强化学习|多智能体深度强化学习(博弈论—>多智能体强化学习)
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习|多智能体深度强化学习(博弈论—>多智能体强化学习)相关的知识,希望对你有一定的参考价值。
1 简介
近年来,AlphaGo代表的“决策智能备受关注”,即将来临的物联网时代,群体决策智能将成为另一个研究重点。
说到群体决策智能,就免不了提及博弈论。博弈论研究的是多个智能体的理性决策问题。它定义了动作、收益等博弈的基本概念,侧重分析理性智能体的博弈结果,即均衡。
然而,在很多现实问题中,博弈的状态空间和动作空间都很大,智能体的绝对理性很难实现,智能体往往处在不断的策略学习过程中。近年来兴起的多智能强化学习主要研究智能体策略的同步学习和演化问题。
人工智能发展趋势:

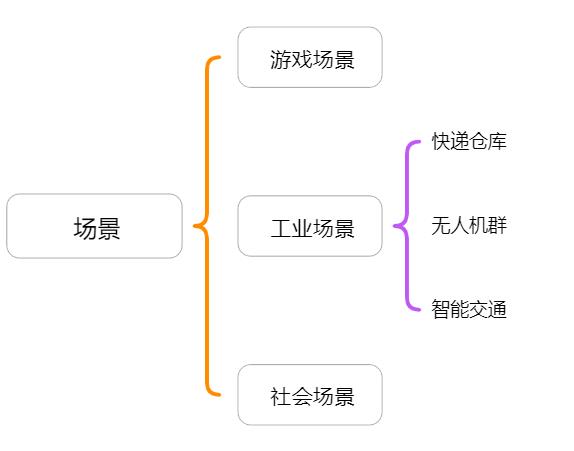
应用场景:
2 博弈论基础知识简介
2.1 囚徒困境
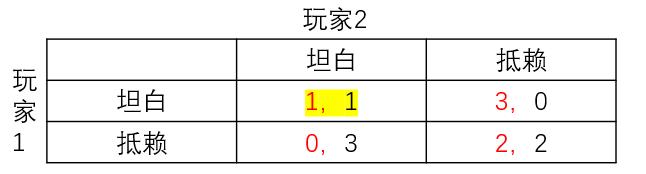
基本假设:
(1)两个玩家同时决策
(2)玩家知道所有博弈元素
(3)玩家是理性的,追求自身利益最大化
占优策略(Dominant Strategy):
无论对方采取什么策略,对己方都最优的策略
如:
(1)若玩家2选坦白:玩家1选坦白得1分优于抵赖得0分
(2)若玩家2选抵赖:玩家1选坦白得3分优于抵赖得2分
由此:无论玩家2选什么,玩家1选坦白都更优,坦白是玩家1的占优策略。
策略推测:
博弈结果:
(1)坦白是player 1 的占优策略
(2)坦白是player 1 的占优策略
博弈结果:坦白——坦白
最佳应对(best-response)
(1)坦白是player 1 的占优策略
(2)坦白是player 1 的最佳应对
博弈结果:坦白——坦白
2.2 博弈的解
2.2.1 纳什均衡(Nash Equilibrium)
任何玩家都不能通过独自改变策略而获益的策略组合,即所有玩家都处于最佳应对的策略组合。
数学定义:

2.2.2 混合策略纳什均衡(Mix Strategy Nash Equilibrium)
混合策略:一个概率分布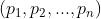 ,
,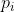 表示选择动作
表示选择动作 的概率
的概率
混合策略的纳什均衡:一个混合策略,任何玩家都不能通过独自改变混合策略而使自身期望收益提高。
任何一个博弈,必然存在一个纳什均衡。
2.2.3 Stackelberg均衡
改变了一个基本假设:玩家的行动有先后次序
定义:在规定了行动先后次序的情况下,任何玩家都不能通过自身改变策略而获益的策略组合。
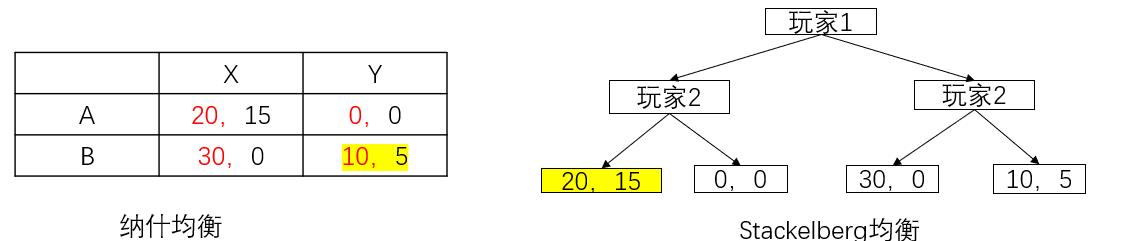
如下,展示了纳什均衡和Stackelberg下的均衡情况,在有先后顺序下,两个的均衡解是不一样的。
2.3 协同问题
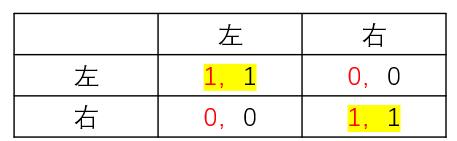
多个均衡,如何选取?如下两种博弈都是有多个均衡的情况,左边的是两车会车的情况,两车都选左和都选右,那就能过得去,否则就撞车了,右边是斗车的情况,一辆变道就都不会碰撞,于是纳什均衡也有两个,也就是其中一辆车主动变道。

那么到底该如何选取呢?这种问题是无法在基本假设的清苦下去选取的,那么只好修改基本设定,例如:引入通讯机制,商议一下;或者设定一些社会规则,以此使得两方达到好的均衡。
2.4 特殊的博弈:合作与竞争*(特殊但常见)
2.4.1 合作博弈(Cooperative Game)
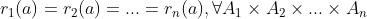
2.4.2 竞争博弈(Coorpetitive Game)
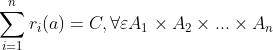
4 多智能体强化学习
4.1现实中的博弈
(1)状态、动作空间大
(2)博弈元素不完全可知
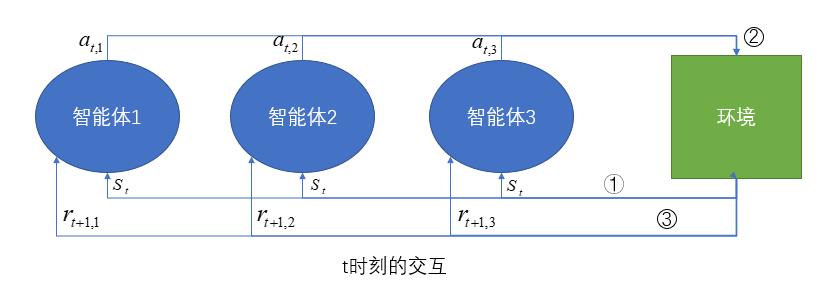
4.2马尔科夫博弈(Markov Game)
(1)玩家集合
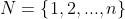
(2)状态集合:
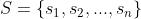
(3)动作集合
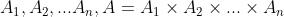
(4)转移函数
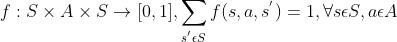
(5)收益函数
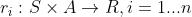
4.3强化学习
强化学习分为三种形式:
(1)基于价值:Q-learning,Sarsa、DQN——在s状态下基于价值选择动作
Q-learning是off-policy(离线学习)的算法,因为让Q-table的更新可以不基于正在经历的经验,Q-learning每次在更新的时候选取的是最大化Q的方向,而当下一个状态时,再重新选择动作,Q-learning是一种鲁莽、大胆、贪婪的算法.
更新公式为: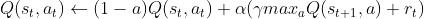
Sarsa是on-policy(在线学习)的算法,必须本人在场,并且本人边玩边学。Sarsa选取的是一种保守的策略,他在更新Q值的时候已经为未来规划好了动作,对错误和死亡比较敏感。
更新公式为: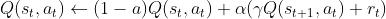
DQN:用神经网络拟合Q函数。
文献推荐:[1]Volodymyr Mnih et al."Human-level control through deep reinforcement learning" [Nature]
(2)基于概率:Policy Gradient——在s状态下基于概率选择动作
策略梯度更新公式: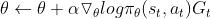
(3)两者融合——Actor_Critic:
Actor:基于概率作出动作
Critic:对所做的动作给出动作值
更新公式: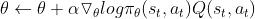
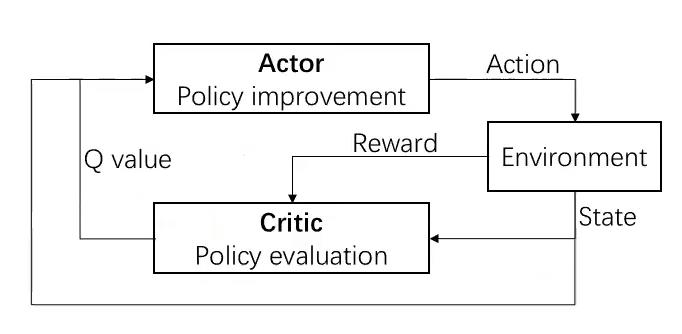
4.4 多智能强化学习学习目标:均衡
4.4.1 Nash Q-learning
纳什均衡求解:单个状态,多个玩家
Q学习:多个状态,单个玩家
Nash Q-learning=纳什均衡求解+Q学习:多个状态,多个玩家

文献推荐:[2]Junling Hu,et al."Nash Q-Learning for General-Sum Stochastic Games" [JMLR 2003]
4.4.2 Stackelberg均衡学习
推荐文献:
[3]Haifeng Zhang,et al."Bi-level Actor_Critic for Multi-Agent Coordination"[AAAI 2020]
论文阅读|《Bi-level Actor-Critic for Multi-agent Coordination》(AAAI 2020)(附带源码链接)
[4]解易,顾益军.基于Stackelberg策略的多Agent强化学习警力巡逻路径规划[J].北京理工大学学报,2017,37(1):93-99.
拿文献【4】以简单解释:
问题:巡逻路径规划问题——存在攻击者和防御者两种Agent。
攻击者的任务是攻击目标,并由此获得收益.攻击需要经过3个离散时间节点才能完成.攻击 者成功完成一次攻击后,可以继续行动.防御者的任务是在攻击者成功攻击之前中止其攻击行为 以获得收益.防御者在中止攻击者的同时将其抓获,使其无法继续其他的行动.在所有攻击者被 抓获后,巡逻问题进入终止状态.
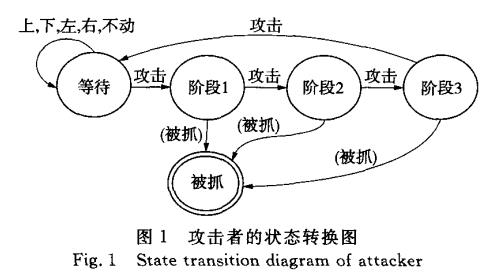
攻击者的行为空间为{上,下,左,右,不动,攻击),状态空间为S={等待 ,阶段 1,阶段 2,阶段 3,被抓},防御者的行为空间为 {上,下,左,右,不动},状态空间同样。
目标:求解最大化防御者的折扣收益和期望的巡逻。
为什么采用Stackelberg均衡进行巡逻规划:
首先,分析一下应用Nash均衡求解该问题存在的两个缺点:
(1)因为巡逻路径规划任务需要规划确定的路径,所以训练得到的策略是纯策略,也就是在一定状态下,以概率1选择的策略,而混合Nash均衡策略才能保证,在某些情况下,Nash-Q-Learning找不到均衡策略。
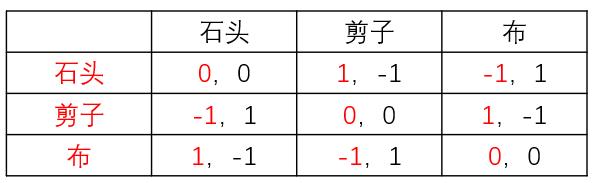
(2)在真实的攻击者-防御者对抗中,对方不会像玩石头剪刀布一样同时采取行动。防御者往往先采取行动,然后攻击者根据防御者的行为选择最有利的行为,如此交替进行。
4.5 学习目标二:协同
推荐文献: [5] Ying Wen,et al."Probalistic Recursive Reasoning for Multi-Agent Reinforcement"(ICLR 2019)
4.6 学习目标三:合作
推荐文献:[6] Ying Wen,et al."Multiagent Bidirectionally-coordinated Nets:Emergence of Human-level coordination in learning to play starcraft combat Games"(NIPS 2017)
以上是关于强化学习|多智能体深度强化学习(博弈论—>多智能体强化学习)的主要内容,如果未能解决你的问题,请参考以下文章