[Python人工智能] 三十五.基于Transformer的商品评论情感分析 机器学习和深度学习的Baseline模型实现
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python人工智能] 三十五.基于Transformer的商品评论情感分析 机器学习和深度学习的Baseline模型实现相关的知识,希望对你有一定的参考价值。
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章通过keras-bert库构建Bert模型,并实现微博情感分析。这篇文章将利用Keras构建Transformer或多头自注意机制模型,并实现商品论文的情感分析,在这之前,我们先构建机器学习和深度学习的Baseline模型,只有不断强化各种模型的实现,才能让我们更加熟练地应用于自身研究领域和改进。基础性文章,希望对您有所帮助!
文章目录
本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵!作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,为小宝赚点奶粉钱,但更多博客尤其基础性文章,还是会继续免费分享,该专栏也会用心撰写,望对得起读者。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油喔~
- Keras下载地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下载地址:https://github.com/eastmountyxz/AI-for-TensorFlow
前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
- [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
- [Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- [Python人工智能] 十.Tensorflow+Opencv实现CNN自定义图像分类案例及与机器学习KNN图像分类算法对比
- [Python人工智能] 十一.Tensorflow如何保存神经网络参数
- [Python人工智能] 十二.循环神经网络RNN和LSTM原理详解及TensorFlow编写RNN分类案例
- [Python人工智能] 十三.如何评价神经网络、loss曲线图绘制、图像分类案例的F值计算
- [Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
- [Python人工智能] 十六.Keras环境搭建、入门基础及回归神经网络案例
- [Python人工智能] 十七.Keras搭建分类神经网络及MNIST数字图像案例分析
- [Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解
[Python人工智能] 十九.Keras搭建循环神经网络分类案例及RNN原理详解 - [Python人工智能] 二十.基于Keras+RNN的文本分类vs基于传统机器学习的文本分类
- [Python人工智能] 二十一.Word2Vec+CNN中文文本分类详解及与机器学习(RF\\DTC\\SVM\\KNN\\NB\\LR)分类对比
- [Python人工智能] 二十二.基于大连理工情感词典的情感分析和情绪计算
- [Python人工智能] 二十三.基于机器学习和TFIDF的情感分类(含详细的NLP数据清洗)
- [Python人工智能] 二十四.易学智能GPU搭建Keras环境实现LSTM恶意URL请求分类
- [Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理
- [Python人工智能] 二十七.基于BiLSTM-CRF的医学命名实体识别研究(下)模型构建
- [Python人工智能] 二十八.Keras深度学习中文文本分类万字总结(CNN、TextCNN、LSTM、BiLSTM、BiLSTM+Attention)
- [Python人工智能] 二十九.什么是生成对抗网络GAN?基础原理和代码普及(1)
- [Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像
- [Python人工智能] 三十一.Keras实现BiLSTM微博情感分类和LDA主题挖掘分析
- [Python人工智能] 三十二.Bert模型 (1)Keras-bert基本用法及预训练模型
- [Python人工智能] 三十三.Bert模型 (2)keras-bert库构建Bert模型实现文本分类
- [Python人工智能] 三十四.Bert模型 (3)keras-bert库构建Bert模型实现微博情感分析
- [Python人工智能] 三十五.基于Transformer的商品评论情感分析 (1)机器学习和深度学习的Baseline模型实现
一.数据预处理
首先进行数据预处理,并给出整个项目的基本目录。
C:.
│ 01-cutword.py
│ 02-wordcloud.py
│ 03-ml-model.py
│ 04-CNN-model.py
│ 05-TextCNN-model.py
│ 06-BiLSTM-model.py
│ 07-BiGRU-model.py
└─data
data-word-count-train-happy.csv
data-word-count-train-sad.csv
online_shopping_10_cats.csv
online_shopping_10_cats_words.csv
online_shopping_10_cats_words_test.csv
online_shopping_10_cats_words_train.csv
1.数据集
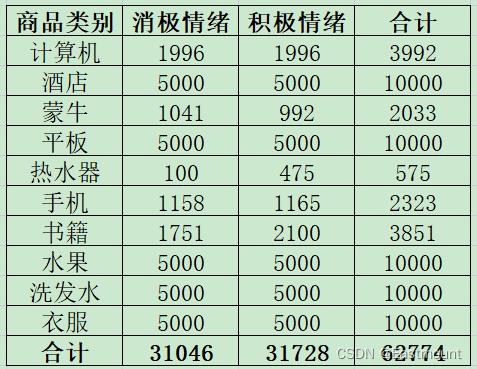
整个数据集来源于github,是一个包含十类商品的评论数据集,我们将对其进行情感分析研究。
- https://github.com/SophonPlus/ChineseNlpCorpus/tree/master/datasets/online_shopping_10_cats
- 关于文本分类(情感分析)的中文数据集汇总 - 樱与刀
整个数据集包含3个字段,分别是:
- cat:商品类型
- label:商品类别
- review:评论内容

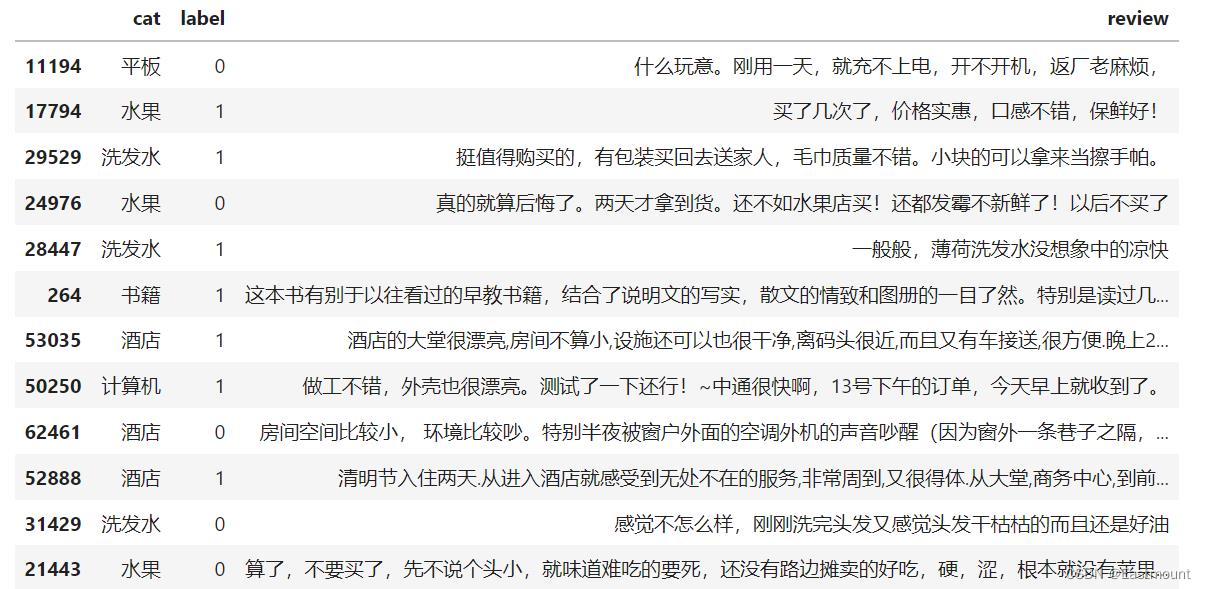
数据集存储在CSV文件中,如下图所示:

数据分布如下图所示:
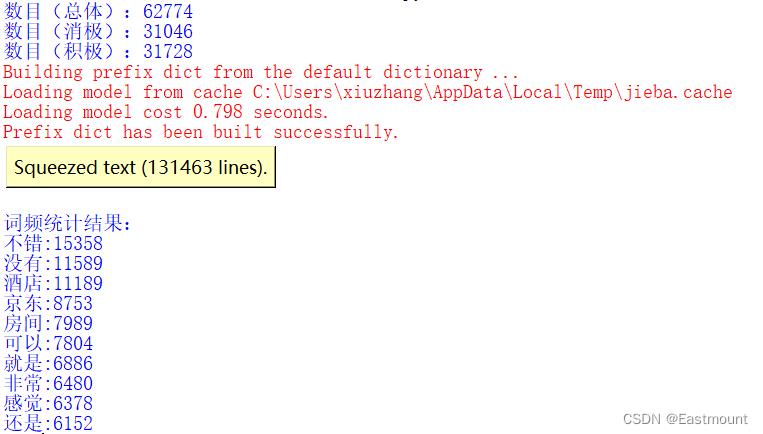
2.中文分词
中文分词利用Jieba工具实现,处理后的结果如下图所示:

程序的运行结果如下图所示:
该部分代码如下所示:
# -*- coding: utf-8 -*-
"""
@author: xiuzhang Eastmount 2022-05-04
"""
import pandas as pd
import jieba
import csv
from collections import Counter
#-----------------------------------------------------------------------------
#样本数量统计
pd_all = pd.read_csv('data/online_shopping_10_cats.csv')
moods = 0: '消极', 1: '积极'
print('数目(总体):%d' % pd_all.shape[0])
for label, mood in moods.items():
print('数目():'.format(mood, pd_all[pd_all.label==label].shape[0]))
#-----------------------------------------------------------------------------
#中文分词和停用词过滤
cut_words = ""
all_words = ""
stopwords = ["[", "]", ")", "(", ")", "(", "【", "】", "!", ",", "$",
"·", "?", ".", "、", "-", "—", ":", ":", "《", "》", "=",
"。", "…", "“", "?", "”", "~", " ", "-", "+", "\\\\", "‘",
"~", ";", "’", "...", "..", "&", "#", "....", ",",
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10"
"的", "和", "之", "了", "哦", "那", "一个", ]
fw = open('data/online_shopping_10_cats_words.csv', 'w', encoding='utf-8')
for line in range(len(pd_all)): #cat label review
dict_cat = pd_all['cat'][line]
dict_label = pd_all['label'][line]
dict_review = pd_all['review'][line]
dict_review = str(dict_review)
#print(dict_cat, dict_label, dict_review)
#jieba分词并过滤停用词
cut_words = ""
data = dict_review.strip('\\n')
data = data.replace(",", "") #一定要过滤符号 ","否则多列
seg_list = jieba.cut(data, cut_all=False)
for seg in seg_list:
if seg not in stopwords:
cut_words += seg + " "
all_words += cut_words
#print(cut_words)
fw.write(str(dict_cat)+","+str(dict_label)+","+str(cut_words)+"\\n")
else:
fw.close()
#-----------------------------------------------------------------------------
#词频统计
all_words = all_words.split()
print(all_words)
c = Counter()
for x in all_words:
if len(x)>1 and x != '\\r\\n':
c[x] += 1
#输出词频最高的前10个词
print('\\n词频统计结果:')
for (k,v) in c.most_common(10):
print("%s:%d"%(k,v))
二.词云可视化分析
接着我们给“online_shopping_10_cats_words.csv”增加表头:cat、label和review,然后进行词云可视化分析。
第一步,安装Pyecharts扩展包。
- pip install pyecharts
第二步,分别统计积极和消极情绪特征词的数量,并利用Counter函数统计高频词。

第三步,调用Pyecharts绘制词云。

积极和消极情感的最终词云如下图所示:


完整代码如下:
# -*- coding: utf-8 -*-
"""
@author: xiuzhang Eastmount 2022-05-04
"""
import pandas as pd
import csv
from collections import Counter
#-----------------------------------------------------------------------------
#读取分词后特征词
cut_words = ""
all_words = ""
pd_all = pd.read_csv('data/online_shopping_10_cats_words.csv')
moods = 0: '积极', 1: '消极'
print('数目(总体):%d' % pd_all.shape[0])
for line in range(len(pd_all)): #cat label review
dict_cat = pd_all['cat'][line]
dict_label = pd_all['label'][line]
dict_review = pd_all['review'][line]
if str(dict_label)=="1": #积极
cut_words = dict_review
all_words += str(cut_words)
#print(cut_words)
#-----------------------------------------------------------------------------
#词频统计
all_words = all_words.split()
c = Counter()
for x in all_words:
if len(x)>1 and x != '\\r\\n':
c[x] += 1
print('\\n词频统计结果:')
for (k,v) in c.most_common(10):
print("%s:%d"%(k,v))
#存储数据
name ="data/data-word-count-train-happy.csv"
fw = open(name, 'w', encoding='utf-8')
i = 1
for (k,v) in c.most_common(len(c)):
fw.write(str(i)+','+str(k)+','+str(v)+'\\n')
i = i + 1
else:
print("Over write file!")
fw.close()
#-----------------------------------------------------------------------------
#词云分析
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
#生成数据 word = [('A',10), ('B',9), ('C',8)] 列表+Tuple
words = []
for (k,v) in c.most_common(120):
words.append((k,v))
#渲染图
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 40], shape='diamond') #shape=SymbolType.ROUND_RECT
.set_global_opts(title_opts=opts.TitleOpts(title='词云图'))
)
return c
wordcloud_base().render('电商评论积极情感分析词云图.html')
三.机器学习情感分析
为了更准确地评估模型,本文将分词后的数据集分成了训练集和测试集,并在相同环境进行对比实验。
具体流程如下:
- 数据读取及预处理
- TF-IDF计算
- 分类模型构建
- 实验评估
输出结果如下图所示:
完整代码如下所示:
# -*- coding: utf-8 -*-
"""
@author: xiuzhang Eastmount 2022-05-04
"""
import jieba
import pandas as pd
import numpy as np
from collections import Counter
from scipy.sparse import coo_matrix
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import svm
from sklearn import neighbors
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import AdaBoostClassifier
#-----------------------------------------------------------------------------
#变量定义
train_cat = []
test_cat = []
train_label = []
test_label = []
train_review = []
test_review = []
#读取数据
train_path = 'data/online_shopping_10_cats_words_train.csv'
test_path = 'data/online_shopping_10_cats_words_test.csv'
types = 0: '消极', 1: '积极'
pd_train = pd.read_csv(train_path)
pd_test = pd.read_csv(test_path)
print('训练集数目(总体):%d' % pd_train.shape[0])
print('测试集数目(总体):%d' % pd_test.shape[0])
for line in range(len(pd_train)):
dict_cat = pd_train['cat'][line]
dict_label = pd_train['label'][line]
dict_content = str(pd_train['review'][line])
train_cat.append(dict_cat)
train_label.append(dict_label)
train_review.append(dict_content)
print(len(train_cat),len(train_label),len(train_review))
print(train_cat[:5])
print(train_label[:5])
for line in range(len(pd_test)):
dict_cat = pd_test['cat'][line]
dict_label = pd_test['label'][line]
dict_content = str(pd_test['review'][line])
test_cat.append(dict_cat)
test_label.append(dict_label)
test_review.append(dict_content)
print(len(test_cat),len(test_label),len(test_review),"\\n")
#-----------------------------------------------------------------------------
#TFIDF计算
#将文本中的词语转换为词频矩阵 矩阵元素a[i][j]表示词j在第i类文本下的词频
vectorizer = CountVectorizer(min_df=10) #MemoryError控制参数
#统计每个词语的tf-idf权值
transformer = TfidfTransformer()
#第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(train_review+test_review))
for n in tfidf[:5]:
print(n)
print(type(tfidf))
#获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
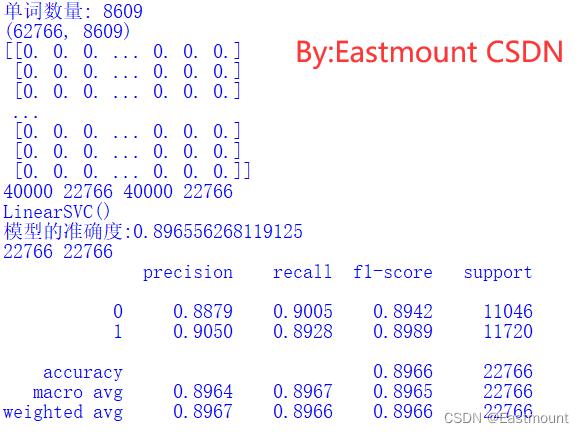
print("单词数量:", len(word))
#元素w[i][j]表示词j在第i类文本中的tf-idf权重
X = coo_matrix(tfidf, dtype=np.float32).toarray() #稀疏矩阵
print(X.shape)
print(X[:10])
X_train = X[:len(train_label)]
X_test = X[len(train_label):]
y_train = train_label
y_test = test_label
print(len(X_train),len(X_test),len(y_train),len(y_test))
#-----------------------------------------------------------------------------
#分类模型
clf = svm.LinearSVC()
print(clf)
clf.fit(X_train, y_train)
pre = clf.predict(X_test)
print('模型的准确度:'.format(clf.score(X_test, y_test)))
print(len(pre), len(y_test))
print(classification_report(y_test, pre, digits=4))
with open("SVM-pre-result.txt","w") as f: #结果保存
for v in pre:
f.write(str(v)+"\\n")
其他常见机器学习模型如下:
- clf = LogisticRegression(solver=‘liblinear’)
- clf = RandomForestClassifier(n_estimators=5)
- clf = DecisionTreeClassifier()
- clf = AdaBoostClassifier()
- clf = MultinomialNB()
- clf = neighbors.KNeighborsClassifier(n_neighbors=3)
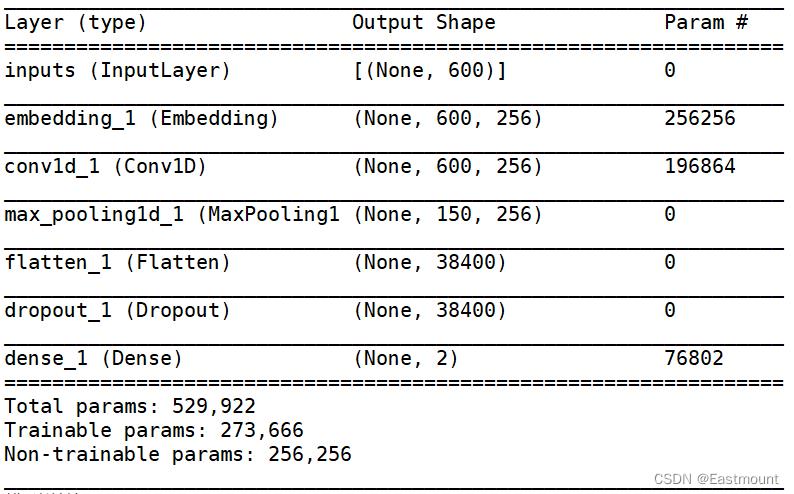
四.CNN和TextCNN情感分析
1.CNN
基本流程:
- 数据读取及预处理
- 特征提取
- Embedding
- 构建深度学习分类模型
- 实验评估
训练构建的模型如下所示:
训练输出的结果如下:
Train on 40000 samples, validate on 10000 samples
Epoch 1/12
40000/40000 [==============================] - 8s 211us/step - loss: 0.4246 - acc: 0.8048 - val_loss: 0.3602 - val_acc: 0.8814
Epoch 2/12
40000/40000 [============================