读SQL进阶教程笔记07_EXISTS谓词
Posted 躺柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读SQL进阶教程笔记07_EXISTS谓词相关的知识,希望对你有一定的参考价值。
1. 特点
1.1. 将多行数据作为整体来表达高级的条件
1.2. 使用关联子查询时性能仍然非常好
1.3. EXISTS的参数不像是单一值
1.3.1. 参数是行数据的集合
2. 什么是谓词
2.1. 一种特殊的函数,返回值是真值
2.2. 返回值都是true、false或者unknown
2.2.1. 一般的谓词逻辑里没有unknown
2.2.2. SQL采用的是三值逻辑,因此具有三种真值
2.3. 谓词逻辑提供谓词是为了判断命题(可以理解成陈述句)的真假
2.3.1. 为命题分析提供了函数式的方法
2.4. 只有能让WHERE子句的返回值为真的命题,才能从表(命题的集合)中查询到
3. 谓词的阶
3.1. 阶(order)是用来区分集合或谓词的阶数的概念
3.2. 一阶谓词
3.2.1. =或者BETWEEEN等输入值为一行的谓词
3.3. 二阶谓词
3.3.1. EXISTS这样输入值为行的集合的谓词
3.3.2. 谓词也是函数的一种,因此我们也可以说EXISTS是高阶函数
3.4. 三阶谓词
3.4.1. 输入值为“集合的集合”的谓词
3.5. 四阶谓词
3.5.1. 输入值为“集合的集合的集合”的谓词
3.6. SQL里并不会出现三阶以上的情况
4. SELECT子句的列表
4.1. 通配符:SELECT *
4.2. 常量:SELECT ‘这里的内容任意’
4.3. 列名:SELECT col
5. 全称量化和存在量化
5.1. 形式语言没必要同时显式地支持EXISTS和FORALL两者
5.1.1. 因为全称量词和存在量词只要定义了一个,另一个就可以被推导出来
5.1.2. ∀ xPx = ¬ ∃ x¬P
5.1.3. 所有的x都满足条件P=不存在不满足条件P的x
5.1.4. ∃ xPx = ¬ ∀ x¬Px
5.1.5. 存在x满足条件P=并非所有的x都不满足条件P
5.2. SQL支持EXISTS,不支持FORALL
5.2.1. SQL中没有与全称量词相当的谓词,可以使用NOT EXISTS代替
5.3. 全称量词
5.3.1. 所有的x都满足条件P
5.4. 存在量词
5.4.1. 存在(至少一个)满足条件P的x
6. 查询表中“不”存在的数据
6.1. 示例
6.1.1.

6.1.1.1.
SELECT DISTINCT M1.meeting, M2.person
FROM Meetings M1 CROSS JOIN Meetings M2;
6.1.1.2. 所有人都参加了全部会议时
6.1.1.3. --求出缺席者的SQL语句(1):存在量化的应用
SELECT DISTINCT M1.meeting, M2.person
FROM Meetings M1 CROSS JOIN Meetings M2
WHERE NOT EXISTS
(SELECT *
FROM Meetings M3
WHERE M1.meeting = M3.meeting
AND M2.person = M3.person);
6.1.1.3.1. ----求出缺席者的SQL语句(2):使用差集运算
SELECT M1.meeting, M2.person
FROM Meetings M1, Meetings M2
EXCEPT
SELECT meeting, person
FROM Meetings;
6.1.1.3.2. NOT EXISTS直接具备了差集运算的功能
7. “肯定⇔双重否定”之间的转换
7.1. 示例
7.1.1.

7.1.2. 所有科目分数都在50分以上
7.1.2.1. 没有一个科目分数不满50分
7.1.3.
SELECT DISTINCT student_id
FROM TestScores TS1
WHERE NOT EXISTS --不存在满足以下条件的行
(SELECT *
FROM TestScores TS2
WHERE TS2.student_id = TS1.student_id
AND TS2.score < 50); --分数不满50分的科目
7.1.4. 某个学生的所有行数据中,如果科目是数学,则分数在80分以上;如果科目是语文,则分数在50分以上。
7.1.4.1.
SELECT DISTINCT student_id
FROM TestScores TS1
WHERE subject IN (’数学’, ’语文’)
AND NOT EXISTS
(SELECT *
FROM TestScores TS2
WHERE TS2.student_id = TS1.student_id
AND 1 = CASE WHEN subject =’数学’AND score < 80 THEN 1
WHEN subject =’语文’AND score < 50 THEN 1
ELSE 0 END);
7.1.4.1.1.
SELECT student_id
FROM TestScores TS1
WHERE subject IN (’数学’, ’语文’)
AND NOT EXISTS
(SELECT *
FROM TestScores TS2
WHERE TS2.student_id = TS1.student_id
AND 1 = CASE WHEN subject =’数学’AND score < 80 THEN 1
WHEN subject =’语文’AND score < 50 THEN 1
ELSE 0 END)
GROUP BY student_id
HAVING COUNT(*) = 2; --必须两门科目都有分数
7.1.4.1.2. EXISTS和HAVING有一个地方很像,即都是以集合而不是个体为单位来操作数据
8. 集合VS谓词
8.1. 示例
8.1.1.

8.1.2. 查询出哪些项目已经完成到了工程1
8.1.2.1. --查询完成到了工程1的项目:面向集合的解法
SELECT project_id
FROM Projects
GROUP BY project_id
HAVING COUNT(*) = SUM(CASE WHEN step_nbr <= 1 AND status =’完成’THEN 1
WHEN step_nbr > 1 AND status =’等待’THEN 1
ELSE 0 END);
8.1.2.1.1. --查询完成到了工程1的项目:谓词逻辑的解法
SELECT *
FROM Projects P1
WHERE NOT EXISTS
(SELECT status
FROM Projects P2
WHERE P1.project_id = P2. project_id --以项目为单位进行条件判断
AND status <> CASE WHEN step_nbr <= 1 --使用双重否定来表达全称量化命题
THEN ’完成’
ELSE ’等待’ END);
8.1.2.1.1.1. 性能好。只要有一行满足条件,查询就会终止
8.1.2.1.1.2. 结果里能包含的信息量更大
9. 对列进行量化
9.1. 示例::查询全是1的行
9.1.1. --“列方向”的全称量化:不优雅的解答
SELECT *
FROM ArrayTbl
WHERE col1 = 1
AND col2 = 1
·
·
·
AND col10 = 1;
9.1.1.1. --“列方向”的全称量化:优雅的解答
SELECT *
FROM ArrayTbl
WHERE 1 = ALL (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);
9.2. 示例:至少有一个9
9.2.1. --列方向的存在量化(1)
SELECT *
FROM ArrayTbl
WHERE 9 = ANY (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);
9.2.1.1. --列方向的存在量化(2)
SELECT *
FROM ArrayTbl
WHERE 9 IN (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);
9.2.1.1.1. 这种写法也是被允许的
9.2.1.1.2. 如果左边不是具体值而是NULL,这种写法就不行了
9.2.2. --查询全是NULL的行:错误的解法
SELECT *
FROM ArrayTbl
WHERE NULL = ALL (col1, col2, col3, col4, col5, col6, col7, col8, col9, col10);
9.2.2.1. --查询全是NULL的行:正确的解法
SELECT *
FROM ArrayTbl
WHERE COALESCE(col1, col2, col3, col4, col5, col6, col7, col8, col9, col10) IS NULL;
10. C.J. Date曾经这样调侃过:数据库这种叫法有点名不副实,它存储的与其说是数据,还不如说是命题
读SQL进阶教程笔记06_外连接

1. SQL的弱点
1.1. SQL语句的执行结果转换为想要的格式
-
1.1.1. 格式转换
-
1.1.2. SQL语言本来就不是为了这个目的而出现的
-
1.1.3. SQL终究也只是主要用于查询数据的语言而已
1.2. 生成报表的功能
- 1.2.1. 窗口函数
1.3. SQL不是用来生成报表的语言,所以不建议用它来进行格式转换
- 1.3.1. 必要时考虑用外连接或CASE表达式来解决问题
2. 制作交叉表(行→列)
2.1. 示例
- 2.1.1.
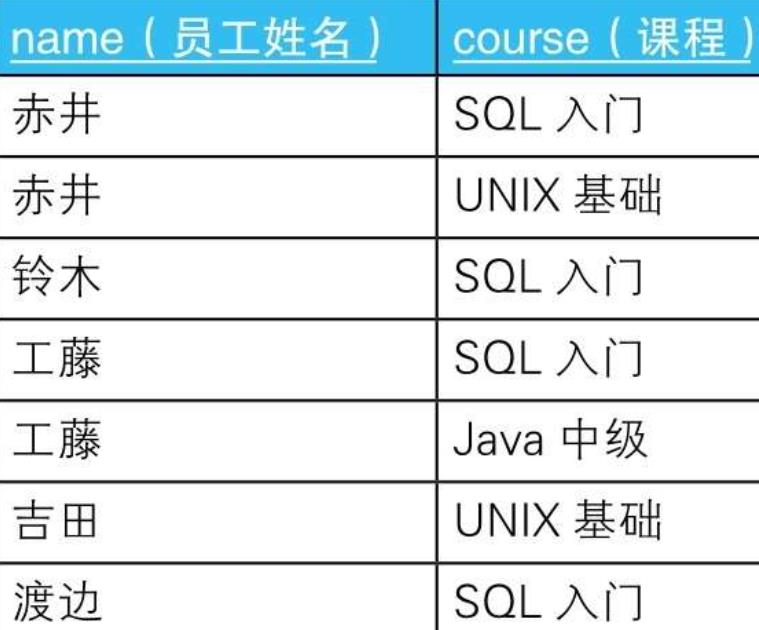
- 2.1.1.1. --水平展开求交叉表(1):使用外连接
SELECT C0.name,
CASE WHEN C1.name IS NOT NULL THEN\'○\'ELSE NULL END AS "SQL入门",
CASE WHEN C2.name IS NOT NULL THEN\'○\'ELSE NULL END AS "UNIX基础",
CASE WHEN C3.name IS NOT NULL THEN\'○\'ELSE NULL END AS "Java中级"
FROM (SELECT DISTINCT name FROM Courses) C0 --这里的C0是侧栏
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = \'SQL入门’) C1
ON C0.name = C1.name
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = \'UNIX基础’) C2
ON C0.name = C2.name
LEFT OUTER JOIN
(SELECT name FROM Courses WHERE course = \'Java中级’) C3
ON C0.name = C3.name;
-
2.1.1.2. 一般情况下,外连接都可以用标量子查询替代
2.1.1.2.1. 需要增加或者减少课程时,只修改SELECT子句即可,代码修改起来比较简单
2.1.1.2.2. 利于应对需求变更,对于需要动态生成SQL的系统也是很有好处的
2.1.1.2.3. 性能不太好
-
2.1.1.3. --水平展开(2):使用标量子查询
SELECT C0.name,
(SELECT \'○\'
FROM Courses C1
WHERE course = \'SQL入门’
AND C1.name = C0.name) AS "SQL入门",
(SELECT \'○\'
FROM Courses C2
WHERE course = \'UNIX基础’
AND C2.name = C0.name) AS "UNIX基础",
(SELECT \'○\'
FROM Courses C3
WHERE course = \'Java中级’
AND C3.name = C0.name) AS "Java中级"
FROM (SELECT DISTINCT name FROM Courses) C0; --这里的C0是表侧栏
-
2.1.1.4. 嵌套使用CASE表达式
2.1.1.4.1. CASE表达式可以写在SELECT子句里的聚合函数内部,也可以写在聚合函数外部
2.1.1.4.2. 其实在SELECT子句里,聚合函数的执行结果也是标量值,因此可以像常量和普通列一样使用
2.1.1.4.3. 和标量子查询的做法一样简洁,也能灵活地应对需求变更
-
2.1.1.5. --水平展开(3):嵌套使用CASE表达式
SELECT name,
CASE WHEN SUM(CASE WHEN course = \'SQL入门’THEN 1 ELSE NULL END) = 1
THEN\'○\'ELSE NULL END AS "SQL入门",
CASE WHEN SUM(CASE WHEN course = \'UNIX基础’THEN 1 ELSE NULL END) = 1
THEN\'○\'ELSE NULL END AS "UNIX基础",
CASE WHEN SUM(CASE WHEN course = \'Java中级’THEN 1 ELSE NULL END) = 1
THEN\'○\'ELSE NULL END AS "Java中级"
FROM Courses
GROUP BY name;
3. 汇总重复项于一列(列→行)
3.1. 示例
- 3.1.1.
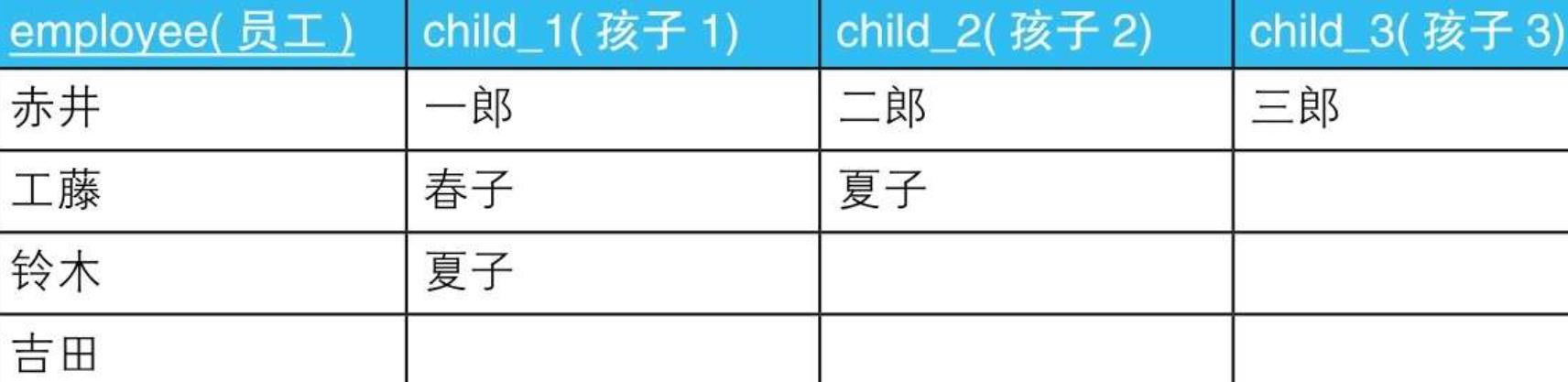
- 3.1.1.1. --列数据转换成行数据:使用UNION ALL
SELECT employee, child_1 AS child FROM Personnel
UNION ALL
SELECT employee, child_2 AS child FROM Personnel
UNION ALL
SELECT employee, child_3 AS child FROM Personnel;
- 3.1.1.2. 视图
CREATE VIEW Children(child)
AS SELECT child_1 FROM Personnel
UNION
SELECT child_2 FROM Personnel
UNION
SELECT child_3 FROM Personnel;
child
-----
一郎
二郎
三郎
春子
夏子
3.1.1.2.1. --获取员工子女列表的SQL语句(没有孩子的员工也要输出)
SELECT EMP.employee, CHILDREN.child
FROM Personnel EMP
LEFT OUTER JOIN Children
ON CHILDREN.child IN (EMP.child_1, EMP.child_2, EMP.child_3);
4. 制作嵌套式表侧栏
4.1. 示例
- 4.1.1.


- 4.1.2.
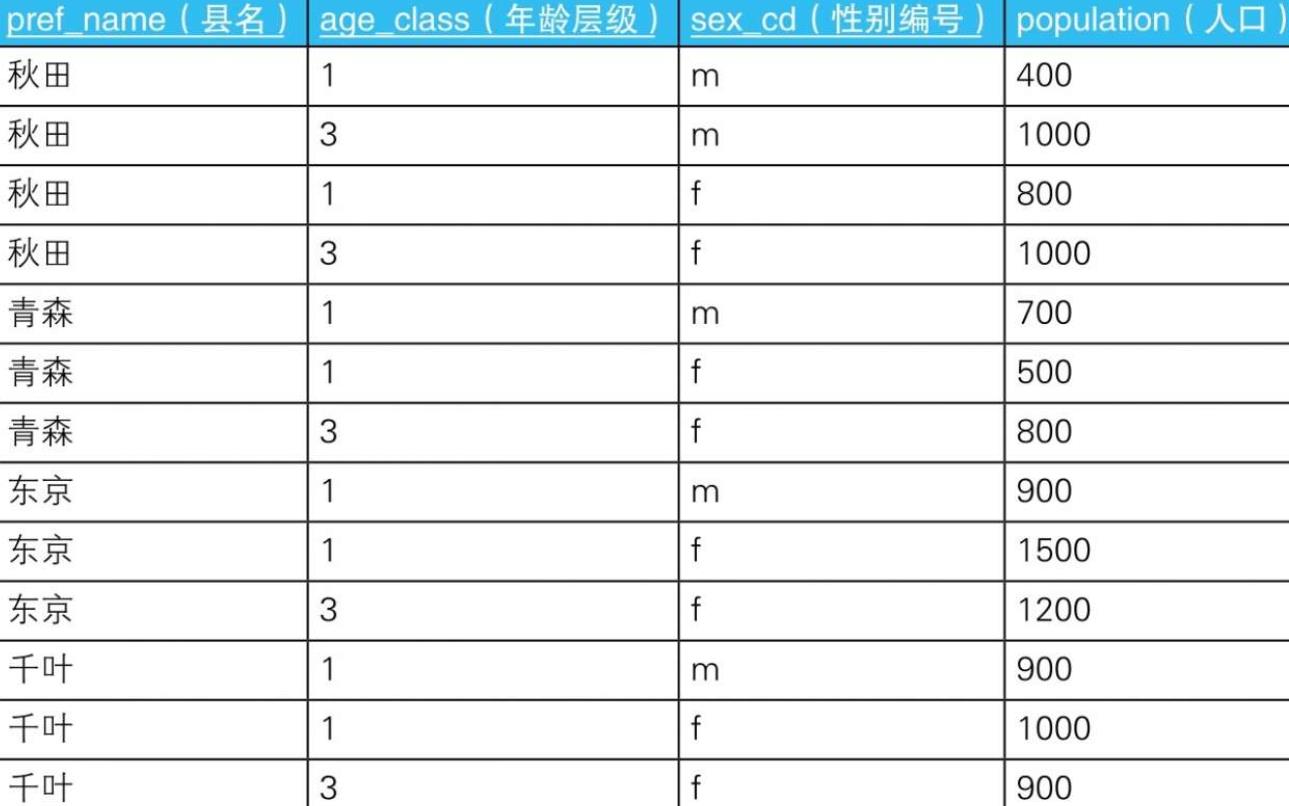
-
4.1.3. 结果
- 4.1.3.1.
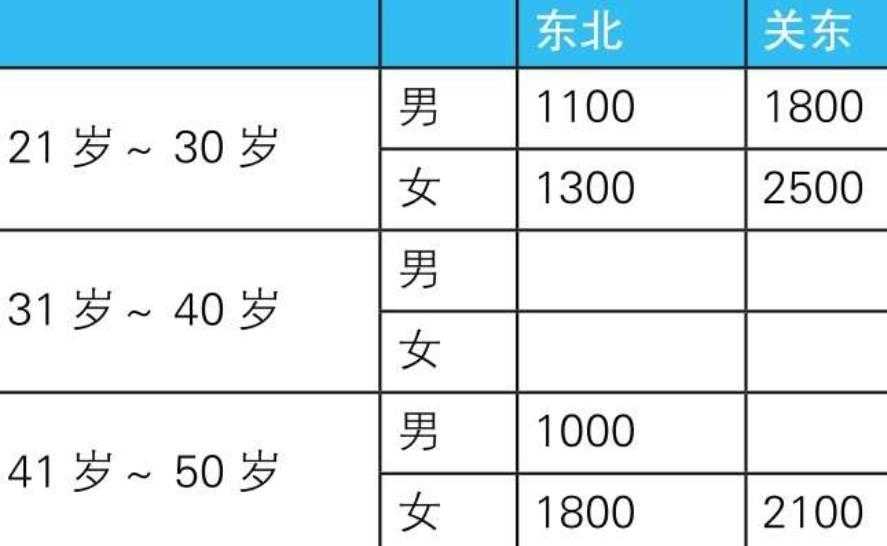
- 4.1.4. --使用外连接生成嵌套式表侧栏:错误的SQL语句
SELECT MASTER1.age_class AS age_class,
MASTER2.sex_cd AS sex_cd,
DATA.pop_tohoku AS pop_tohoku,
DATA.pop_kanto AS pop_kanto
FROM (SELECT age_class, sex_cd,
SUM(CASE WHEN pref_name IN (’青森’, ’秋田’)
THEN population ELSE NULL END) AS pop_tohoku,
SUM(CASE WHEN pref_name IN (’东京’, ’千叶’)
THEN population ELSE NULL END) AS pop_kanto
FROM TblPop
GROUP BY age_class, sex_cd) DATA
RIGHT OUTER JOIN TblAge MASTER1--外连接1:和年龄层级主表进行外连接
ON MASTER1.age_class = DATA.age_class
RIGHT OUTER JOIN TblSex MASTER2--外连接2:和性别主表进行外连接
ON MASTER2.sex_cd = DATA.sex_cd;
- 4.1.4.1. --停在第1个外连接处时:结果里包含年龄层级为2的数据
SELECT MASTER1.age_class AS age_class,
DATA.sex_cd AS sex_cd,
DATA.pop_tohoku AS pop_tohoku,
DATA.pop_kanto AS pop_kanto
FROM (SELECT age_class, sex_cd,
SUM(CASE WHEN pref_name IN (’青森’, ’秋田’)
THEN population ELSE NULL END) AS pop_tohoku,
SUM(CASE WHEN pref_name IN (’东京’, ’千叶’)
THEN population ELSE NULL END) AS pop_kanto
FROM TblPop
GROUP BY age_class, sex_cd) DATA
RIGHT OUTER JOIN TblAge MASTER1
ON MASTER1.age_class = DATA.age_class;
-
4.1.5. 如果不允许进行两次外连接,那么调整成一次就可以了
-
4.1.6. 对于不支持CROSS JOIN语句的数据库,可以像FROM TblAge,TblSex这样不指定连接条件,把需要连接的表写在一起,其效果与交叉连接一样
-
4.1.7. 如果先生成主表的笛卡儿积再进行连接,很容易就可以完成
-
4.1.8. --使用外连接生成嵌套式表侧栏:正确的SQL语句
SELECT MASTER.age_class AS age_class,
MASTER.sex_cd AS sex_cd,
DATA.pop_tohoku AS pop_tohoku,
DATA.pop_kanto AS pop_kanto
FROM (SELECT age_class, sex_cd
FROM TblAge CROSS JOIN TblSex ) MASTER --使用交叉连接生成两张主表的笛卡儿积
LEFT OUTER JOIN
(SELECT age_class, sex_cd,
SUM(CASE WHEN pref_name IN (’青森’, ’秋田’)
THEN population ELSE NULL END) AS pop_tohoku,
SUM(CASE WHEN pref_name IN (’东京’, ’千叶’)
THEN population ELSE NULL END) AS pop_kanto
FROM TblPop
GROUP BY age_class, sex_cd) DATA
ON MASTER.age_class = DATA.age_class
AND MASTER.sex_cd = DATA.sex_cd;
5. 作为乘法运算的连接
5.1. 示例
- 5.1.1.
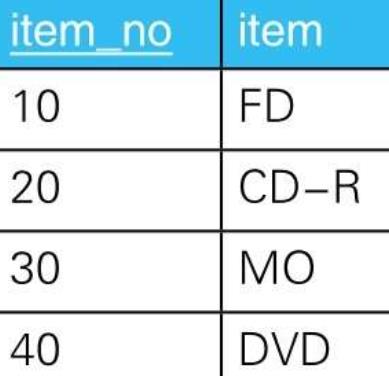
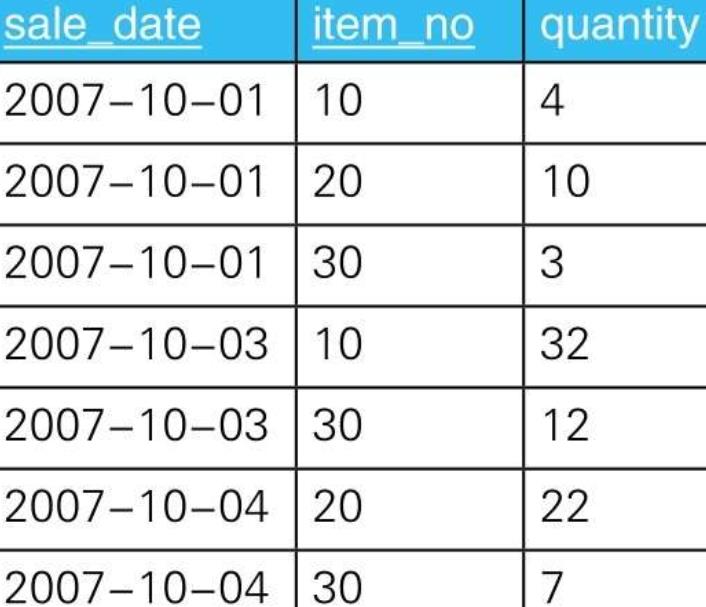
- 5.1.2. --解答(1):通过在连接前聚合来创建一对一的关系
SELECT I.item_no, SH.total_qty
FROM Items I LEFT OUTER JOIN
(SELECT item_no, SUM(quantity) AS total_qty
FROM SalesHistory
GROUP BY item_no) SH
ON I.item_no = SH.item_no;
-
5.1.2.1. 以商品编号为主键的临时视图
-
5.1.2.2. 无法利用索引优化查询
-
5.1.3. --解答(2):先进行一对多的连接再聚合
SELECT I.item_no, SUM(SH.quantity) AS total_qty
FROM Items I LEFT OUTER JOIN SalesHistory SH
ON I.item_no = SH.item_no 一对多的连接
GROUP BY I.item_no;
-
5.1.3.1. 代码更简洁
-
5.1.3.2. 没有使用临时视图,所以性能也会有所改善
5.2. 从行数来看,表连接可以看成乘法。因此,当表之间是一对多的关系时,连接后行数不会增加
6. 全外连接
6.1. FULL OUTER JOIN
6.2. 相当于求集合的和(UNION,也称并集)
- 6.2.1. 内连接相当于求集合的积(INTERSECT,也称交集)
6.3. 示例
- 6.3.1. --全外连接保留全部信息
SELECT COALESCE(A.id, B.id) AS id,
A.name AS A_name,
B.name AS B_name
FROM Class_A A FULL OUTER JOIN Class_B B
ON A.id = B.id;
- 6.3.1.1. --数据库不支持全外连接时的替代方案
SELECT A.id AS id, A.name, B.name
FROM Class_A A LEFT OUTER JOIN Class_B B
ON A.id = B.id
UNION
SELECT B.id AS id, A.name, B.name
FROM Class_A A RIGHT OUTER JOIN Class_B B
ON A.id = B.id;
6.3.1.1.1. 分别进行左外连接和右外连接,再把两个结果通过UNION合并起来
6.4. COALESCE是SQL的标准函数
- 6.4.1. 可以接受多个参数,功能是返回第一个非NULL的参数
6.5. 外连接的思想和集合运算很像,使用外连接可以实现各种集合运算
7. 用外连接求差集:B-A
7.1. 示例
- 7.1.1.
SELECT B.id AS id, B.name AS B_name
FROM Class_A A RIGHT OUTER JOIN Class_B B
ON A.id = B.id
WHERE A.name IS NULL;
7.2. 可以作为NOT IN和NOT EXISTS之外的另一种解法
7.3. 可能是差集运算中效率最高的
8. 用全外连接求异或集
8.1. SQL没有定义求异或集的运算符
8.2. 用集合运算符
-
8.2.1. (A UNION B) EXCEPT (A INTERSECT B)
-
8.2.2. (A EXCEPT B) UNION (B EXCEPT A)
-
8.2.3. 性能开销大
8.3. 示例
- 8.3.1.
SELECT COALESCE(A.id, B.id) AS id,
COALESCE(A.name , B.name ) AS name
FROM Class_A A FULL OUTER JOIN Class_B B
ON A.id = B.id
WHERE A.name IS NULL
OR B.name IS NULL;
9. 用外连接进行关系除法
9.1. 示例
- 9.1.1. --用外连接进行关系除法运算:差集的应用
SELECT DISTINCT shop
FROM ShopItems SI1
WHERE NOT EXISTS
(SELECT I.item
FROM Items I LEFT OUTER JOIN ShopItems SI2
ON I.item = SI2.item
AND SI1.shop = SI2.shop
WHERE SI2.item IS NULL) ;
以上是关于读SQL进阶教程笔记07_EXISTS谓词的主要内容,如果未能解决你的问题,请参考以下文章