回给用户。
2、主要使用的算法是tf-idf
tf:term frequency 词频
idf:inverse document frequency 倒文档频率
主要思想是:如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
第一步:把每个网页文本分词,成为词包(bag of words)。
第三步:统计网页(文档)总数M。
第三步:统计第一个网页词数N,计算第一个网页第一个词在该网页中出现的次数n,再找出该词在所有文档中出现的次数m。则该词的tf-idf 为:n/N * 1/(m/M) (还有其它的归一化公式,这里是最基本最直观的公式)
第四步:重复第三步,计算出一个网页所有词的tf-idf 值。
第五步:重复第四步,计算出所有网页每个词的tf-idf 值。
3、处理用户查询
第一步:对用户查询进行分词。
第二步:根据网页库(文档)的数据,计算用户查询中每个词的tf-idf 值。
4、相似度的计算
使用余弦相似度来计算用户查询和每个网页之间的夹角。夹角越小,越相似。
1 #coding=utf-8 2 3 4 # import warnings 5 # warnings.filterwarnings(action=‘ignore‘, category=UserWarning, module=‘gensim‘) 6 import logging 7 from gensim import corpora, models, similarities 8 9 datapath = ‘D:/hellowxc/python/testres0519.txt‘ 10 querypath = ‘D:/hellowxc/python/queryres0519.txt‘ 11 storepath = ‘D:/hellowxc/python/store0519.txt‘ 12 def similarity(datapath, querypath, storepath): 13 logging.basicConfig(format=‘%(asctime)s : %(levelname)s : %(message)s‘, level=logging.INFO) 14 15 class MyCorpus(object): 16 def __iter__(self): 17 for line in open(datapath): 18 yield line.split() 19 20 Corp = MyCorpus() 21 dictionary = corpora.Dictionary(Corp) 22 corpus = [dictionary.doc2bow(text) for text in Corp] 23 24 tfidf = models.TfidfModel(corpus) 25 26 corpus_tfidf = tfidf[corpus] 27 28 q_file = open(querypath, ‘r‘) 29 query = q_file.readline() 30 q_file.close() 31 vec_bow = dictionary.doc2bow(query.split()) 32 vec_tfidf = tfidf[vec_bow] 33 34 index = similarities.MatrixSimilarity(corpus_tfidf) 35 sims = index[vec_tfidf] 36 37 similarity = list(sims) 38 39 sim_file = open(storepath, ‘w‘) 40 for i in similarity: 41 sim_file.write(str(i)+‘\\n‘) 42 sim_file.close() 43 similarity(datapath, querypath, storepath)
贴一下我的test代码。
我的test文件querypath是一个问题,datapath是对这个问题的各种回答,我试图通过文本相似度来分析问题和哪个答案最匹配。。
原博客的测试是querypath是商品描述,datapath是商品的评论,通过文本相似度来分析,商品描述和实际的商品是否差异过大。
贴一下我的测试数据。很小的数据,就是测试一下这个:
注意所有的数据已经经过分词处理,分词怎么处理,可以用python的jieba库分词处理。可以参考http://www.cnblogs.com/weedboy/p/6854324.html
query

data

store(也就是结果)
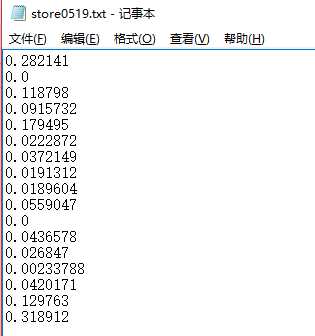
测试结果和问题实际上最应该匹配的对不上。。
总结:
1.gensim 除了提供了tf-idf 算法,好好利用
2.我用jieba分词的忘记删掉停用词了,给结果带来很大影响,jieba库里有函数可以删停用词的
3.问答系统中,关于问题和答案匹配,如果不用有监督的机器学习是不行的。。
以上是关于基于Gensim的文本相似度计算的主要内容,如果未能解决你的问题,请参考以下文章
机器学习使用gensim 的 doc2vec 实现文本相似度检测