爬取全国的城市路口数量
Posted 空城机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取全国的城市路口数量相关的知识,希望对你有一定的参考价值。
在图吧本地生活中https://poi.mapbar.com/


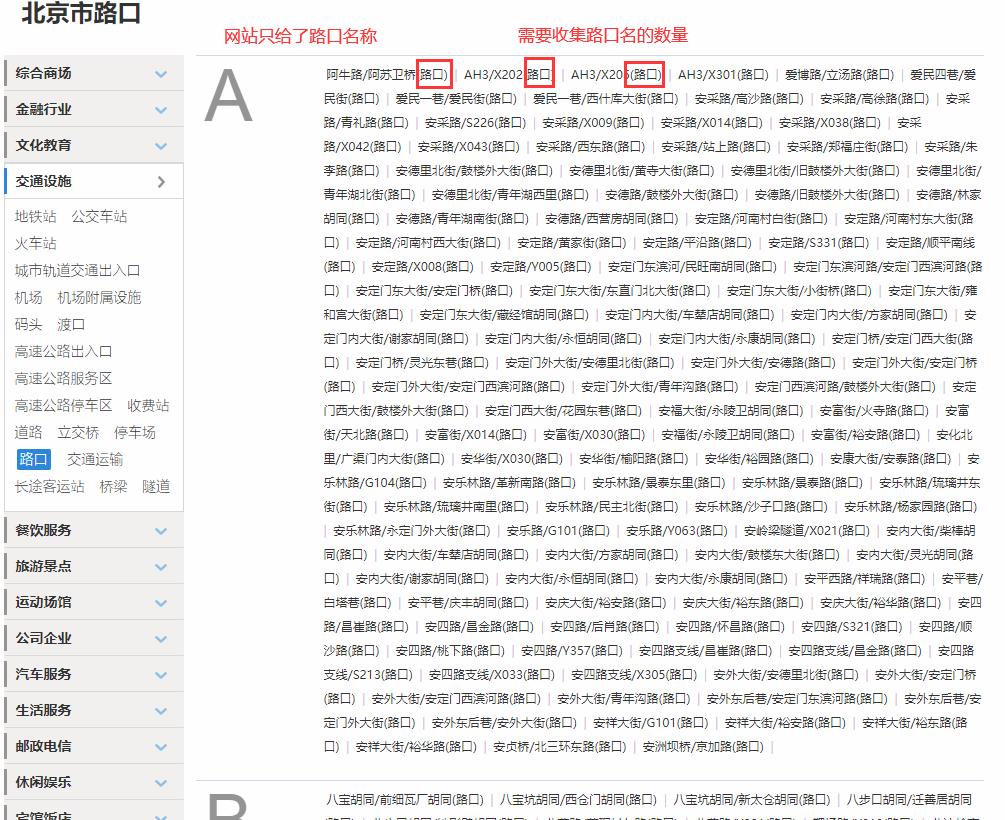
python写方法:
import requests
import re
from lxml import etree
from Roadtest01 import respon
import pymysql
import random
import json
from bs4 import BeautifulSoup
allroads = 0
#ip代理
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = 'http': proxy_ip
return proxies
#数据库提交
def serMySql(n,name,loads):
db = pymysql.connect('localhost', 'root', '**********', 'cityroads')
cursor = db.cursor()
# name = 'cityroad_nums'
# sql = 'select * from '+name
sql = 'insert into cityroad_nums(city_id,city_name,cityroad_nums) values(%s,%s,%s);'
try:
value = (n,name,loads)
print(value)
cursor.execute(sql,value)
# print("****")
db.commit()
# print("成功")
# reslist = cursor.fetchall()
# for row in reslist:
# print('%d--%s--%s--%s' % (row[0], row[1], row[3],row[4]))
# return reslist
except:
print('失败')
# 如果提交失败,回到上一次的数据
db.rollback()
cursor.close()
db.close()
#查询路口数量
def parse(text):
if text!="":
global allroads
#初始化,标准化
html = etree.HTML(text)
#提取我们想要的信息 需要写xpath语法
# 城市名称
# citys = html.xpath('//li[@class="logo"]/a[@class="logo_a"]/text()')
# print(citys)
#路口信息
roads = html.xpath('//div[@class="sortC"]/dl/dd/a/text()')
# print(roads)
# print(len(roads))
allroads += len(roads)
#访问所有的城市
def getName(url):
global allroads
# 请求头,告诉服务器这是浏览器
user_agent_list = [
'Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0)',
'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)',
'Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)',
'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11',
'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
# header =
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
header =
'User-Agent': random.choice(user_agent_list)
#伪造cookie
cookies = dict(uuid='b18f0e70-8705-470d-bc4b-09a8da617e15',
UM_distinctid='15d188be71d50-013c49b12ec14a-3f73035d-100200-15d188be71ffd')
#ip代理:
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
url0 = 'http://www.xicidaili.com/nn/'
ip_list = get_ip_list(url0, headers=headers)
proxies = get_random_ip(ip_list)
# 模拟浏览器发送HTTP请求
response = requests.get(url, headers=header,cookies=cookies,proxies=proxies)
# print(response.text)
# 初始化,标准化
html = etree.HTML(response.text)
names = html.xpath('//dl[@id="city_list"]/dd/a/text()')
# print(names)
urls = html.xpath('//dl[@id="city_list"]/dd/a/@href')
# print(urls)
n = 0
print(n)
for name, href in zip(names, urls):
href += 'GA0/'
name = str(name)
# print(name, href)
# print(name, allroads)
n += 1
print(n,name)
#这里是之前爬取到327我的IP被封了,然后继续爬
if n>327:
text = respon(href)
# 查询路口数量
parse(text)
print(name, allroads)
# print(type(n),type(name),type(allroads))
serMySql(n,name,allroads)
# print(type(href))
allroads = 0
url = 'https://poi.mapbar.com/'
getName(url)
print("结束")
# serMySql(275,"图木舒克市",201)
python检查更新
因为在爬取的过程中遇到了网页中某个城市的路口数量有多页的,这些也的跳转按钮是伪类元素,所以通过更改网页URL来循环遍历
import requests
import re
from lxml import etree
from Roadtest01 import respon
import pymysql
import random
from bs4 import BeautifulSoup
allroads = 0
#ip代理
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = 'http': proxy_ip
return proxies
#数据库更新
def serMySql(n,loads):
db = pymysql.connect('localhost', 'root', '*********', 'cityroads')
cursor = db.cursor()
# name = 'cityroad_nums'
# sql = 'select * from '+name
sql = 'update cityroad_nums set cityroad_nums = %s where city_id = %s;'
try:
value = (loads,n)
print(value)
cursor.execute(sql,value)
print("****")
db.commit()
print("成功")
# reslist = cursor.fetchall()
# for row in reslist:
# print('%d--%s--%s--%s' % (row[0], row[1], row[3],row[4]))
# return reslist
except:
print('失败')
# 如果提交失败,回到上一次的数据
db.rollback()
cursor.close()
db.close()
#检查SQL数据表中cityroad_nums为0的城市
def checkRoads():
db = pymysql.connect('localhost', 'root', '********', 'cityroads')
cursor = db.cursor()
#在数据库中检查是路口数否有为0的城市,然后再重新爬取对比
# sql = 'select city_id from cityroad_nums where cityroad_nums=0 and city_id>285;'
#因为存在伪元素,所以需要把路口9000以上的城市再去做一次排查路口数量
sql = 'select city_id from cityroad_nums where cityroad_nums>9000'
try:
cursor.execute(sql)
# print("成功")
reslist = cursor.fetchall()
# print(type(reslist))
# for row in reslist:
# print('%d' % row[0])
return reslist
except:
print('失败')
# 如果提交失败,回到上一次的数据
db.rollback()
cursor.close()
db.close()
#查询路口数量
def parse(text):
if text!="":
global allroads
#初始化,标准化
html = etree.HTML(text)
#提取我们想要的信息 需要写xpath语法
# 城市名称
# citys = html.xpath('//li[@class="logo"]/a[@class="logo_a"]/text()')
# print(citys)
#路口信息
roads = html.xpath('//div[@class="sortC"]/dl/dd/a/text()')
# print(roads)
# print(len(roads))
allroads += len(roads)
#访问所有的城市
def getName(url):
global allroads
# 请求头,告诉服务器这是浏览器
user_agent_list = [
'Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0)',
'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)',
'Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)',
'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11',
'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
# header =
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
header =
'User-Agent': random.choice(user_agent_list)
#伪造cookie
cookies = dict(uuid='b18f0e70-8705-470d-bc4b-09a8da617e15',
UM_distinctid='15d188be71d50-013c49b12ec14a-3f73035d-100200-15d188be71ffd')
#ip代理:
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
url0 = 'http://www.xicidaili.com/nn/'
ip_list = get_ip_list(url0, headers=headers)
proxies = get_random_ip(ip_list)
# 模拟浏览器发送HTTP请求
response = requests.get(url, headers=header,cookies=cookies,proxies=proxies)
# print(response.text)
# 初始化,标准化
html = etree.HTML(response.text)
names = html.xpath('//dl[@id="city_list"]/dd/a/text()')
# print(names)
urls = html.xpath('//dl[@id="city_list"]/dd/a/@href')
# print(urls)
n = 0
# print(n)
for name, href in zip(names, urls):
href += 'GA0/'
name = str(name)
# print(name, href)
# print(name, allroads)
n += 1
lists = checkRoads()
for row in lists:
if n == row[0]:
#城市的英文名
ename = re.findall(r"com/(.+?)/GA0/",href)
print(n, name, href,ename[0])
for i in range(1, 5):
# print(n)
cityUrl(ename[0],i)
print(allroads)
# text = respon(href)
# # 查询路口数量
# parse(text)
# print(n,name,allroads)
serMySql(n, allroads)
allroads = 0
def cityUrl(ename,n):
url = f'https://poi.mapbar.com/ename/GA0_n/'
print(url)
text = respon(url)
parse(text)
url = 'https://poi.mapbar.com/'
getName(url)
print("结束")
# lists = checkRoads()
# for row in lists:
# print('%d' % row[0])
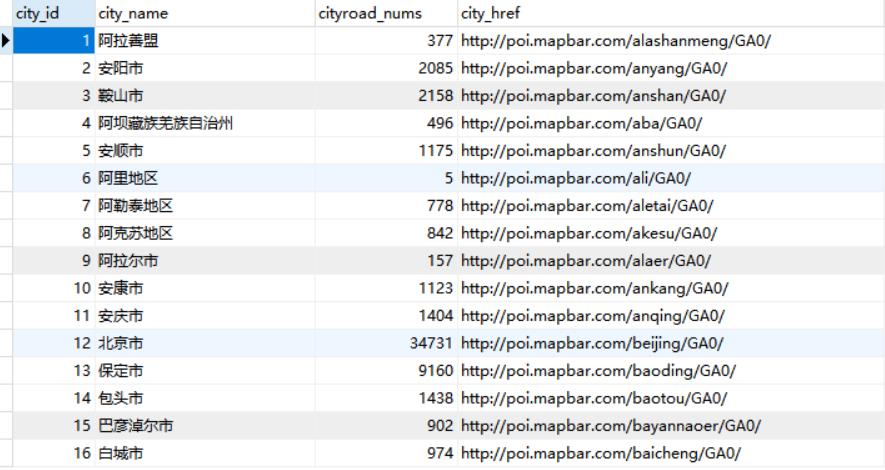
最终爬取的效果
城市名称和城市的中路口数量,以及该城市爬取的网址
一起学习,一起进步 -.- ,如有错误,可以发评论
以上是关于爬取全国的城市路口数量的主要内容,如果未能解决你的问题,请参考以下文章