三十五.智能驾驶之基于PolarNet的点云语义分割及ROS系统实践
Posted okgwf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三十五.智能驾驶之基于PolarNet的点云语义分割及ROS系统实践相关的知识,希望对你有一定的参考价值。
第一部分 PolarNet介绍
第二部分 ROS系统PolarNet实践
第一部分 PolarNet介绍
点云语义分割在自动驾驶领域的感知模块占据重要地位, 从多年前基于传统的点云聚类和分割,到近些年基于深度学习的点云语义分割方法, 技术逐渐成熟已经进入实时端到端的阶段. 前有基于球面投影映射出二维深度图的SqueezeSeg,后又百度的Apollo和Autoware中开源的基于鸟瞰图二维网格的cnn_seg. 本文将介绍一种较新的点云语义分割方法: PolarNet,以及它的升级版点云全景语义分割方法:Panoptic-PolarNet.
从整体结构来看,PolarNet和多数点云语义分割网络结构一样, 针对点云数据的特点: 空间分布稀疏性,无序性和随是三维数据却无法直接应用三维卷积(计算量剧增)等问题, 先将三维点云的鸟瞰图映射为二维图像,然后使用编码器-解码器结构的全卷积网络进行逐像素的分类. 这里PolarNet使用U-Net网络的编码阶段来学习不同尺度的特征,使用解码器阶段完成每个像素点的分类.
关于U-Net网络及其升级版U-Net++,U-Net3+, 其主体网络都是基于FCN网络, 只是在垮层级间的深浅特征融合方式上做了不同的调整. 使网络可以提取和学习到更为细节的图像信息,语义分割效果也更佳.
所以, PolarNet主要思想重点就放在如何将3维点云的鸟瞰图映射为二维图像上. 同样的思想, SqueezeSeg的实现方法是通过将3维点云经球面投射映射为一个二维的深度图,cnn_seg的实现方法是将3维点云鸟瞰视图向地面投影映射为直角坐标系网格的二维网格.
PolarNet的基于极坐标的鸟瞰图(Bird Eye View, BEV)投影:
PolarNet对BEV投射的采用了极坐标系来分割二维投影映射(这让我想起了有一种基于传统方法的点云地面分割算法,也采用了类似的方法,在我的<<二十五. 智能驾驶之基于点云分割和聚类的障碍物检测>>做了介绍). 这有别于其他算法对BEV投影以笛卡尔坐标系来分割二维投影映射(二维网格).如下图所示:
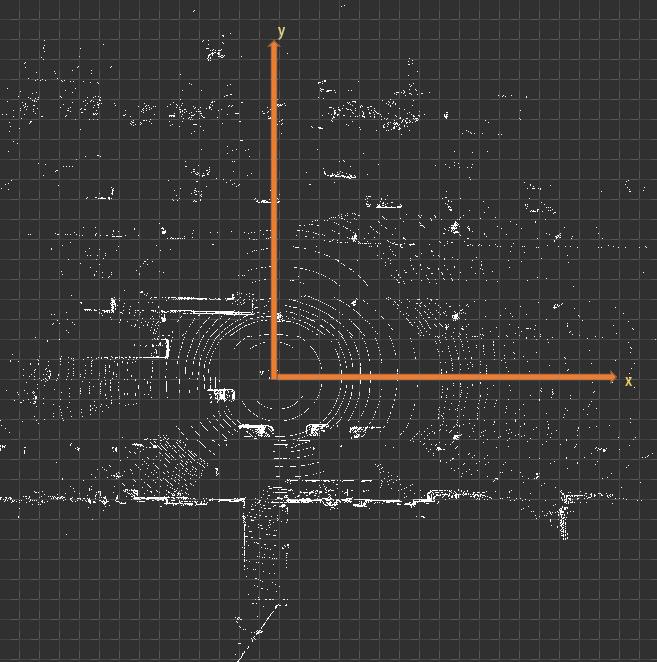
(以笛卡尔坐标系分割二维鸟瞰图)
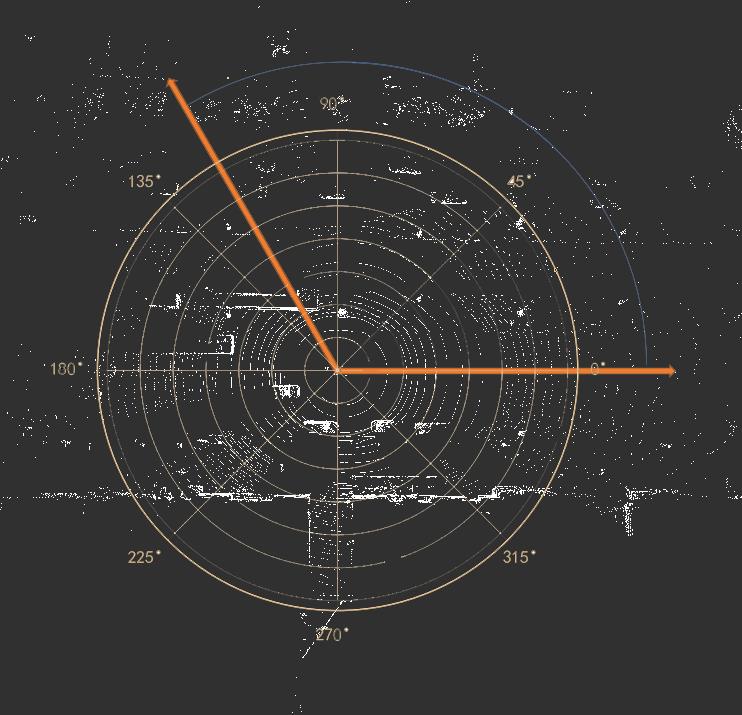
(以极坐标系分割二维鸟瞰图)
如上图,PolarNet采用了极坐标系替代笛卡尔坐标系,使用极角θ和极径ρ表示的有序对(ρ,θ)来代表点云的投影分区,按照极坐标系网格对平面进行划分,这种做法能够进一步使得点在网格间均匀分布,远距离的网格也能保留更多的点。特别是对地面,可以保证同一条激光扫描线落在同一个分区内.
基于极坐标系分割鸟瞰图BEV的过程(图片来源原伦文供图):
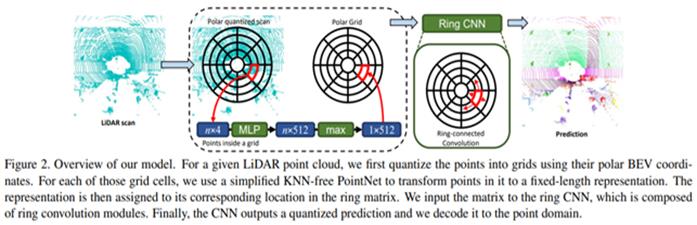
PolarNet训练了一个简单的PointNet(注:此PointNet不是语义分割网络PointNet)神经网络用于极坐标网格内的特征提取. 如上图, 对点云的处理大致分以下几步:
一. 将一帧点云从鸟瞰图BEV视角投射到地面,映射为一个二维平面映射图. 并以车身载体坐标系原点为中心点,建立极坐标系.
二. 在极坐标系中,按照预设的角度偏移θ为step,将0-360度的极坐标系平分为360/θ=N份扇面,类似于磁盘单个盘面的扇区感念, 同时在以原点为中心的径向方向,按照预设的半径偏移ρ,向外等分出一系列同心圆, 类似于磁盘单个盘面的柱面. 此时,由不同的扇区和同心圆,就将整个有效极坐标系内的点云,分成若干个不同的扇形网格, 类似于磁盘单盘面的一个扇区.
三. 使用代码内置的一个PointNet对每一个扇形网格进行学习得到一个固定长度的特征表示.
四. 因为每一个同心圆环是有若干个扇形网格环绕一周连接而成,即它们是首尾连接的. 为了学习到的特征完整不间断,把学习到的每一个同心圆环内的扇形网格的特征也按原顺序首尾拼接,形成一个环形特征表示.
五. 将学习到的环形特征表示输入一个Ring CNN的神经网络中学习其整体特征.
Ring CNN就是基于环卷积的卷积神经网络,这也是PolarNet的独到之处. 普通的卷积网络输入的特征是个平面二维数据. Ring CNN这里输入的是将平面首尾连接的特征, 使用卷积核循环一边卷积操作,以保证不遗漏极坐标系下同心环的连接处的特征(详细参见其官方源码).
第二部分 ROS系统PolarNet实践
理解PolarNet设计思想,并理解其代码后,下一步就是上手实践,因为熟悉ROS系统所以直接在ROS创建功能包,并加载禾赛数据集进行实践. 下面直接放实践截图
下图是在ROS系统加载一帧semantic-kitti数据集的一帧Lidar数据,并通过PolarNet网络进行语义分割后效果,效果还可以, 但和semantic-kitti数据集提供的labels数据相机,要差一点:

进一步,手头有禾赛数据集,加载一帧禾赛的图片,Lidar数据,效果就一般了, 感觉还是有些地方没有调试好. 效果如下:

以上是关于三十五.智能驾驶之基于PolarNet的点云语义分割及ROS系统实践的主要内容,如果未能解决你的问题,请参考以下文章
国科大人工智能学院《计算机视觉》课 —三维视觉—三维表达与语义建模
国科大人工智能学院《计算机视觉》课 —三维视觉—三维表达与语义建模
国科大人工智能学院《计算机视觉》课 —三维视觉—三维表达与语义建模
[Python人工智能] 三十五.基于Transformer的商品评论情感分析 机器学习和深度学习的Baseline模型实现