word2vec词向量训练及中文文本相似度计算
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了word2vec词向量训练及中文文本相似度计算相关的知识,希望对你有一定的参考价值。
本文是讲述如何使用word2vec的基础教程,文章比较基础,希望对你有所帮助!官网C语言下载地址: http://word2vec.googlecode.com/svn/trunk/
官网Python下载地址: http://radimrehurek.com/gensim/models/word2vec.html
1.简单介绍
参考:《Word2vec的核心架构及其应用 · 熊富林,邓怡豪,唐晓晟 · 北邮2015年》
《Word2vec的工作原理及应用探究 · 周练 · 西安电子科技大学2014年》
《Word2vec对中文词进行聚类的研究 · 郑文超,徐鹏 · 北京邮电大学2013年》
PS:第一部分主要是给大家引入基础内容作铺垫,这类文章很多,希望大家自己去学习更多更好的基础内容,这篇博客主要是介绍Word2Vec对中文文本的用法。
(1) 统计语言模型
统计语言模型的一般形式是给定已知的一组词,求解下一个词的条件概率。形式如下:
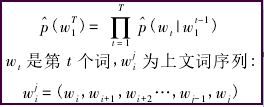
以上是关于word2vec词向量训练及中文文本相似度计算的主要内容,如果未能解决你的问题,请参考以下文章