文本相似度算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本相似度算法相关的知识,希望对你有一定的参考价值。
参考技术A TF是指归一化后的词频,IDF是指逆文档频率。给定一个文档集合D,有d1,d2,d3,......,dn∈D。文档集合总共包含m个词(注:一般在计算TF−IDF时会去除如“的”这一类的停用词),有w1,w2,w3,......,wm∈W。我们现在以计算词wi在文档dj中的TF−IDF指为例。
TF的计算公式为:
TF=freq(i,j) / maxlen(j)
在这里freq(i,j) 为wi在dj中出现的频率,maxlen(j)为dj长度。
TF只能时描述词在文档中的频率,但假设现在有个词为”我们“,这个词可能在文档集D中每篇文档中都会出现,并且有较高的频率。那么这一类词就不具有很好的区分文档的能力,为了降低这种通用词的作用,引入了IDF。
IDF的表达式如下:
IDF=log(len(D) / n(i))
在这里len(D)表示文档集合D中文档的总数,n(i)表示含有wi这个词的文档的数量。
得到TF和IDF之后,我们将这两个值相乘得到TF−IDF的值:
TF−IDF=TF∗IDF
TF可以计算在一篇文档中词出现的频率,而IDF可以降低一些通用词的作用。因此对于一篇文档我们可以用文档中每个词的TF−IDF组成的向量来表示该文档,再根据余弦相似度这类的方法来计算文档之间的相关性。
BM25算法通常用来做搜索相关性评分的,也是ES中的搜索算法,通常用来计算query和文本集合D中每篇文本之间的相关性。我们用Q表示query,在这里Q一般是一个句子。在这里我们要对Q进行语素解析(一般是分词),在这里以分词为例,我们对Q进行分词,得到q1,q2,......,qt这样一个词序列。给定文本d∈D,现在以计算Q和d之间的分数(相关性),其表达式如下:
Score(Q,d)=∑ti=1wi∗R(qi,d)
上面式子中wi表示qi的权重,R(qi,d)为qi和d的相关性,Score(Q,d)就是每个语素qi和d的相关性的加权和。
wi的计算方法有很多,一般是用IDF来表示的,但这里的IDF计算和上面的有所不同,具体的表达式如下:
wi=IDF(qi)=logN−n(qi)+0.5n(qi)+0.5
上面式子中N表示文本集合中文本的总数量,n(qi)表示包含qi这个词的文本的数量,0.5主要是做平滑处理。
R(qi,d)的计算公式如下:
R(qi,d)=fi∗(k1+1)fi+K∗qfi∗(k2+1)qfi+k2
其中
K=k1∗(1−b+b∗dlavgdl)
上面式子中fi为qi在文本d中出现的频率,qfi为qi在Q中出现的频率,k1,k2,b都是可调节的参数,dl,avgdl分别为文本d的长度和文本集D中所有文本的平均长度。
一般qfi=1,取k2=0,则可以去除后一项,将上面式子改写成:
R(qi,d)=fi∗(k1+1)fi+K
通常设置k1=2,b=0.75。参数b的作用主要是调节文本长度对相关性的影响。
Python 文本相似度分析
- 环境
Anaconda3 Python 3.6, Window 64bit
- 目的
利用 jieba 进行分词,关键词提取
利用gensim下面的corpora,models,similarities 进行语料库建立,模型tfidf算法,稀疏矩阵相似度分析
- 代码


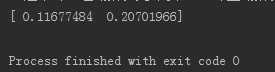
# -*- coding: utf-8 -*- import jieba from gensim import corpora, models, similarities from collections import defaultdict # 定义文件目录 work_dir = "D:/workspace/PythonSdy/data" f1 = work_dir + "/t1.txt" f2 = work_dir + "/t2.txt" # 读取文件内容 c1 = open(f1, encoding=‘utf-8‘).read() c2 = open(f2, encoding=‘utf-8‘).read() # jieba 进行分词 data1 = jieba.cut(c1) data2 = jieba.cut(c2) data11 = "" # 获取分词内容 for i in data1: data11 += i + " " data21 = "" # 获取分词内容 for i in data2: data21 += i + " " doc1 = [data11, data21] # print(doc1) t1 = [[word for word in doc.split()] for doc in doc1] # print(t1) # # frequence频率 freq = defaultdict(int) for i in t1: for j in i: freq[j] += 1 # print(freq) # 限制词频 t2 = [[token for token in k if freq[j] >= 3] for k in t1] print(t2) # corpora语料库建立字典 dic1 = corpora.Dictionary(t2) dic1.save(work_dir + "/yuliaoku.txt") # 对比文件 f3 = work_dir + "/t3.txt" c3 = open(f3, encoding=‘utf-8‘).read() # jieba 进行分词 data3 = jieba.cut(c3) data31 = "" for i in data3: data31 += i + " " new_doc = data31 print(new_doc) # doc2bow把文件变成一个稀疏向量 new_vec = dic1.doc2bow(new_doc.split()) # 对字典进行doc2bow处理,得到新语料库 new_corpor = [dic1.doc2bow(t3) for t3 in t2] tfidf = models.TfidfModel(new_corpor) # 特征数 featurenum = len(dic1.token2id.keys()) # similarities 相似之处 # SparseMatrixSimilarity 稀疏矩阵相似度 idx = similarities.SparseMatrixSimilarity(tfidf[new_corpor], num_features=featurenum) sims = idx[tfidf[new_vec]] print(sims)
- 结果展示
从结果可以得出:被对比的文件3 和文件2内容更相近。
以上是关于文本相似度算法的主要内容,如果未能解决你的问题,请参考以下文章