读SQL进阶教程笔记11_关系数据库基础
Posted 躺柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读SQL进阶教程笔记11_关系数据库基础相关的知识,希望对你有一定的参考价值。
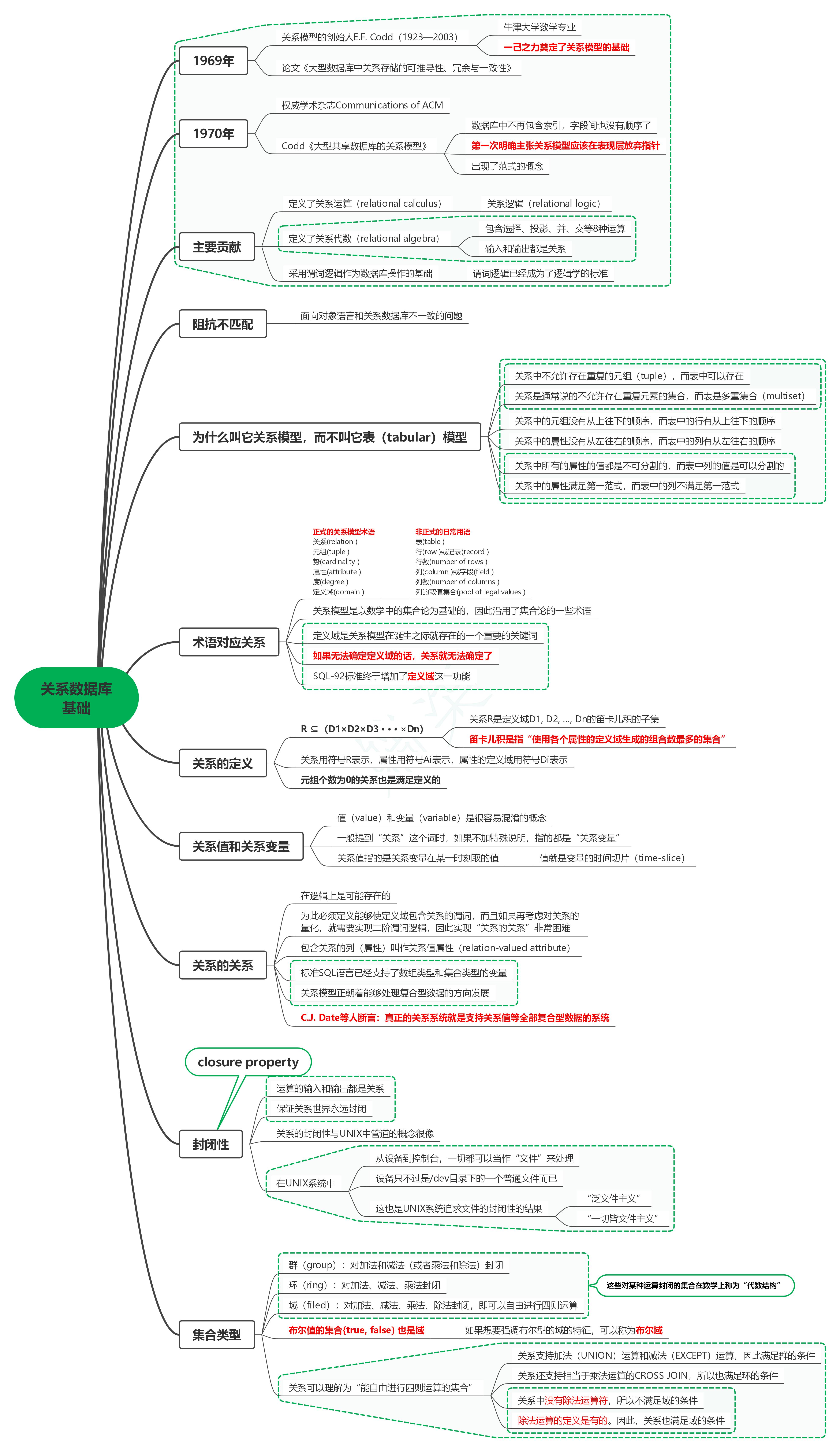
1. 1969年
1.1. 关系模型的创始人E.F. Codd(1923—2003)
1.1.1. 牛津大学数学专业
1.1.2. 一己之力奠定了关系模型的基础
1.2. 论文《大型数据库中关系存储的可推导性、冗余与一致性》
2. 1970年
2.1. 权威学术杂志Communications of ACM
2.2. Codd《大型共享数据库的关系模型》
2.2.1. 数据库中不再包含索引,字段间也没有顺序了
2.2.2. 第一次明确主张关系模型应该在表现层放弃指针
2.2.3. 出现了范式的概念
3. 主要贡献
3.1. 定义了关系运算(relational calculus)
3.1.1. 关系逻辑(relational logic)
3.2. 定义了关系代数(relational algebra)
3.2.1. 包含选择、投影、并、交等8种运算
3.2.2. 输入和输出都是关系
3.3. 采用谓词逻辑作为数据库操作的基础
3.3.1. 谓词逻辑已经成为了逻辑学的标准
4. 阻抗不匹配
4.1. 面向对象语言和关系数据库不一致的问题
5. 为什么叫它关系模型,而不叫它表(tabular)模型
5.1. 关系中不允许存在重复的元组(tuple),而表中可以存在
5.2. 关系是通常说的不允许存在重复元素的集合,而表是多重集合(multiset)
5.3. 关系中的元组没有从上往下的顺序,而表中的行有从上往下的顺序
5.4. 关系中的属性没有从左往右的顺序,而表中的列有从左往右的顺序
5.5. 关系中所有的属性的值都是不可分割的,而表中列的值是可以分割的
5.6. 关系中的属性满足第一范式,而表中的列不满足第一范式
6. 术语对应关系
| 正式的关系模型术语 | 非正式的日常用语 |
| 关系(relation ) | 表(table ) |
| 元组(tuple ) | 行(row )或记录(record ) |
| 势(cardinality ) | 行数(number of rows ) |
| 属性(attribute ) | 列(column )或字段(field ) |
| 度(degree ) | 列数(number of columns ) |
| 定义域(domain ) | 列的取值集合(pool of legal values ) |
6.2. 关系模型是以数学中的集合论为基础的,因此沿用了集合论的一些术语
6.3. 定义域是关系模型在诞生之际就存在的一个重要的关键词
6.4. 如果无法确定定义域的话,关系就无法确定了
6.5. SQL-92标准终于增加了定义域这一功能
7. 关系的定义
7.1. R ⊆(D1×D2×D3 · · · ×Dn)
7.1.1. 关系R是定义域D1, D2, …, Dn的笛卡儿积的子集
7.1.2. 笛卡儿积是指“使用各个属性的定义域生成的组合数最多的集合”
7.2. 关系用符号R表示,属性用符号Ai表示,属性的定义域用符号Di表示
7.3. 元组个数为0的关系也是满足定义的
8. 关系值和关系变量
8.1. 值(value)和变量(variable)是很容易混淆的概念
8.2. 一般提到“关系”这个词时,如果不加特殊说明,指的都是“关系变量”
8.3. 关系值指的是关系变量在某一时刻取的值
8.3.1. 值就是变量的时间切片(time-slice)
9. 关系的关系
9.1. 在逻辑上是可能存在的
9.2. 为此必须定义能够使定义域包含关系的谓词,而且如果再考虑对关系的量化,就需要实现二阶谓词逻辑,因此实现“关系的关系”非常困难
9.3. 包含关系的列(属性)叫作关系值属性(relation-valued attribute)
9.4. 标准SQL语言已经支持了数组类型和集合类型的变量
9.5. 关系模型正朝着能够处理复合型数据的方向发展
9.6. C.J. Date等人断言:真正的关系系统就是支持关系值等全部复合型数据的系统
10. 封闭性
10.1. closure property
10.2. 运算的输入和输出都是关系
10.3. 保证关系世界永远封闭
10.4. 关系的封闭性与UNIX中管道的概念很像
10.5. 在UNIX系统中
10.5.1. 从设备到控制台,一切都可以当作“文件”来处理
10.5.2. 设备只不过是/dev目录下的一个普通文件而已
10.5.3. 这也是UNIX系统追求文件的封闭性的结果
10.5.3.1. “泛文件主义”
10.5.3.2. “一切皆文件主义”
11. 集合类型
11.1. 群(group):对加法和减法(或者乘法和除法)封闭
11.2. 环(ring):对加法、减法、乘法封闭
11.3. 域(filed):对加法、减法、乘法、除法封闭,即可以自由进行四则运算
11.4. 这些对某种运算封闭的集合在数学上称为“代数结构”
11.5. 布尔值的集合true, false 也是域
11.5.1. 如果想要强调布尔型的域的特征,可以称为布尔域
11.6. 关系可以理解为“能自由进行四则运算的集合”
11.6.1. 关系支持加法(UNION)运算和减法(EXCEPT)运算,因此满足群的条件
11.6.2. 关系还支持相当于乘法运算的CROSS JOIN,所以也满足环的条件
11.6.3. 关系中没有除法运算符,所以不满足域的条件
11.6.4. 除法运算的定义是有的。因此,关系也满足域的条件
读SQL进阶教程笔记04_集合运算
1. 集合论是SQL语言的根基
1.1. UNION
- 1.1.1. SQL-86标准
1.2. NTERSECT和EXCEPT
- 1.2.1. SQL-92标准
1.3. 除法运算(DIVIDE BY)
- 1.3.1. 没有被标准化
2. 注意事项
2.1. SQL能操作具有重复行的集合,可以通过可选项ALL来支持
-
2.1.1. 不允许重复
-
2.1.1.1. 直接使用UNION或INTERSECT
-
2.1.1.2. 集合运算符为了排除掉重复行,默认地会发生排序
-
-
2.1.2. 允许重复
-
2.1.2.1. 加上可选项ALL
2.1.2.1.1. 不会再排序,所以性能会有提升
2.1.2.1.2. 非常有效的用于优化查询性能的方法
-
2.1.2.2. UNION ALL
2.1.2.2.1. 不具有幂等性
-
2.2. 集合运算符有优先级
-
2.2.1. INTERSECT比UNION和EXCEPT优先级更高
-
2.2.2. 括号明确地指定运算顺序
2.3. 各个DBMS提供商在集合运算的实现程度上参差不齐
-
2.3.1. SQL Server从2005版开始支持INTERSECT和EXCEPT
-
2.3.2. Oracle这样,实现了EXCEPT功能但却命名为MINUS的数据库
-
2.3.3. INTERSECT和EXCEPT不能在MySQL里执行
2.4. 除法运算没有标准定义
- 2.4.1. 四则运算里的和(UNION)、差(EXCEPT)、积(CROSS JOIN)都被引入了标准SQL
3. 检查集合相等性
3.1. “相等”指的是行数和列数以及内容都相同
3.2. “是同一个集合”
3.3. 原理1
-
3.3.1. S UNION S = S
-
3.3.2. 幂等性(indempotency)
-
3.3.2.1. 抽象代数里群论等理论中的概念
-
3.3.2.2. 二目运算符对任意S,都有SS = S成立”
-
3.4. 示例1
- 3.4.1.
SELECT COUNT(*) AS row_cnt
FROM ( SELECT *
FROM tbl_A
UNION
SELECT *
FROM tbl_B ) TMP;
-
3.4.2. 这个查询的结果与tbl_A及tbl_B的行数一致,则两张表是相等的
-
3.4.3. 表tbl_A和表tbl_B的行数是一样的
- 3.4.3.1. 如果行数不一样,那就不需要比较其他的了
3.5. 原理2
-
3.5.1. 如果A UNION B = A INTERSECT B,则集合A和集合B相等
-
3.5.2. (A UNION B) EXCEPT (A INTERSECT B)的结果集是不是空集就可以了
-
3.5.3. INTERSECT
- 3.5.3.1. 幂等性(indempotency)
-
3.5.4. EXCEPT不具有幂等性
3.6. 示例2
- 3.6.1. --两张表相等时返回“相等”,否则返回“不相等”
SELECT CASE WHEN COUNT(*) = 0
THEN ’相等’
ELSE’不相等’END AS result
FROM ((SELECT * FROM tbl_A
UNION
SELECT * FROM tbl_B)
EXCEPT
(SELECT * FROM tbl_A
INTERSECT
SELECT * FROM tbl_B)) TMP;
-
3.6.2. 改进版不需要事先查询两张表的行数
-
3.6.3. 需要进行4次排序(3次集合运算加上1次DISTINCT)
- 3.6.3.1. 性能会有所下降
3.7. 示例3
- 3.7.1. --用于比较表与表的diff
(SELECT * FROM tbl_A
EXCEPT
SELECT * FROM tbl_B)
UNION ALL
(SELECT * FROM tbl_B
EXCEPT
SELECT * FROM tbl_A);
4. 用差集实现关系除法运算
4.1. 嵌套使用NOT EXISTS
4.2. 使用HAVING子句转换成一对一关系
4.3. 把除法变成减法
-
4.3.1. 示例
- 4.3.1.1.

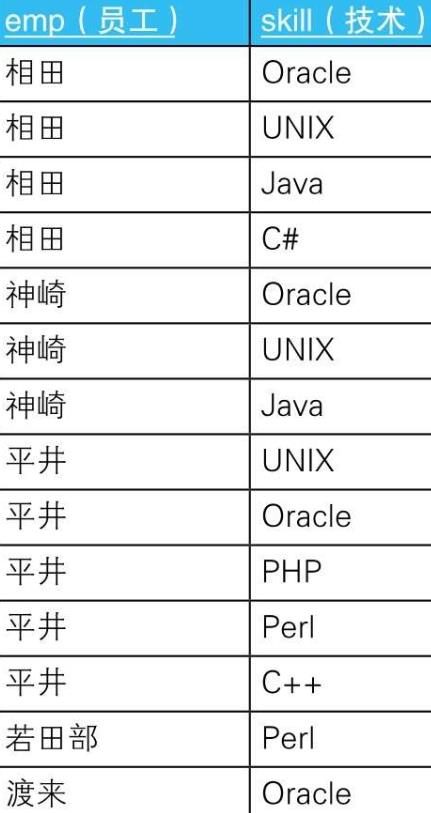
- 4.3.1.2. --用求差集的方法进行关系除法运算(有余数)
SELECT DISTINCT emp
FROM EmpSkills ES1
WHERE NOT EXISTS
(SELECT skill
FROM Skills
EXCEPT
SELECT skill
FROM EmpSkills ES2
WHERE ES1.emp = ES2.emp);
- 4.3.1.3. 关联子查询是为了使SQL能够实现类似面向过程语言中循环的功能而引入的
5. 寻找相等的子集
5.1. IBM过去研制的第一个关系数据库实验系统——System R
-
5.1.1. 用CONTAINS这一谓词来检查集合间的包含关系
-
5.1.2. 后来因为性能原因被删除掉了,直到现在也没有恢复
-
5.1.3.
SELECT \'A CONTAINS B\'
FROM SupParts
WHERE (SELECT part
FROM SupParts
WHERE sup =\'A\')
CONTAINS
(SELECT part
FROM SupParts
WHERE sup =\'B\')
5.2. 示例
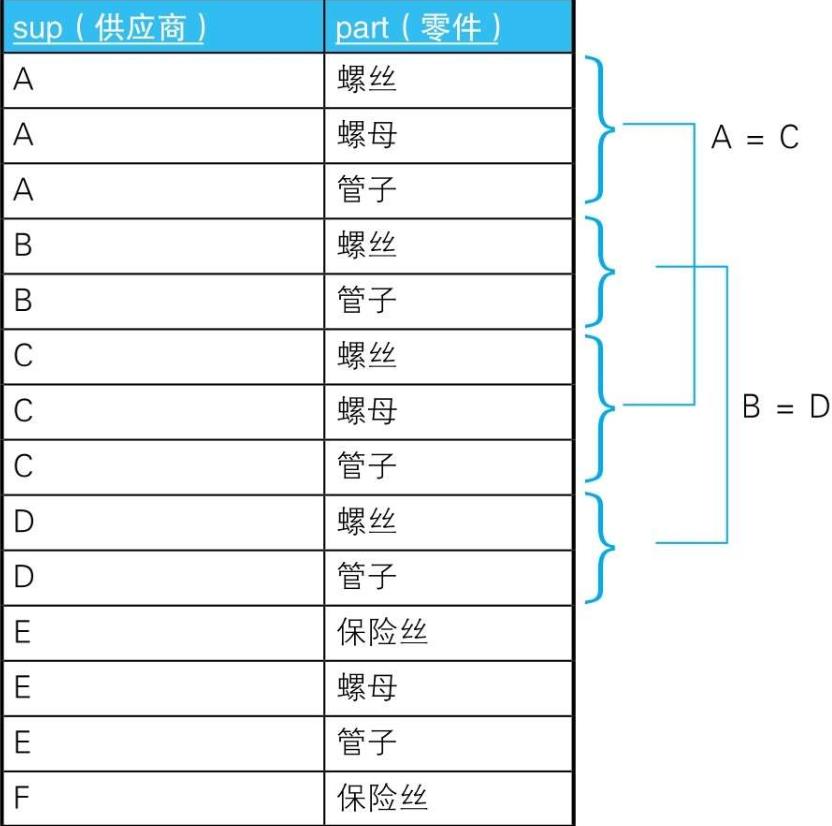
- 5.2.1. --生成供应商的全部组合
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup
GROUP BY SP1.sup, SP2.sup;
- 5.2.2.
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup --生成供应商的全部组合
AND SP1.part = SP2.part --条件1:经营同种类型的零件
GROUP BY SP1.sup, SP2.sup
HAVING COUNT(*) = (SELECT COUNT(*) --条件2:经营的零件种类数相同
FROM SupParts SP3
WHERE SP3.sup = SP1.sup)
AND COUNT(*) = (SELECT COUNT(*)
FROM SupParts SP4
WHERE SP4.sup = SP2.sup);
- 5.2.3. SQL在比较两个集合时,并不是以行为单位来比较的,而是把集合当作整体来处理的
6. 用于删除重复行的高效SQL
6.1. --删除重复行:使用关联子查询
DELETE FROM Products
WHERE rowid < ( SELECT MAX(P2.rowid)
FROM Products P2
WHERE Products.name = P2. name
AND Products.price = P2.price ) ;
6.2. --用于删除重复行的高效SQL语句(1):通过EXCEPT求补集
DELETE FROM Products
WHERE rowid IN ( SELECT rowid --全部rowid
FROM Products
EXCEPT --减去
SELECT MAX(rowid) --要留下的rowid
FROM Products
GROUP BY name, price) ;
6.3. --删除重复行的高效SQL语句(2):通过NOT IN求补集
DELETE FROM Products
WHERE rowid NOT IN ( SELECT MAX(rowid)
FROM Products
GROUP BY name, price);
- 6.3.1. 不支持EXCEPT的数据库也可以使用
6.4. 实现了行ID的数据库只有Oracle和PostgreSQL
-
6.4.1. PostgreSQL里的相应名字是oid,如果要使用,需要事先在CREATE TABLE的时候指定可选项WITH OIDS
-
6.4.2. 如果其他数据库想要使用这些SQL,则需要在表中创建类似的具有唯一性的“id”列
以上是关于读SQL进阶教程笔记11_关系数据库基础的主要内容,如果未能解决你的问题,请参考以下文章