读SQL进阶教程笔记04_集合运算
Posted 躺柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读SQL进阶教程笔记04_集合运算相关的知识,希望对你有一定的参考价值。
1. 集合论是SQL语言的根基
1.1. UNION
- 1.1.1. SQL-86标准
1.2. NTERSECT和EXCEPT
- 1.2.1. SQL-92标准
1.3. 除法运算(DIVIDE BY)
- 1.3.1. 没有被标准化
2. 注意事项
2.1. SQL能操作具有重复行的集合,可以通过可选项ALL来支持
-
2.1.1. 不允许重复
-
2.1.1.1. 直接使用UNION或INTERSECT
-
2.1.1.2. 集合运算符为了排除掉重复行,默认地会发生排序
-
-
2.1.2. 允许重复
-
2.1.2.1. 加上可选项ALL
2.1.2.1.1. 不会再排序,所以性能会有提升
2.1.2.1.2. 非常有效的用于优化查询性能的方法
-
2.1.2.2. UNION ALL
2.1.2.2.1. 不具有幂等性
-
2.2. 集合运算符有优先级
-
2.2.1. INTERSECT比UNION和EXCEPT优先级更高
-
2.2.2. 括号明确地指定运算顺序
2.3. 各个DBMS提供商在集合运算的实现程度上参差不齐
-
2.3.1. SQL Server从2005版开始支持INTERSECT和EXCEPT
-
2.3.2. Oracle这样,实现了EXCEPT功能但却命名为MINUS的数据库
-
2.3.3. INTERSECT和EXCEPT不能在MySQL里执行
2.4. 除法运算没有标准定义
- 2.4.1. 四则运算里的和(UNION)、差(EXCEPT)、积(CROSS JOIN)都被引入了标准SQL
3. 检查集合相等性
3.1. “相等”指的是行数和列数以及内容都相同
3.2. “是同一个集合”
3.3. 原理1
-
3.3.1. S UNION S = S
-
3.3.2. 幂等性(indempotency)
-
3.3.2.1. 抽象代数里群论等理论中的概念
-
3.3.2.2. 二目运算符对任意S,都有SS = S成立”
-
3.4. 示例1
- 3.4.1.
SELECT COUNT(*) AS row_cnt
FROM ( SELECT *
FROM tbl_A
UNION
SELECT *
FROM tbl_B ) TMP;
-
3.4.2. 这个查询的结果与tbl_A及tbl_B的行数一致,则两张表是相等的
-
3.4.3. 表tbl_A和表tbl_B的行数是一样的
- 3.4.3.1. 如果行数不一样,那就不需要比较其他的了
3.5. 原理2
-
3.5.1. 如果A UNION B = A INTERSECT B,则集合A和集合B相等
-
3.5.2. (A UNION B) EXCEPT (A INTERSECT B)的结果集是不是空集就可以了
-
3.5.3. INTERSECT
- 3.5.3.1. 幂等性(indempotency)
-
3.5.4. EXCEPT不具有幂等性
3.6. 示例2
- 3.6.1. --两张表相等时返回“相等”,否则返回“不相等”
SELECT CASE WHEN COUNT(*) = 0
THEN ’相等’
ELSE’不相等’END AS result
FROM ((SELECT * FROM tbl_A
UNION
SELECT * FROM tbl_B)
EXCEPT
(SELECT * FROM tbl_A
INTERSECT
SELECT * FROM tbl_B)) TMP;
-
3.6.2. 改进版不需要事先查询两张表的行数
-
3.6.3. 需要进行4次排序(3次集合运算加上1次DISTINCT)
- 3.6.3.1. 性能会有所下降
3.7. 示例3
- 3.7.1. --用于比较表与表的diff
(SELECT * FROM tbl_A
EXCEPT
SELECT * FROM tbl_B)
UNION ALL
(SELECT * FROM tbl_B
EXCEPT
SELECT * FROM tbl_A);
4. 用差集实现关系除法运算
4.1. 嵌套使用NOT EXISTS
4.2. 使用HAVING子句转换成一对一关系
4.3. 把除法变成减法
-
4.3.1. 示例
- 4.3.1.1.

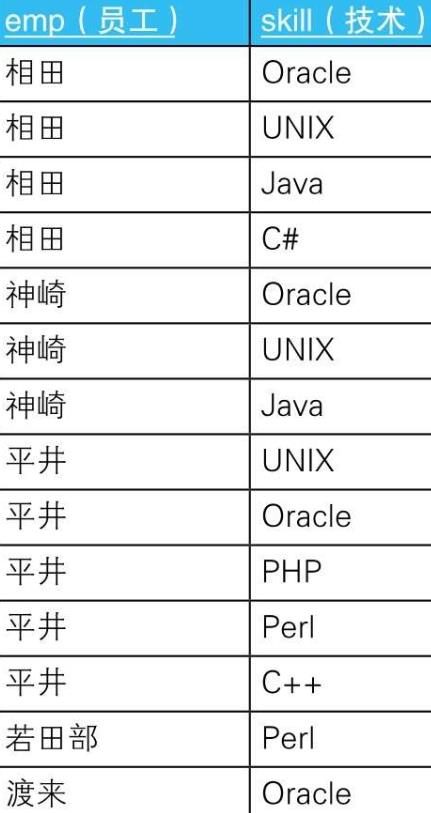
- 4.3.1.2. --用求差集的方法进行关系除法运算(有余数)
SELECT DISTINCT emp
FROM EmpSkills ES1
WHERE NOT EXISTS
(SELECT skill
FROM Skills
EXCEPT
SELECT skill
FROM EmpSkills ES2
WHERE ES1.emp = ES2.emp);
- 4.3.1.3. 关联子查询是为了使SQL能够实现类似面向过程语言中循环的功能而引入的
5. 寻找相等的子集
5.1. IBM过去研制的第一个关系数据库实验系统——System R
-
5.1.1. 用CONTAINS这一谓词来检查集合间的包含关系
-
5.1.2. 后来因为性能原因被删除掉了,直到现在也没有恢复
-
5.1.3.
SELECT \'A CONTAINS B\'
FROM SupParts
WHERE (SELECT part
FROM SupParts
WHERE sup =\'A\')
CONTAINS
(SELECT part
FROM SupParts
WHERE sup =\'B\')
5.2. 示例
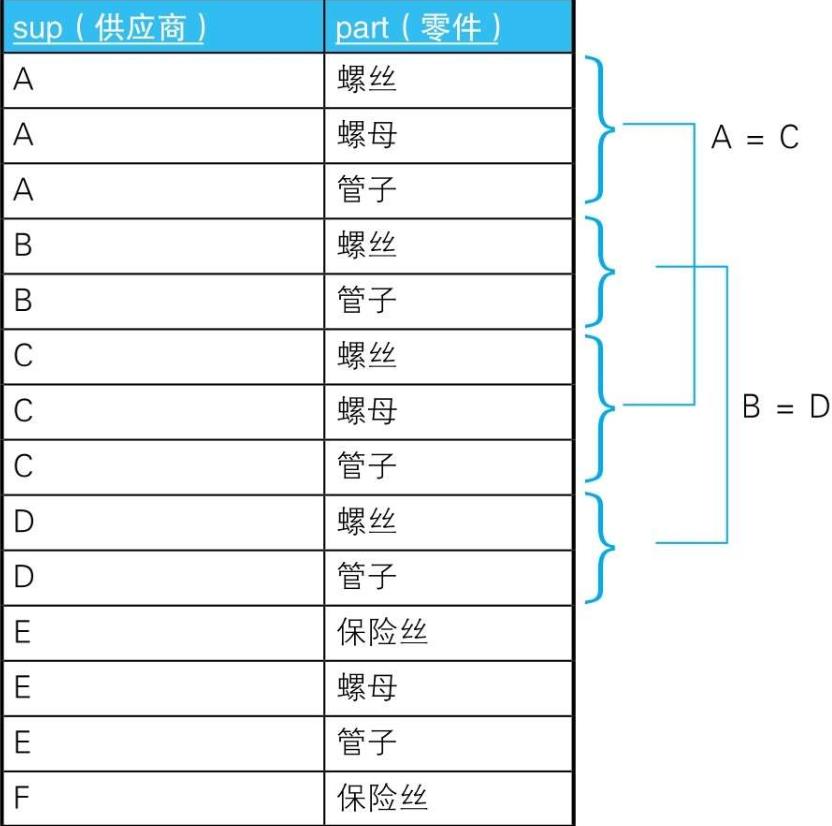
- 5.2.1. --生成供应商的全部组合
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup
GROUP BY SP1.sup, SP2.sup;
- 5.2.2.
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup --生成供应商的全部组合
AND SP1.part = SP2.part --条件1:经营同种类型的零件
GROUP BY SP1.sup, SP2.sup
HAVING COUNT(*) = (SELECT COUNT(*) --条件2:经营的零件种类数相同
FROM SupParts SP3
WHERE SP3.sup = SP1.sup)
AND COUNT(*) = (SELECT COUNT(*)
FROM SupParts SP4
WHERE SP4.sup = SP2.sup);
- 5.2.3. SQL在比较两个集合时,并不是以行为单位来比较的,而是把集合当作整体来处理的
6. 用于删除重复行的高效SQL
6.1. --删除重复行:使用关联子查询
DELETE FROM Products
WHERE rowid < ( SELECT MAX(P2.rowid)
FROM Products P2
WHERE Products.name = P2. name
AND Products.price = P2.price ) ;
6.2. --用于删除重复行的高效SQL语句(1):通过EXCEPT求补集
DELETE FROM Products
WHERE rowid IN ( SELECT rowid --全部rowid
FROM Products
EXCEPT --减去
SELECT MAX(rowid) --要留下的rowid
FROM Products
GROUP BY name, price) ;
6.3. --删除重复行的高效SQL语句(2):通过NOT IN求补集
DELETE FROM Products
WHERE rowid NOT IN ( SELECT MAX(rowid)
FROM Products
GROUP BY name, price);
- 6.3.1. 不支持EXCEPT的数据库也可以使用
6.4. 实现了行ID的数据库只有Oracle和PostgreSQL
-
6.4.1. PostgreSQL里的相应名字是oid,如果要使用,需要事先在CREATE TABLE的时候指定可选项WITH OIDS
-
6.4.2. 如果其他数据库想要使用这些SQL,则需要在表中创建类似的具有唯一性的“id”列
读SQL进阶教程笔记09_HAVING上

1. HAVING子句的用法
1.1. 学习SQL时最大的阻碍就是我们已经习惯了的面向过程语言的思考方式(排序、循环、条件分支、赋值等)
1.2. 只有习惯了面向集合的思考方式,才能真正地学好它
1.3. 帮助我们顺利地忘掉面向过程语言的思考方式并理解SQL面向集合特性的最为有效的方法
1.4. HAVING子句的处理对象是集合而不是记录
1.4.1. 如果一个实体对应着一行数据→那么就是元素,所以使用WHERE子句
1.4.2. 如果一个实体对应着多行数据→那么就是集合,所以使用HAVING子句
1.5. HAVING子句可以通过聚合函数(特别是极值函数)针对集合指定各种条件
1.5.1.

1.5.2. 如果通过CASE表达式生成特征函数,那么无论多么复杂的条件都可以描述
2. 点名
2.1. 示例
2.1.1.

2.1.1.1. -- 用谓词表达全称量化命题
SELECT team_id, member
FROM Teams T1
WHERE NOT EXISTS
(SELECT *
FROM Teams T2
WHERE T1.team_id = T2.team_id
AND status <>’待命’);
2.1.1.1.1. “所有队员都处于待命状态”=“不存在不处于待命状态的队员”
2.1.1.1.2. 查询性能很好
2.1.1.1.3. 结果中能体现出队员信息
2.1.1.2. -- 用集合表达全称量化命题(1)
SELECT team_id
FROM Teams
GROUP BY team_id
HAVING COUNT(*) = SUM(CASE WHEN status =’待命’
THEN 1
ELSE 0 END);
2.1.1.2.1. 代码很简洁
2.1.1.2.2. 使用的是特征函数的方法
2.1.1.3. -- 用集合表达全称量化命题(2)
SELECT team_id
FROM Teams
GROUP BY team_id
HAVING MAX(status) =’待命’
AND MIN(status) =’待命’;
2.1.1.3.1. 性能更好
2.1.1.3.1.1. 极值函数可以使用参数字段的索引
2.1.1.3.2. 如果元素最大值和最小值相等,那么这个集合中肯定只有一种值
2.1.1.4. -- 列表显示各个队伍是否所有队员都在待命
SELECT team_id,
CASE WHEN MAX(status) =’待命’AND MIN(status) =’待命’
THEN ’全都在待命’
ELSE’队长!人手不够’END AS status
FROM Teams
GROUP BY team_id;
2.1.1.4.1. 条件移到SELECT子句后,查询可能就不会被数据库优化了
3. 单重集合
3.1. 示例
3.1.1.
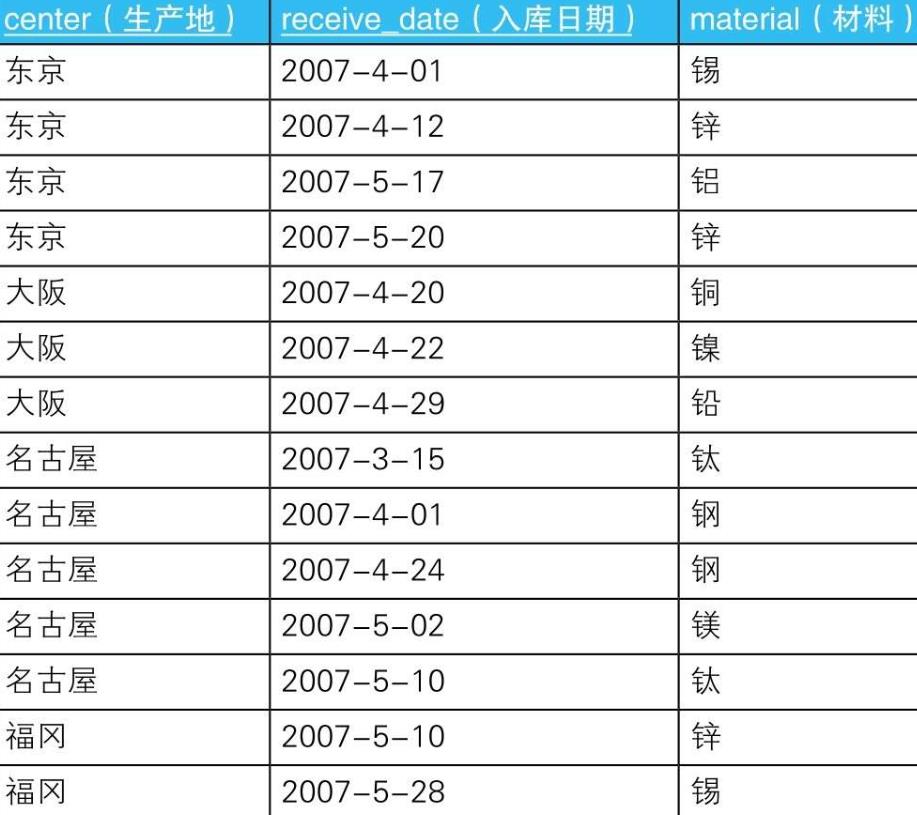
3.1.1.1. -- 选中材料存在重复的生产地
SELECT center
FROM Materials
GROUP BY center
HAVING COUNT(material) <> COUNT(DISTINCT material);
3.1.1.1.1.
SELECT center,
CASE WHEN COUNT(material) <> COUNT(DISTINCT material) THEN’存在重复’
ELSE’不存在重复’END AS status
FROM Materials
GROUP BY center;
3.1.1.2. --存在重复的集合:使用EXISTS
SELECT center, material
FROM Materials M1
WHERE EXISTS
(SELECT *
FROM Materials M2
WHERE M1.center = M2.center
AND M1.receive_date <> M2.receive_date
AND M1.material = M2.material);
3.2. 在数学中,通过GROUP BY生成的子集有一个对应的名字,叫作划分(partition)
3.2.1. 集合论和群论中的重要概念,指的是将某个集合按照某种规则进行分割后得到的子集
3.2.2. 这些子集相互之间没有重复的元素,而且它们的并集就是原来的集合
4. 寻找缺失的编号:升级版
4.1. 示例
4.1.1. -- 如果有查询结果,说明存在缺失的编号
SELECT’存在缺失的编号’AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq);
4.1.1.1. 有一个前提条件,即数列的起始值必须是1
4.1.2. -- 如果有查询结果,说明存在缺失的编号:只调查数列的连续性
SELECT’存在缺失的编号’ AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq) - MIN(seq) + 1 ;
4.1.3. -- 不论是否存在缺失的编号都返回一行结果
SELECT CASE WHEN COUNT(*) = 0
THEN ’表为空’
WHEN COUNT(*) <> MAX(seq) - MIN(seq) + 1
THEN ’存在缺失的编号’
ELSE’连续’END AS gap
FROM SeqTbl;
4.1.4. -- 查找最小的缺失编号:表中没有1时返回1
SELECT CASE WHEN COUNT(*) = 0 OR MIN(seq) > 1 -- 最小值不是1时→返回1
THEN 1
ELSE (SELECT MIN(seq +1) -- 最小值是1时→返回最小的缺失编号
FROM SeqTbl S1
WHERE NOT EXISTS
(SELECT *
FROM SeqTbl S2
WHERE S2.seq = S1.seq + 1)) END
FROM SeqTbl;
5. 为集合设置详细的条件
5.1. 示例
5.1.1.
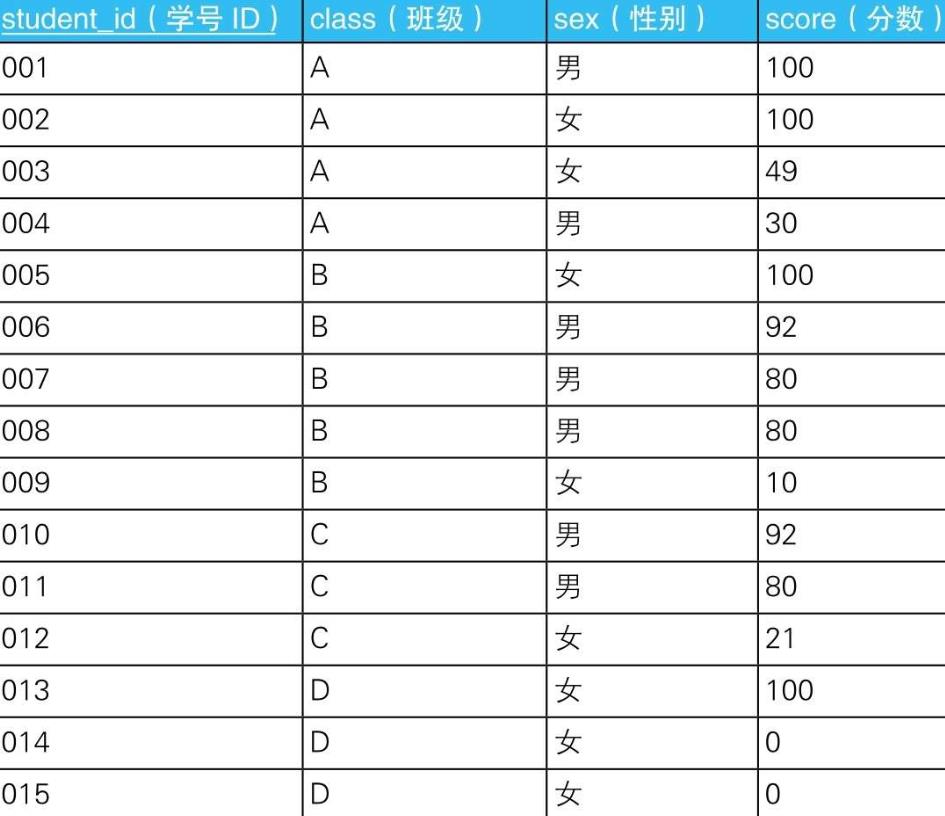
5.1.1.1. 查询出75%以上的学生分数都在80分以上的班级
5.1.1.1.1.
SELECT class
FROM TestResults
GROUP BY class
HAVING COUNT(*) * 0.75
<= SUM(CASE WHEN score >= 80
THEN 1
ELSE 0 END) ;
5.1.1.2. 查询出分数在50分以上的男生的人数比分数在50分以上的女生的人数多的班级
5.1.1.2.1.
SELECT class
FROM TestResults
GROUP BY class
HAVING SUM(CASE WHEN score >= 50 AND sex =’男’
THEN 1
ELSE 0 END)
> SUM(CASE WHEN score >= 50 AND sex =’女’
THEN 1
ELSE 0 END) ;
5.1.1.3. 查询出女生平均分比男生平均分高的班级
5.1.1.3.1. -- 比较男生和女生平均分的SQL语句(1):对空集使用AVG后返回0
SELECT class
FROM TestResults
GROUP BY class
HAVING AVG(CASE WHEN sex =’男’
THEN score
ELSE 0 END)
< AVG(CASE WHEN sex =’女’
THEN score
ELSE 0 END) ;
5.1.1.3.2. -- 比较男生和女生平均分的SQL语句(2):对空集求平均值后返回NULL
SELECT class
FROM TestResults
GROUP BY class
HAVING AVG(CASE WHEN sex =’男’
THEN score
ELSE NULL END)
< AVG(CASE WHEN sex =’女’
THEN score
ELSE NULL END) ;
5.1.1.3.2.1. 根据标准SQL的定义,对空集使用AVG函数时,结果会返回NULL
以上是关于读SQL进阶教程笔记04_集合运算的主要内容,如果未能解决你的问题,请参考以下文章