多智能体强化学习:合作关系设定下的多智能体强化学习
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多智能体强化学习:合作关系设定下的多智能体强化学习相关的知识,希望对你有一定的参考价值。
0 前言
在多智能体系统中,一个智能体未必能观测到全局状态 S。设第 i 号智能体有一个局部观测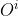 ,它是S的一部分。
我们假设所有的局部观测的总和构成了全局状态
,它是S的一部分。
我们假设所有的局部观测的总和构成了全局状态

1 合作关系设定下的策略学习
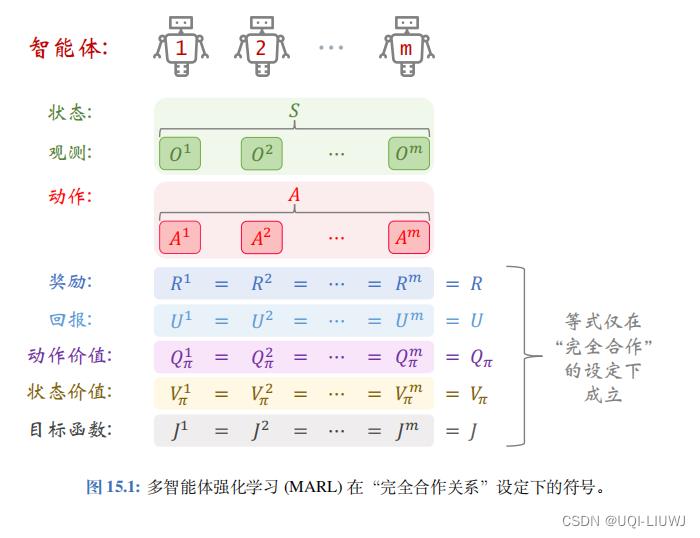
MARL 中的 完全合作关系 (Fully-Cooperative) 意思是所有智能体的利益是一致的,它们具有相同的奖励:因此,所有的智能体都有 相同的回报 :
因为价值函数是回报的期望,所以所有的智能体都有相同的(状态/动作)价值函数
和
。
注意

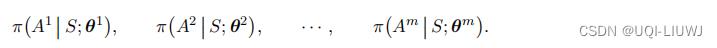
合作关系设定下的策略学习的原理很简单,即让智能体各自做策略梯度上升,使得目标函数 J 增长。如果做策略学习(即学习策略网络参数
),那么所有智能体都有一个共同目标函数:
所有智能体的目的是一致的,即改进自己的策略网络参数
,使得目标函数 J 增大。那么策略学习可以写作这样的优化问题:
注意,只有“完全合作关系”这种设定下,所有智能体才会有共同的目标函数,其原因在于
对于其它设定——“竞争关系”、“混合关系”、“利己主义”—— 智能体的目标函数是各不相同的


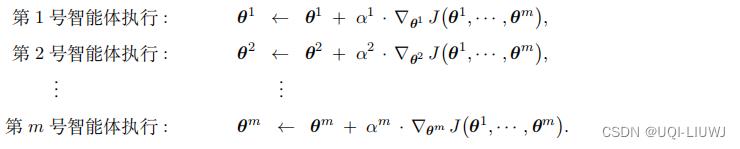
判断策略学习收敛的标准是目标函数 不再增长。。
在实践中,当平均回报不再增长,即可终止算法。
由于无法直接计算策略梯度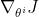 ,我们需要对其做近似。
,我们需要对其做近似。
2 合作设定下的多智能体 A2C
强化学习笔记:带基线的策略梯度_UQI-LIUWJ的博客-CSDN博客
“完全合作关系”设定下的多智能体 A2C 方法 (Multi-Agent Cooperative A2C) ,缩写 MAC-A2C 。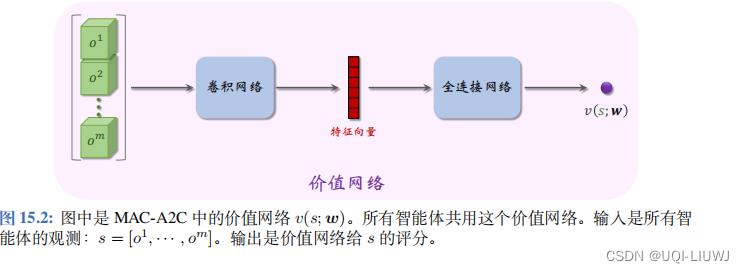
2.1 策略网络和价值网络
本章只考虑离散控制问题,即动作空间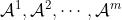 都是离散集合。
MAC-A2C
使用
两类神经网络
:价值网络
v
与策略网络
π
;
所有智能体共用一个价值网络
,记作
v
(
s
;
w
),它是对状态价值函数
都是离散集合。
MAC-A2C
使用
两类神经网络
:价值网络
v
与策略网络
π
;
所有智能体共用一个价值网络
,记作
v
(
s
;
w
),它是对状态价值函数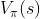 的近似。 它把所有观测
的近似。 它把所有观测 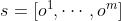 作为输入,并输出一个实数,作为对状态 s
的评分。
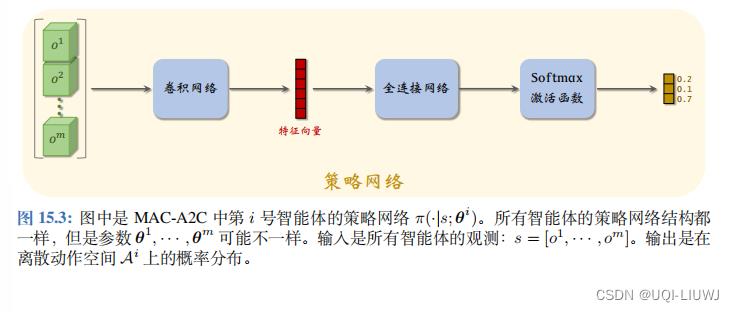
每个智能体有自己的策略网络。
把第 i 号策略网络记作
作为输入,并输出一个实数,作为对状态 s
的评分。
每个智能体有自己的策略网络。
把第 i 号策略网络记作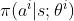 。它的输入是所有智能体的观测 。它的输出是一个向量,表示动作空间
。它的输入是所有智能体的观测 。它的输出是一个向量,表示动作空间
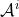 上的概率分布。
上的概率分布。
2.1.1 训练价值网络
我们用 TD 算法训练价值网络 v(s; w)。观测到状态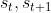 和奖励 rt,计算 TD 目标:
和奖励 rt,计算 TD 目标:

定义损失函数:


2.1.2 训练策略网络

把基线设置为状态价值:
,然后定义
这是策略梯度的无偏估计:
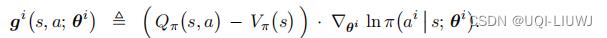
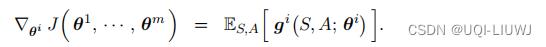
此时我们还不知道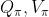
和A2C强化学习笔记:带基线的策略梯度_UQI-LIUWJ的博客-CSDN博客类似,我们把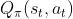 近似成
近似成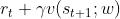 ,把
,把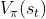 近似成
近似成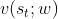
于是近似策略梯度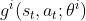 可以进一步近似成
可以进一步近似成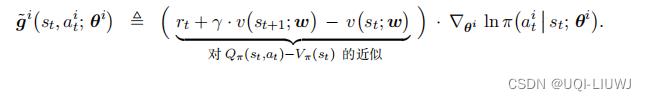

3 整体训练流程
实际实现的时候,应当使用目标网络缓解自举造成的偏差。 目标网络记作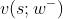 ,它的结构与 v
相同,但是参数不同。
设当前价值网络和目标网络的参数分别是
,它的结构与 v
相同,但是参数不同。
设当前价值网络和目标网络的参数分别是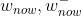 。
。
设当前 m 个策略网络的参数分别是
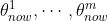 。
MAC-A2C
重复下面的步骤更新参数:
。
MAC-A2C
重复下面的步骤更新参数:

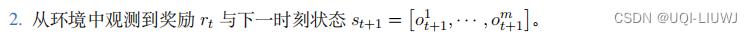
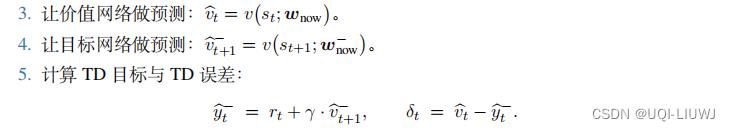
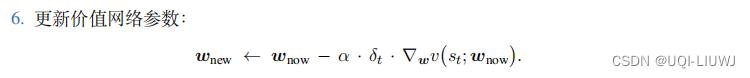
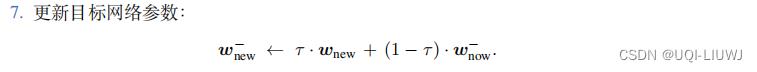
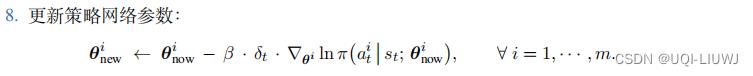
MAC-A2C 属于同策略 (On-policy),不能使用经验回放。
4 决策与控制
在完成训练之后,不再需要价值网络 v(s; w)。每个智能体可以用它自己的策略网络做决策。
在时刻 t 观测到全局状态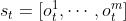 ,然后做随机抽样得到动作
,然后做随机抽样得到动作
5 实现中的难点
在 MARL 的常见设定下,第 i 号智能体只知道自己的观测值要做训练和决策,有两种可行的途径:,而观测不到全局状态:
但是全局状态在多智能体A2C中又是必须的:
所以, 如果智能体之间不交换信息,那么智能体既无法做训练,也无法做决策。
- 每个智能体有自己的策略网络
- 在训练的过程中,价值网络 v(s; w) 需要知道全局状态 s 才能计算 TD 误差 与梯度
- 在训练的过程中,每个策略网络都需要知道全局状态s来计算梯度
- 一种办法是让智能体共享观测。这需要做通信,每个智能体把自己的传输给其他智能体
- 这样每个智能体都有全局的状态
- 这样每个智能体都有全局的状态
- 另一种办法是对策略网络和价值函数做近似。通常使用
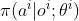 替代。 甚至可以进一步用
替代。 甚至可以进一步用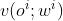 代替 v(s; w)。
代替 v(s; w)。
但是他们都是有不足之处的:
- 共享观测的缺点在于通信会让训练和决策的速度变慢。
- 而做近似的缺点在于不完全信息 造成训练不收敛、做出错误决策。
6 三种实现架构
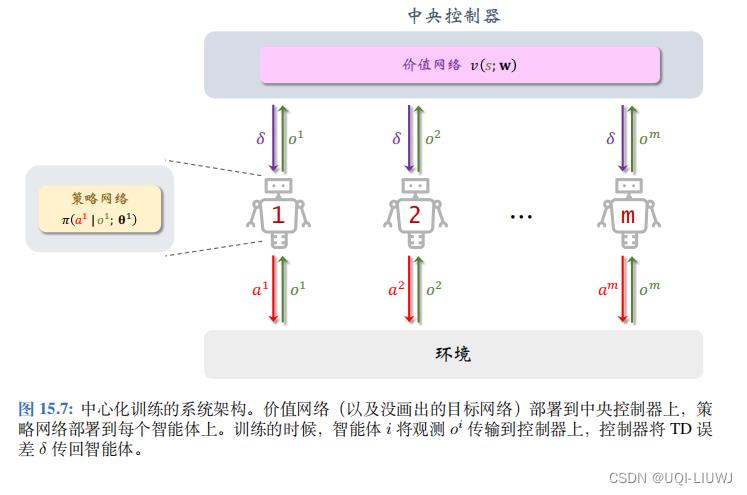
6.1 中心化训练+中心化决策
本小节用完全中心化 (Fully Centralized) 的方式实现 MAC-A2C ,没有做任何近似。 这种实现的缺点在于通信造成延时,使得训练和决策速度变慢。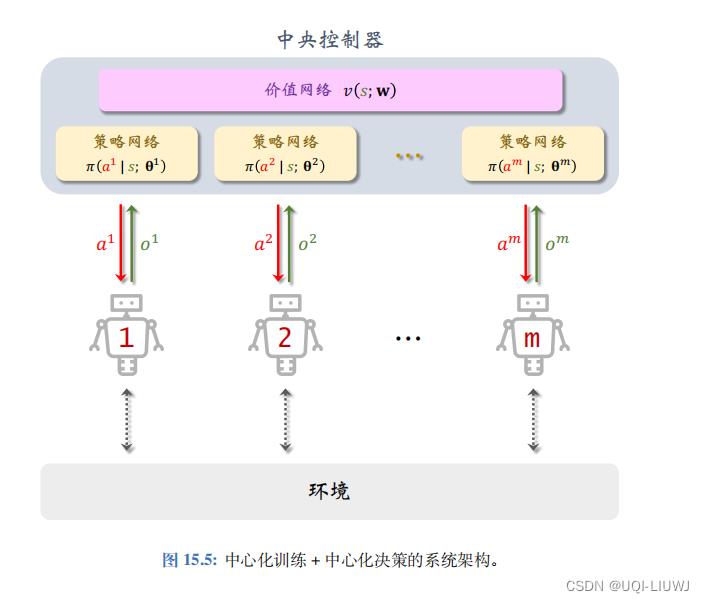
最上面是中央控制器 (Central Controller),里面部署了价值网络 v(s; w) 与所有 m 个策略网络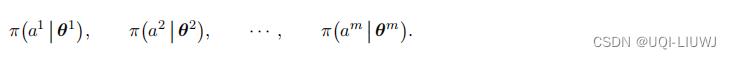 训练和决策全部由中央控制器完成。智能体负责与环境交互,执行中央控制器的决策
训练和决策全部由中央控制器完成。智能体负责与环境交互,执行中央控制器的决策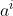 并把观测到的汇报给中央控制器。如果智能体观测到奖励
并把观测到的汇报给中央控制器。如果智能体观测到奖励 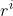 ,也发给中央控制器。
,也发给中央控制器。
6.1.1 中心化训练
在时刻 t 和 t + 1,中央控制器收集到所有智能体的观测值
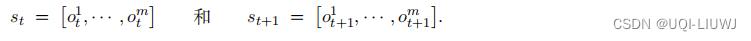
在“完全合作关系”的设定下,所有智能体有相同的奖励:

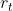 可以是中央控制器直接从环境中观测到的,也可能是所有智能体本地的奖励
可以是中央控制器直接从环境中观测到的,也可能是所有智能体本地的奖励 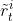 的加和:
的加和:
决策是中央控制器上的策略网络做出的,中央控制器因此知道所有的动作:
——> 中央控制器知道
——> 因此,中央控制器有足够的信息训练 MAC-A2C,更新价值网络的参数 w 和策略网络的参数
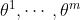 【训练方法见第三小节】
【训练方法见第三小节】
6.1.2 中心化决策
在 t 时刻,中央控制器收集到所有智能体的观测值,然后用中央控制器上部署的策略网络做决策:
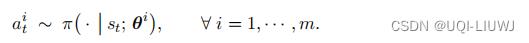 中央控制器把决策
中央控制器把决策 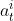 传达给第
i 号智能体,该智能体执行。综上所述,智能体只需要执行中央下达的决策,而不需要自己“思考”。
传达给第
i 号智能体,该智能体执行。综上所述,智能体只需要执行中央下达的决策,而不需要自己“思考”。
6.1.3 完全中心化的优缺点
中心化训练 + 中心化决策的 优点 在于完全按照 MAC-A2C 的算法实现,没有做任何改动,因此可以确保正确性。 基于全局的观测做中心化的决策, 利用完整的信息,因此作出的决策可以更好。
中心化训练和决策的 缺点 在于延迟 (Latency) 很大,影响训练和决策的速度。 在中心化执行的框架下,智能体与中央控制器要做通信。 第 i 号智能体要把
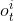 传输给中央控制器,而控制器要在收集到所有观测
[之
后才会做决策,做出的决策 还得传输给第
i
号智能体。
这个过程通常比较慢,使得实时决策不可能做到。
机器人、无人车、无人机等应用都需要实时决策,比如在几十毫秒内做出决策;如果出现几百毫秒、甚至几秒的延迟,可能会造成灾难性的后果。
传输给中央控制器,而控制器要在收集到所有观测
[之
后才会做决策,做出的决策 还得传输给第
i
号智能体。
这个过程通常比较慢,使得实时决策不可能做到。
机器人、无人车、无人机等应用都需要实时决策,比如在几十毫秒内做出决策;如果出现几百毫秒、甚至几秒的延迟,可能会造成灾难性的后果。
6.2 去中心化训练+去中心化决策
“中心化训练 + 中心化决策”严格按照 MAC-A2C 的算法实现,其缺点 在于训练和决策都需要智能体与中央控制器之间通信,造成训练的决策的速度慢。
想要避免通信代价,就不得不对策略网络和价值网络做近似。
MAC-A2C 中的策略网络
和价值网络 v(s; w) 都需要全局的观测
“去中心化训练 + 去中心化决 策”的基本思想是用局部观测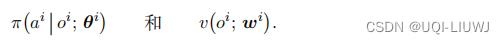
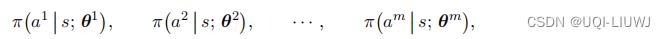
在每个智能体上部署一个策略网络和一个价值网络,它们的参数记作
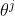 和
和
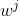 。
智能体之间不共享参数
。
智能体之间不共享参数 这样一来,训练就可以在智能体本地完成,无需中央控制器的参与,无需任何通信。
这样一来,训练就可以在智能体本地完成,无需中央控制器的参与,无需任何通信。
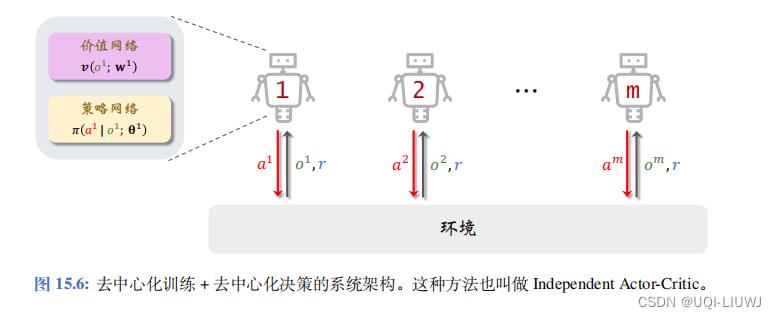
6.2.1 去中心化训练
假设所有智能体的奖励都是相同的,而且每个智能体都能观测到奖励 r 。 每个智能体独立做训练,智能体之间不做通信,不共享观测、动作、参数。 这样一 来, MAC-A2C 就变成了标准的 A2C ,每个智能体独立学习自己的参数
实际实现的时候,每个智能体还需要一个目标网络,记作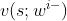 ,它的结构与
,它的结构与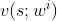 相同,但是参数不同。
相同,但是参数不同。
设第 i 号智能体的策略网络、价值网络、目标网络当前参数分别为
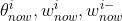 。该智能体重复以下步骤更新参数:
。该智能体重复以下步骤更新参数:


不难发现,上面的这一套训练流程和单智能体的A2C类似。
去中心化训练的本质就是单智能体强化学习 (SARL) ,而非多智能体强化学习 (MARL) 。 在 MARL 中,智能体之间会相互影响,而本节中的“去中心化训练”把智能体视为独立个体,忽视它们之间的关联,直接 用 SARL 方法独立训练每个智能体。 用上述 SARL 的方法解决 MARL 问题, 在实践中效果往往不佳 。6.2.2 去中心化决策
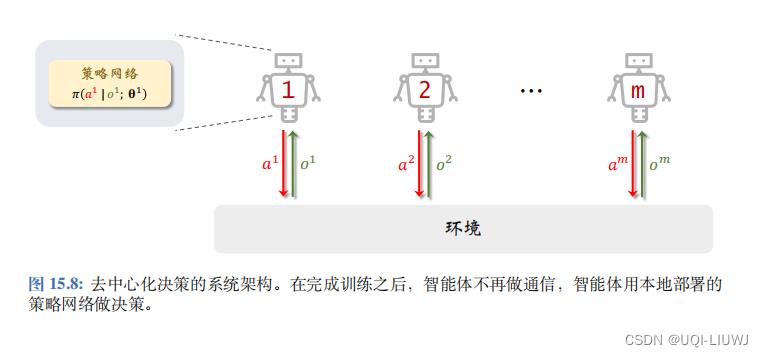
完成训练后,智能体只需要用其本地部署的策略网络做决策即可,决策过程无需通信。
去中心化执行的速度很快,可以做到实时决策。
6.3 中心化训练+去中心化决策
- 前面小两节讨论了完全中心化与完全去中心化,两种实现各有优缺点。当前更流行的MARL 架构是“中心化训练 + 去中心化决策”。
- 训练的时候使用中央控制器,辅助智能体做训练;见图 15.7。
- 训练结束之后,不再需要中央控制器,每个智能体独立根据本地观测
本小节与“完全中心化”使用相同的价值网络 v(s; w) 及其目标网络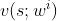 ;
;
本小节与“完全去中心化”使用相同的策略网络: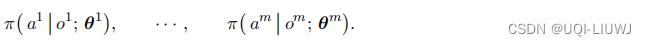
第 i 号策略网络的输入是局部观测 ,因此可以将其部署到第 i 号智能体上。
价值网络 v(s; w) 的输入是全局状态,因此需要将其部署到中央控制器上。
6.3.1 中心化训练
训练的过程需要所有 m 个智能体共同参与,共同改进策略网络参数与价值网络参数 w。
设当前价值网络和目标网络的参数分别是。训练的流程如下:

(和去6.2中心化训练类似)
和6.1中心化训练类似

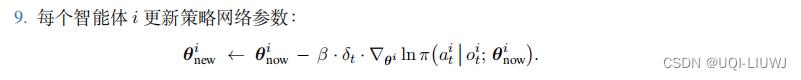
6.3.2 去中心化决策
在完成训练之后,不再需要价值网络 v ( s ; w)。智能体只需要用本地部署的策略网络
做决策,决策过程无需通信。去中心化执行的速度很快, 可以做到实时决策。
以上是关于多智能体强化学习:合作关系设定下的多智能体强化学习的主要内容,如果未能解决你的问题,请参考以下文章
MAGNet: 面向深度多智能体强化学习(MADRL)的多智能体图网络(Graph Network)
前沿 | DeepMind提出新型架构IMPALA:帮助实现单智能体的多任务强化学习