短文本相似度计算
Posted cxf-zzj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了短文本相似度计算相关的知识,希望对你有一定的参考价值。
短文本的相似度计算方法可以分为两大类:基于深度学习的方法和基于非深度学习的方法。科研方面基本都是从深度学习方面入手,但个人觉得想把单语言的短文本相似度计算给做出花来比较难,相对而言基于深度学习的跨语言相似度计算稍微好点。工程方面多半不用深度学习的方法,主要是获取带标记的语比较难的(除非公司花钱找人标)。下面我将结合自己做过的相似度计算的任务,从深度学习和非深度学习两个角度说一下文本相似度计算。
首先来说一下基于深度学习的文本相似度计算。在开始表演之前请允许我说一下故事背景。我们要做一个网络查询推荐,即类似于图1一样:用户输入查询内容,网页给出一些合理的推荐(这些推荐可以是之前网站日志记录下的之前用户的查询信息)。为了从日志之中选出与用户查询内容最贴切的推荐返回给用户,我们需要计算用户输入的查询内容q和候选推荐S(S={s1,s2,s3……,sn})的相似度,并根据相似度返回对应的推荐给用户。
图1 百度搜索框中的查询推荐
在上述任务中,我们利用Siamese Network(见图2)计算文本相似度。考虑到候选推荐S会比较大且真实的语料比较短,我们使用CNN做Siamese Network的基本机构,这样我们在提高速度的同时也能保证性能。使用CNN的一个好处就是我们可以很好地共享两个CNN的参数,为此,我们比较了三种情况下模型性能结果。一种是两个CNN不共享参数;另种是两个CNN共享部分参数;最后一种是两个CNN全部共享参数。实验的结果显示,在同一种语言(查询和推荐的属于同一种语言)的情况下,两个CNN共享的参数越多模型的性能越好,在不同语言(查询和推荐属于不同的语言)的情况下两个CNN共享的参数越多模型的性能越差。
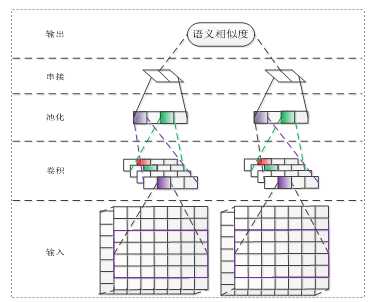
图2 Siamese Network
比较二者差异的主要由查询语言和候选推荐语言是否一致造成的。当两者一致时,用语习惯相同,使用一套参数能更好的拟合他们的分布;但当两者不一致时,二者的语言环境差异很大,用一套参数很难同时模型二者的分布。使用CNN做相似度计算还是很难获得句子整体的语义信息,使用膨胀CNN(IDCNN)做Siamese Network的基本单元效果应该会更好。另外把两个句子任意两个词语的相似度组成的矩阵当成是图片处理也可以很好地适用于查询推荐的,且听NLPCC会议上的老师介绍,在数据较少的情况下这种方法更加实用。
非深度学习的文本相似计算方法也有很多,主要有基于词汇的,基于句型结构的,基于词向量的。我们这里主要介绍基于句子词向量加权和的句子相似度计算。不管是深度学习还是非深度学习,相似度计算的一个难点就是如何合理的表示句子,非深度学习方法在句子的向量化表示过程中主要有SVM(空间向量模型)以及句子词向量的相加。前者会存在数据稀疏,句子表示过长等问题。所以我们直接使用了词向量的加权和表示句子,这里的权重分配主要看这个词是不是关键词(jieba,pynlpir都可以直接计算)。
将句子表示为词向量的加权和,然后计算句子相似度的方法相较于深度学习方法有不少优点:一个是不需要花费大量的人力和物力,一个是适用性比较强(毕竟不像深度学习训练出来的模型,换一个测试集性能就会有很大的差异)。但是其本身也存在问题,主要是性能没有深度学习方法的好。句子词向量的简单相加基本没有涉及句子句型、语法,结构等。这样的结果难以包含句字的整体语义信息,且在句子的分词过程中可能存在的错误(感觉影响特别大)会繁衍到下游的相似度计算。分词的结果和已有的词向量(网上下载的)不匹配也会对结果造成影响。
综上,文本相似度的计算还是由不少难点需要我们去克服的,这些难点往往涉及底层的NLP知识,感觉任重而道远。
以上是关于短文本相似度计算的主要内容,如果未能解决你的问题,请参考以下文章