读SQL进阶教程笔记10_HAVING下
Posted 躺柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读SQL进阶教程笔记10_HAVING下相关的知识,希望对你有一定的参考价值。
1. 按照现在的SQL标准来说,HAVING子句是可以单独使用的
1.1. 就不能在SELECT子句里引用原来的表里的列了
1.1.1. 使用常量
1.1.2. 使用聚合函数
1.2. WHERE子句用来调查集合元素的性质,而HAVING子句用来调查集合本身的性质
2. 表不是文件,记录也没有顺序,所以SQL不进行排序
3. GROUP BY子句可以用来生成子集
3.1. SQL通过不断生成子集来求得目标集合
3.2. SQL不是面向过程语言,没有循环、条件分支、赋值操作
3.3. SQL通过不断生成子集来求得目标集合
3.4. SQL不像面向过程语言那样通过画流程图来思考问题,而是通过画集合的关系图来思考
4. 示例
4.1. -- 查询缺失编号的最小值
SELECT MIN(seq + 1) AS gap
FROM SeqTbl
WHERE (seq+ 1) NOT IN ( SELECT seq FROM SeqTbl);
5. 求众数
5.1. 在群体中出现次数最多的值
5.2. 示例
5.2.1.
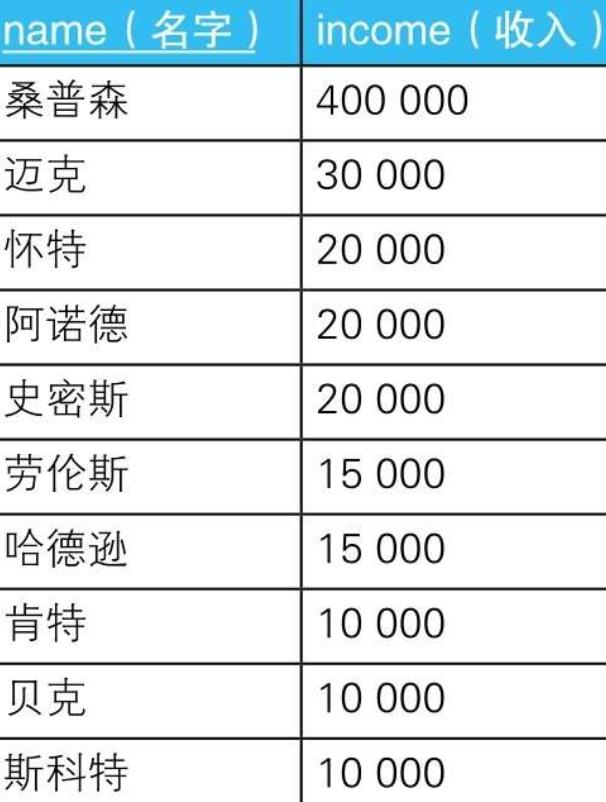
5.2.1.1. --求众数的SQL语句(1):使用谓词
SELECT income, COUNT(*) AS cnt
FROM Graduates
GROUP BY income
HAVING COUNT(*) >= ALL ( SELECT COUNT(*)
FROM Graduates
GROUP BY income);
5.2.1.1.1. ALL谓词用于NULL或空集时会出现问题
5.2.1.2. --求众数的SQL语句(2):使用极值函数
SELECT income, COUNT(*) AS cnt
FROM Graduates
GROUP BY income
HAVING COUNT(*) >= ( SELECT MAX(cnt)
FROM ( SELECT COUNT(*) AS cnt
FROM Graduates
GROUP BY income) TMP ) ;
5.2.1.2.1. 用极值函数来代替
6. 求中位数
6.1. 将集合中的元素按升序排列后恰好位于正中间的元素
6.2. 如果集合的元素个数为偶数,则取中间两个元素的平均值作为中位数
6.3. 示例
6.3.1. --求中位数的SQL语句:在HAVING子句中使用非等值自连接
SELECT AVG(DISTINCT income)
FROM (SELECT T1.income
FROM Graduates T1, Graduates T2
GROUP BY T1.income
--S1的条件
HAVING SUM(CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2
--S2的条件
AND SUM(CASE WHEN T2.income <= T1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2 ) TMP;
6.3.1.1. 加上等号并不是为了清晰地分开子集S1和S2,而是为了让这2个子集拥有共同部分
6.3.1.2. 如果去掉等号,将条件改成“>COUNT(*)/2”,那么当元素个数为偶数时,S1和S2就没有共同的元素了,也就无法求出中位数了
6.3.1.3. 如果事先知道集合的元素个数是奇数,那么因为FROM子句里的子查询结果只有一条数据,所以外层的AVG函数可以去掉
7. 查询不包含NULL的集合
7.1. COUNT(*)和COUNT(列名)
7.1.1. 性能上的区别
7.1.2. COUNT(*)可以用于NULL
7.1.3. COUNT(列名)与其他聚合函数一样,要先排除掉NULL的行再进行统计
7.1.4. COUNT(*)查询的是所有行的数目,而COUNT(列名)查询的则不一定是
7.2. 示例1
7.2.1. --在对包含NULL的列使用时,COUNT(*)和COUNT(列名)的查询结果是不同的
SELECT COUNT(*), COUNT(col_1)
FROM NullTbl;
7.3. 示例2
7.3.1.
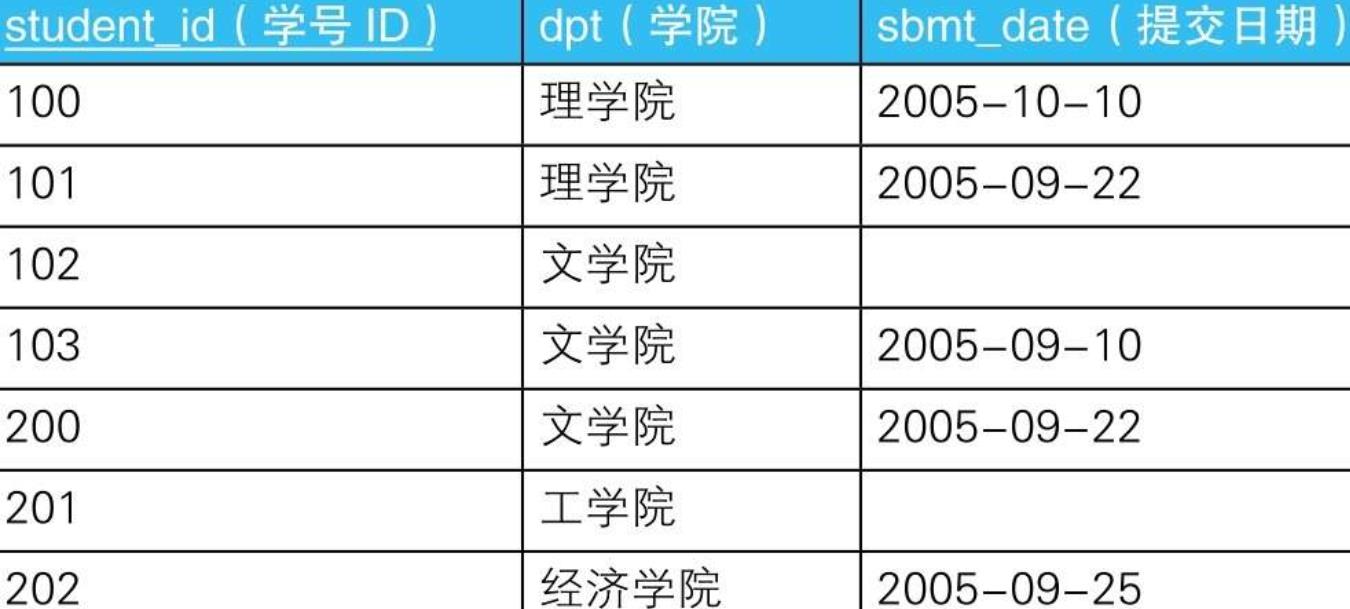
7.3.1.1. --查询“提交日期”列内不包含NULL的学院(1):使用COUNT函数
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*) = COUNT(sbmt_date);
7.3.1.2. --查询“提交日期”列内不包含NULL的学院(2):使用CASE表达式
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*) = SUM(CASE WHEN sbmt_date IS NOT NULL
THEN 1
ELSE 0 END);
7.3.1.2.1. CASE表达式的作用相当于进行判断的函数,用来判断各个元素(=行)是否属于满足了某种条件的集合
7.3.1.2.1.1. 特征函数(characteristic function)
8. 关系除法运算
8.1. 示例1
8.1.1.
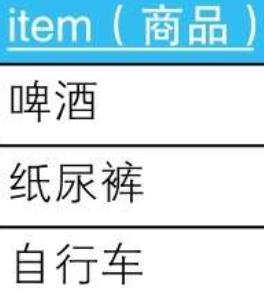

8.1.2. --查询啤酒、纸尿裤和自行车同时在库的店铺:错误的SQL语句
SELECT DISTINCT shop
FROM ShopItems
WHERE item IN (SELECT item FROM Items);
8.1.2.1. --查询啤酒、纸尿裤和自行车同时在库的店铺:正确的SQL语句
SELECT SI.shop
FROM ShopItems SI, Items I
WHERE SI.item = I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items);
8.1.2.1.1. HAVING子句的子查询(SELECT COUNT(item) FROM Items)的返回值是常量3
8.1.3. 带余除法”(division with a remainder)
8.2. 示例2
8.2.1. “精确关系除法”(exact relational division)
8.2.2. --精确关系除法运算:使用外连接和COUNT函数
SELECT SI.shop
FROM ShopItems SI LEFT OUTER JOIN Items I
ON SI.item=I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items) --条件1
AND COUNT(I.item) = (SELECT COUNT(item) FROM Items); --条件2
8.3. 在SQL里,交叉连接相当于乘法运算
8.3.1. 关系除法运算是关系代数中知名度最低的运算
读SQL进阶教程笔记08_处理数列

1. 处理有序集合也并非SQL的直接用途
1.1. SQL语言在处理数据时默认地都不考虑顺序
2. 处理数据的方法有两种
2.1. 第一种是把数据看成忽略了顺序的集合
2.2. 第二种是把数据看成有序的集合
2.2.1. 首先用自连接生成起点和终点的组合
2.2.2. 其次在子查询中描述内部的各个元素之间必须满足的关系
2.2.2.1. 要在SQL中表达全称量化时,需要将全称量化命题转换成存在量化命题的否定形式,并使用NOT EXISTS谓词
3. 生成连续编号
3.1. 序列对象(sequence object)
3.1.1. CONNECT BY(Oracle)
3.1.2. WITH子句(DB2、SQL Server)
3.1.3. 依赖数据库实现的方法
3.2. 示例
3.2.1.

3.2.1.1. --求连续编号(1):求0~99的数
SELECT D1.digit + (D2.digit * 10) AS seq
FROM Digits D1 CROSS JOIN Digits D2
ORDER BY seq;
3.2.1.2. --求连续编号(2):求1~542的数
SELECT D1.digit + (D2.digit * 10) + (D3.digit * 100) AS seq
FROM Digits D1 CROSS JOIN Digits D2
CROSS JOIN Digits D3
WHERE D1.digit + (D2.digit * 10)
+ (D3.digit * 100) BETWEEN 1 AND 542
ORDER BY seq;
3.2.1.3. --生成序列视图(包含0~999)
CREATE VIEW Sequence (seq)
AS SELECT D1.digit + (D2.digit * 10) + (D3.digit * 100)
FROM Digits D1 CROSS JOIN Digits D2
CROSS JOIN Digits D3;
3.2.1.3.1. --从序列视图中获取1~100
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 100
ORDER BY seq;
3.3. 冯·诺依曼的方法使用递归集合定义自然数,先定义0然后得到1,定义1然后得到2,是有先后顺序的
3.3.1. 适用于解决位次、累计值等与顺序相关的问题
3.4. 这里的解法完全丢掉了顺序这一概念,仅把数看成是数字的组合。这种解法更能体现出SQL语言的特色
4. 求全部的缺失编号
4.1. 示例
4.1.1. --EXCEPT版
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 12
EXCEPT
SELECT seq FROM SeqTbl;
4.1.1.1. --NOT IN版
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 12
AND seq NOT IN (SELECT seq FROM SeqTbl);
4.1.2. --动态地指定连续编号范围的SQL语句
SELECT seq
FROM Sequence
WHERE seq BETWEEN (SELECT MIN(seq) FROM SeqTbl)
AND (SELECT MAX(seq) FROM SeqTbl)
EXCEPT
SELECT seq FROM SeqTbl;
4.1.2.1. 查询上限和下限未必固定的表时非常方便
4.1.2.2. 两个自查询没有相关性,而且只会执行一次
4.1.2.3. 如果在“seq”列上建立索引,那么极值函数的运行可以变得更快速
5. 座位预订
5.1. 三个人能坐得下吗
5.1.1.

5.1.1.1. --找出需要的空位(1):不考虑座位的换排
SELECT S1.seat AS start_seat, \'~\', S2.seat AS end_seat
FROM Seats S1, Seats S2
WHERE S2.seat = S1.seat + (:head_cnt -1) --决定起点和终点
AND NOT EXISTS
(SELECT *
FROM Seats S3
WHERE S3.seat BETWEEN S1.seat AND S2.seat
AND S3.status <>’未预订’);
5.1.1.1.1. “:head_cnt”是表示需要的空位个数的参数
5.1.1.1.2. 如果不减1,会多取一个座位
5.1.1.2. 第一步:通过自连接生成起点和终点的组合
5.1.1.2.1. S2.seat = S1.seat + (:head_cnt-1)的部分
5.1.1.2.2. 排除掉了像1~8、2~3这样长度不是3的组合
5.1.1.3. 第二步:描述起点到终点之间所有的点需要满足的条件
5.1.1.3.1. 序列内的点需要满足的条件“所有座位的状态都是‘未预订’”
5.1.1.4. --找出需要的空位(2):考虑座位的换排
SELECT S1.seat AS start_seat, \'~\', S2.seat AS end_seat
FROM Seats2 S1, Seats2 S2
WHERE S2.seat = S1.seat + (:head_cnt -1) --决定起点和终点
AND NOT EXISTS
(SELECT *
FROM Seats2 S3
WHERE S3.seat BETWEEN S1.seat AND S2.seat
AND ( S3.status <>’未预订’
OR S3.row_id <> S1.row_id));
5.1.1.4.1. 所有座位的状态都是‘未预订’,且行编号相同
5.2. 最多能坐下多少人
5.2.1.
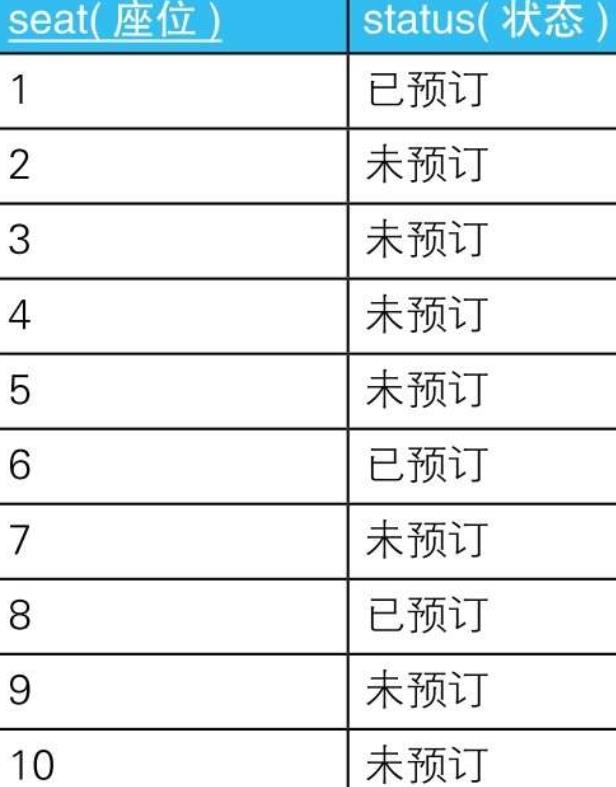
5.2.1.1. 条件1:起点到终点之间的所有座位状态都是“未预订”
5.2.1.2. 条件2:起点之前的座位状态不是“未预订”
5.2.1.3. 条件3:终点之后的座位状态不是“未预订”
5.2.2. --第一阶段:生成存储了所有序列的视图
CREATE VIEW Sequences (start_seat, end_seat, seat_cnt) AS
SELECT S1.seat AS start_seat,
S2.seat AS end_seat,
S2.seat - S1.seat + 1 AS seat_cnt
FROM Seats3 S1, Seats3 S2
WHERE S1.seat <= S2.seat --第一步:生成起点和终点的组合
AND NOT EXISTS --第二步:描述序列内所有点需要满足的条件
(SELECT *
FROM Seats3 S3
WHERE ( S3.seat BETWEEN S1.seat AND S2.seat
AND S3.status <>’未预订’) --条件1的否定
OR (S3.seat = S2.seat + 1 AND S3.status =’未预订’)
--条件2的否定
OR (S3.seat = S1.seat -1 AND S3.status =’未预订’));
--条件3的否定
5.2.2.1. --第二阶段:求最长的序列
SELECT start_seat, \'~\', end_seat, seat_cnt
FROM Sequences
WHERE seat_cnt = (SELECT MAX(seat_cnt) FROM Sequences);
6. 单调递增和单调递减
6.1. 示例
6.1.1.
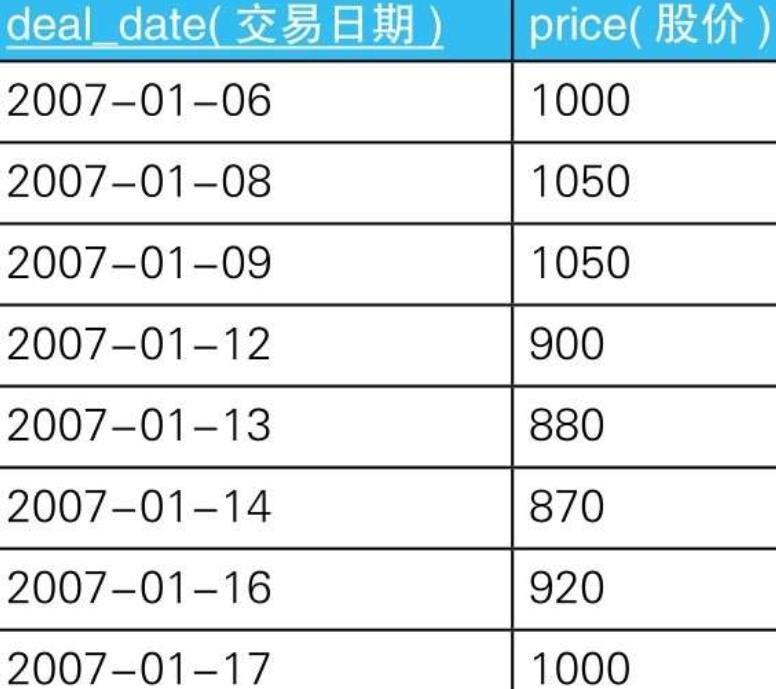
6.1.2. --生成起点和终点的组合的SQL语句
SELECT S1.deal_date AS start_date,
S2.deal_date AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date < S2.deal_date;
6.1.2.1. --求单调递增的区间的SQL语句:子集也输出
SELECT S1.deal_date AS start_date,
S2.deal_date AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date < S2.deal_date --第一步:生成起点和终点的组合
AND NOT EXISTS
( SELECT * --第二步:描述区间内所有日期需要满足的条件
FROM MyStock S3, MyStock S4
WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S3.deal_date < S4.deal_date
AND S3.price >= S4.price);
6.1.2.1.1. --排除掉子集,只取最长的时间区间
SELECT MIN(start_date) AS start_date, --最大限度地向前延伸起点
end_date
FROM (SELECT S1.deal_date AS start_date,
MAX(S2.deal_date) AS end_date --最大限度地向后延伸终点
FROM MyStock S1, MyStock S2
WHERE S1.deal_date < S2.deal_date
AND NOT EXISTS
(SELECT *
FROM MyStock S3, MyStock S4
WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S3.deal_date < S4.deal_date
AND S3.price >= S4.price)
GROUP BY S1.deal_date) TMP
GROUP BY end_date;
以上是关于读SQL进阶教程笔记10_HAVING下的主要内容,如果未能解决你的问题,请参考以下文章