无向图和有向图的详细讲解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无向图和有向图的详细讲解相关的知识,希望对你有一定的参考价值。
无向图和有向图的详细讲解,谢谢。
能不能再详细一点,还有我听说有什么顶点之类的,能不能给我解释一下。
1、无向图,边没有方向的图称为无向图。邻接矩阵则是对称的,且只有0和1,因为没有方向的区别后,要么有边,要么没边。
2、有向图,一个有向图D是指一个有序三元组(V(D),A(D),ψD),其中ψD为关联函数,它使A(D)中的每一个元素(称为有向边或弧)对应于V(D)中的一个有序元素(称为顶点或点)对。

扩展资料
定义
针对有向图而言的,它是一个包含有向图的所有点的线性序列,且满足两个条件:a有向图的每个顶点只出现一次。b若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 应该出现在顶点 B 的前面。
邻接矩阵和关联矩阵定义:设D(V,E)是有向图,其中V=v1,v2,v2…vn,E=e1,e2,e3,…em称A(D)=(aij)nxn是D的领接矩阵,其中aij是以vi为起始点,以vj为终点的边的条数。
若图D中无环,则称M(D)=(mij)nxm为关联矩阵。[i,j是下标,n是点的个数,m是边的数量注意:1.关联矩阵是针对边来说的,所以矩阵大小为n*m。
参考资料来源:百度百科—无向图
参考资料来源:百度百科—有向图
参考技术A 1.有向图若图G中的每条边都是有方向的,则称G为有向图(Digraph)。
(1)有向边的表示
在有向图中,一条有向边是由两个顶点组成的有序对,有序对通常用尖括号表示。有向边也称为弧(Arc),边的始点称为弧尾(Tail),终点称为弧头(Head)。
【例】<vi,vj>表示一条有向边,vi是边的始点(起点),vj是边的终点。因此,<vi,vj>和<vj,vi>是两条不同的有向边。
(2)有向图的表示
【例】下面(a)图中G1是一个有向图。图中边的方向是用从始点指向终点的箭头表示的,该图的顶点集和边集分别为:
V(G1)=v1,v2,v3
E(G1)=<v1,v2>,<v2,v1>,<v2,v3>
2.无向图
若图G中的每条边都是没有方向的,则称G为无向图(Undigraph)。
(1)无向边的表示
无向图中的边均是顶点的无序对,无序对通常用圆括号表示。
【例】无序对(vi,vj)和(vj,vi)表示同一条边。
(2)无向图的表示
【例】下面(b)图中的G2和(c)图中的G3均是无向图,它们的顶点集和边集分别为:
V(G2)=v1,v2,v3,v4
E(G2)=(vl,v2),(v1,v3),(v1,v4),(v2,v3),(v2,v4),(v3,v4)
V(G3)=v1,v2,v3,v4,v5,v6,v7
E(G3)=(v1,v2),(vl,v3),(v2,v4),(v2,v5),(v3,v6),(v3,v7)
注意:
在以下讨论中,不考虑顶点到其自身的边。即若(v1,v2)或<vl,v2>是E(G)中的一条边,则要求v1≠v2。此外,不允许一条边在图中重复出现,即只讨论简单的图。
3.图G的顶点数n和边数e的关系
(1)若G是无向图,则0≤e≤n(n-1)/2
恰有n(n-1)/2条边的无向图称无向完全图(Undireet-ed Complete Graph)
(2)若G是有向图,则0≤e≤n(n-1)。
恰有n(n-1)条边的有向图称为有向完全图(Directed Complete Graph)。本回答被提问者采纳 参考技术B 有向图是单向的,有箭头,例如路径可以从A节点到B节点,但不可以从B节点到A节点;无向图是双向的,没有箭头,路径可以从A到B,也可以从B到A
无向图的基本算法
根据性质,图可以分为无向图和有向图。本文先介绍无向图,后文再介绍有向图。之所以要研究图,是因为图在生活中应用比较广泛。
无向图
图是若干个顶点(Vertices)和边(Edges)相互连接组成的。边仅由两个顶点连接,并且没有方向的图称为无向图。在研究图之前,有一些定义需要明确,下图中表示了图的一些基本属性的含义,这里就不多说明。
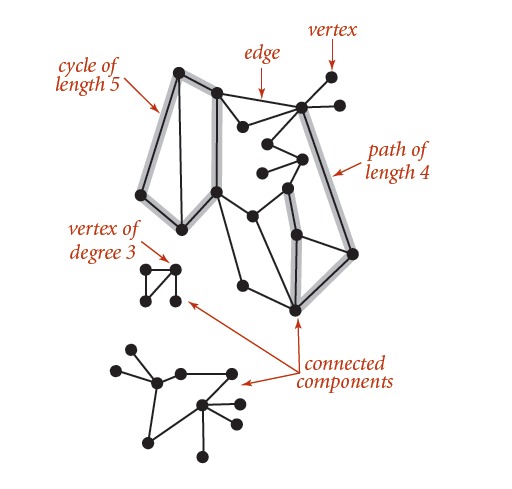
图的API表示
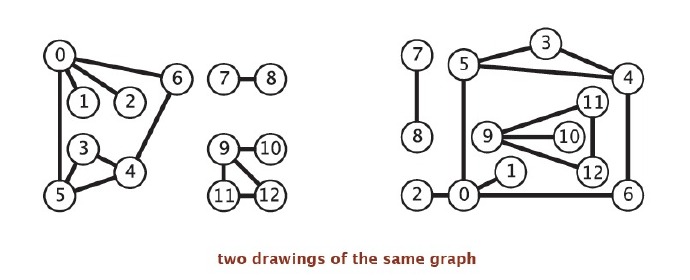
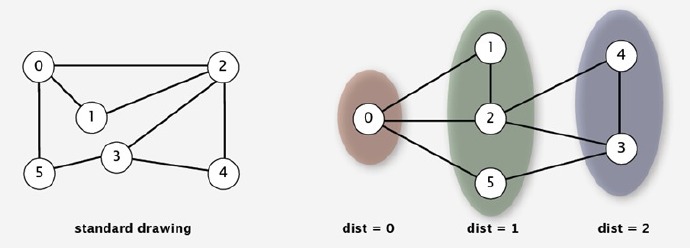
在研究图之前,我们需要选用适当的数据结构来表示图,有时候,我们常被我们的直觉欺骗,如下图,这两个其实是一样的,这其实也是一个研究问题,就是如何判断图的形态。
要用计算机处理图,我们可以抽象出以下的表示图的API:  Graph的API的实现可以由多种不同的数据结构来表示,最基本的是维护一系列边的集合,
Graph的API的实现可以由多种不同的数据结构来表示,最基本的是维护一系列边的集合,

如下:还可以使用邻接矩阵来表示:
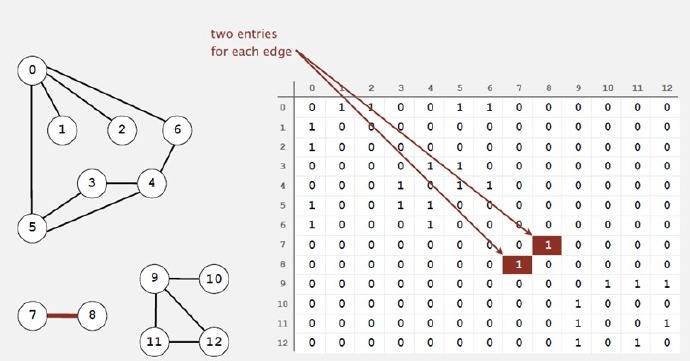
也可以使用邻接列表来表示:
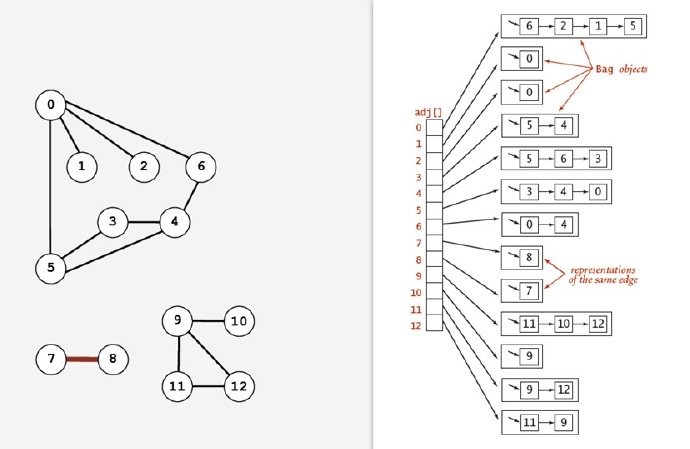
由于采用如上方式具有比较好的灵活性,采用邻接列表来表示的话,可以定义如下数据结构来表示一个Graph对象。


public class Graph
{
private readonly int verticals;//顶点个数
private int edges;//边的个数
private List<int>[] adjacency;//顶点联接列表
public Graph(int vertical)
{
this.verticals = vertical;
this.edges = 0;
adjacency=new List<int>[vertical];
for (int v = 0; v < vertical; v++)
{
adjacency[v]=new List<int>();
}
}
public int GetVerticals ()
{
return verticals;
}
public int GetEdges()
{
return edges;
}
public void AddEdge(int verticalStart, int verticalEnd)
{
adjacency[verticalStart].Add(verticalEnd);
adjacency[verticalEnd].Add(verticalStart);
edges++;
}
public List<int> GetAdjacency(int vetical)
{
return adjacency[vetical];
}
}
采用以上三种表示方式的效率如下:
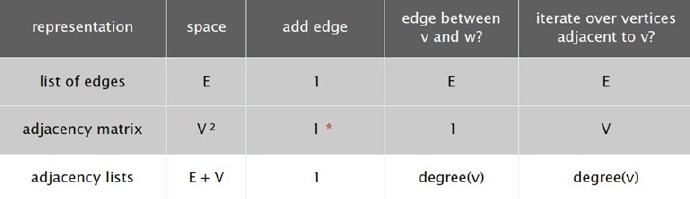 在讨论完图的表示之后,我们来看下在图中比较重要的一种算法,即深度优先算法:
在讨论完图的表示之后,我们来看下在图中比较重要的一种算法,即深度优先算法:
深度优先算法
在谈论深度优先算法之前,我们可以先看看迷宫探索问题。下面是一个迷宫和图之间的对应关系:迷宫中的每一个交会点代表图中的一个顶点,每一条通道对应一个边。 迷宫探索可以采用Trémaux绳索探索法。即:
- 在身后放一个绳子
- 访问到的每一个地方放一个绳索标记访问到的交会点和通道
- 当遇到已经访问过的地方,沿着绳索回退到之前没有访问过的地方:
图示如下:

下面是迷宫探索的一个小动画:
深度优先搜索算法模拟迷宫探索。在实际的图处理算法中,我们通常将图的表示和图的处理逻辑分开来。所以算法的整体设计模式如下:
- 创建一个Graph对象
- 将Graph对象传给图算法处理对象,如一个Paths对象
- 然后查询处理后的结果来获取信息
下面是深度优先的基本代码,我们可以看到,递归调用dfs方法,在调用之前判断该节点是否已经被访问过。
public class DepthFirstSearch { private boolean[] marked; // marked[v] = is there an s-v path? private int count; // number of vertices connected to s public DepthFirstSearch(Graph G, int s) { marked = new boolean[G.V()]; dfs(G, s); } //depth first search from v private void dfs(Graph G, int v) { count++; marked[v] = true; for (int w : G.adj(v)) { if (!marked[w]) { dfs(G, w); } } } public boolean marked(int v) { return marked[v]; } public int count() { return count; } }
试验一个算法最简单的办法是找一个简单的例子来实现。
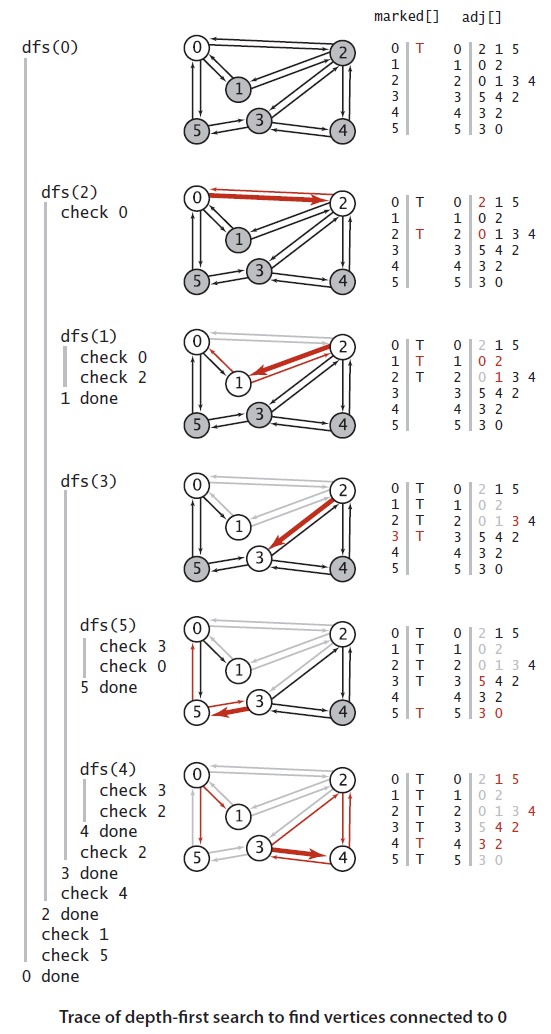
深度优先路径查询
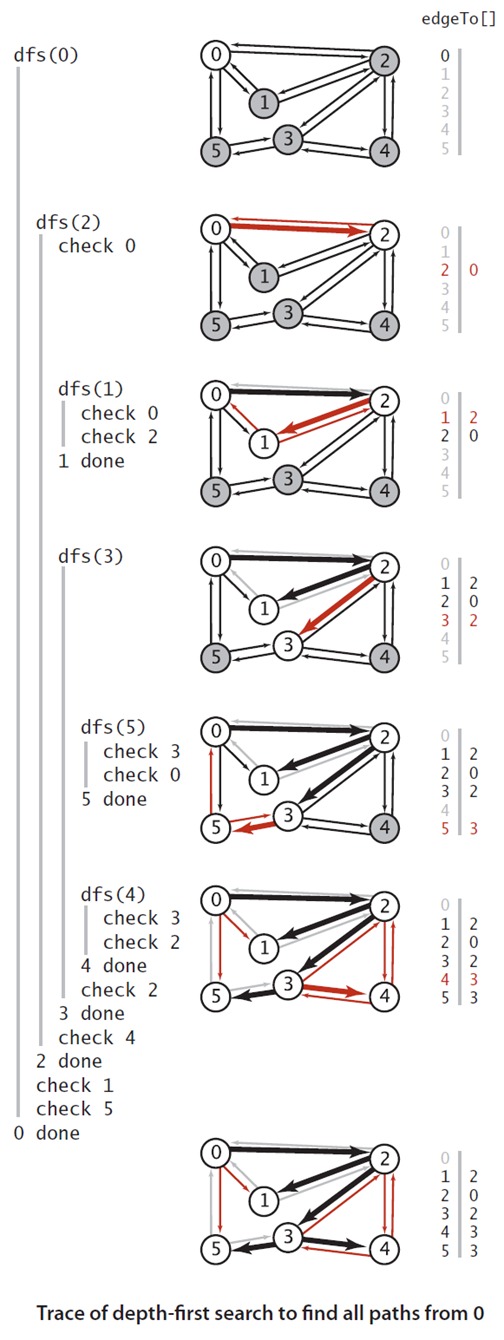
有了这个基础,我们可以实现基于深度优先的路径查询,要实现路径查询,我们必须定义一个变量来记录所探索到的路径。所以在上面的基础上定义一个edgesTo变量来后向记录所有到s的顶点的记录,和仅记录从当前节点到起始节点不同,我们记录图中的每一个节点到开始节点的路径。为了完成这一日任务,通过设置edgesTo[w]=v,我们记录从v到w的边,换句话说,v-w是最后一条从s到达w的边。edgesTo[]其实是一个指向其父节点的树。
public class DepthFirstPaths { private bool[] marked;//记录是否被dfs访问过 private int[] edgesTo;//记录最后一个到当前节点的顶点 private int s;//搜索的起始点 public DepthFirstPaths(Graph g, int s) { marked = new bool[g.GetVerticals()]; edgesTo = new int[g.GetVerticals()]; this.s = s; dfs(g, s); } private void dfs(Graph g, int v) { marked[v] = true; foreach (int w in g.GetAdjacency(v)) { if (!marked[w]) { edgesTo[w] = v; dfs(g,w); } } } public bool HasPathTo(int v) { return marked[v]; } public Stack<int> PathTo(int v) { if (!HasPathTo(v)) return null; Stack<int> path = new Stack<int>(); for (int x = v; x!=s; x=edgesTo[x]) { path.Push(x); } path.Push(s); return path; } }
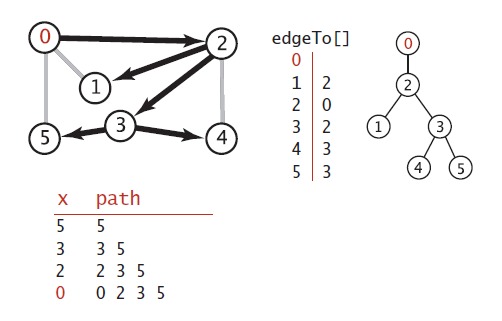
上图中是黑色线条表示深度优先搜索中,所有定点到原点0的路径,他是通过edgeTo[]这个变量记录的,可以从右边可以看出,他其实是一颗树,树根即是原点,每个子节点到树根的路径即是从原点到该子节点的路径。下图是深度优先搜索算法的一个简单例子的追踪。
广度优先算法
通常我们更关注的是一类单源最短路径的问题,那就是给定一个图和一个源S,是否存在一条从s到给定顶点v的路径,如果存在,找出最短的那条(这里最短定义为边的条数最小)。深度优先算法是将未被访问的节点放到一个栈中(stack),虽然在上面的代码中没有明确在代码中写stack,但是递归间接的利用递归堆实现了这一原理。和深度优先算法不同,广度优先是将所有未被访问的节点放到了队列中。其主要原理是:
- 将s放到FIFO中,并且将s标记为已访问
- 重复直到队列为空
- 移除最近最近添加的顶点v
- 将v未被访问的邻接点添加到队列中
- 标记他们为已经访问
广度优先是以距离递增的方式来搜索路径的。
class BreadthFirstSearch { private bool[] marked; private int[] edgeTo; private int sourceVetical;//Source vertical public BreadthFirstSearch(Graph g, int s) { marked=new bool[g.GetVerticals()]; edgeTo=new int[g.GetVerticals()]; this.sourceVetical = s; bfs(g, s); } private void bfs(Graph g, int s) { Queue<int> queue = new Queue<int>(); marked[s] = true; queue.Enqueue(s); while (queue.Count()!=0) { int v = queue.Dequeue(); foreach (int w in g.GetAdjacency(v)) { if (!marked[w]) { edgeTo[w] = v; marked[w] = true; queue.Enqueue(w); } } } } public bool HasPathTo(int v) { return marked[v]; } public Stack<int> PathTo(int v) { if (!HasPathTo(v)) return null; Stack<int> path = new Stack<int>(); for (int x = v; x!=sourceVetical; x=edgeTo[x]) { path.Push(x); } path.Push(sourceVetical); return path; } }
广度优先算法的搜索步骤如下:
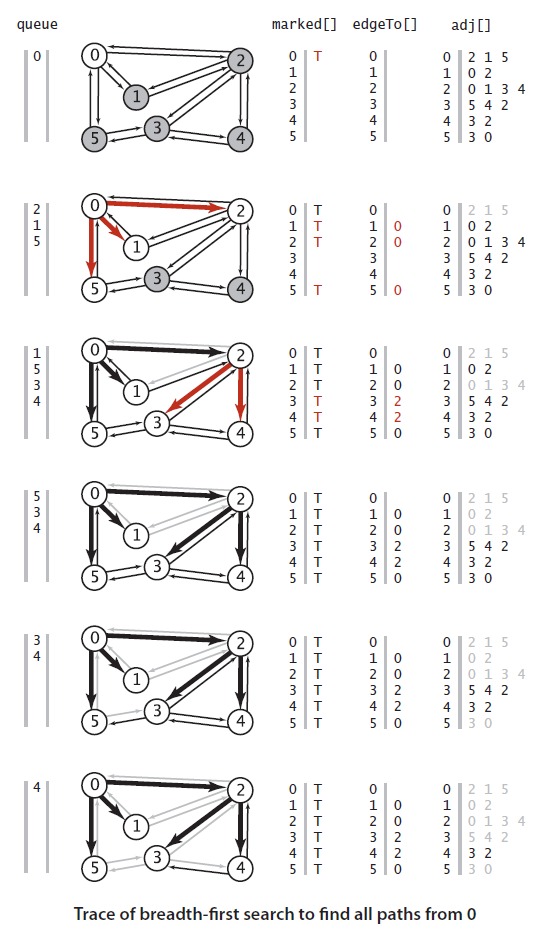
广度优先搜索首先是在距离起始点为1的范围内的所有邻接点中查找有没有到达目标结点的对象,如果没有,继续前进在距离起始点为2的范围内查找,依次向前推进。
连通分量
使用深度优先遍历计算图的所有连通分量。
package Graph; public class CC { private boolean[] marked; private int[] id; private int count; public CC(Graph graph, int s) { marked = new boolean[graph.V()]; id = new int[graph.V()]; for (int i =0; i < graph.V(); i++) { if (!marked(i)) { dfs(graph, i); count++; } } } private void dfs(Graph graph, int s) { marked[s] = true; id[s] = count; for (int W : graph.adj(s)) { if (marked(W)) dfs(graph, W); } } //判断v和W是否连通 public boolean connected(int v, int w) { return id[v] == id[w]; } //返回W所在的连通分量的标识符 public int id(int v) { return id[v]; } public boolean marked(int w) { return marked[w]; } //连通分量 public int count() { return count; } }
总结
本文简要介绍了无向图中的深度优先和广度优先算法,这两种算法时图处理算法中的最基础算法,也是后续更复杂算法的基础。其中图的表示,图算法与表示的分离这种思想在后续的算法介绍中会一直沿用,下文将讲解无向图中深度优先和广度优先的应用,以及利用这两种基本算法解决实际问题的应用。
以上是关于无向图和有向图的详细讲解的主要内容,如果未能解决你的问题,请参考以下文章