MAGNet: 面向深度多智能体强化学习(MADRL)的多智能体图网络(Graph Network)
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MAGNet: 面向深度多智能体强化学习(MADRL)的多智能体图网络(Graph Network)相关的知识,希望对你有一定的参考价值。
《MAGNet:Multi-agent Graph Network for Deep Multi-agent Reinforcement Learning》
[2012.09762] MAGNet: Multi-agent Graph Network for Deep Multi-agent Reinforcement Learning (arxiv.org) https://arxiv.org/abs/2012.09762 这篇文章提出了一种新的多智能体强化学习方法,称为MAGNet,它利用了通过自我注意机制获得的环境的关联图表示和消息生成技术,将MAGNet应用于synthetic predator-prey 多智能体环境和Pommerman博弈,结果表明它的性能明显由于最新的MARL解决方案,包括MADQN、MADDPG、QMIX。
https://arxiv.org/abs/2012.09762 这篇文章提出了一种新的多智能体强化学习方法,称为MAGNet,它利用了通过自我注意机制获得的环境的关联图表示和消息生成技术,将MAGNet应用于synthetic predator-prey 多智能体环境和Pommerman博弈,结果表明它的性能明显由于最新的MARL解决方案,包括MADQN、MADDPG、QMIX。
1 介绍
在多智能体环境中,强化学习的一个常见困难时,实现智能体之间的完美合作,智能体需要环境与自己和其他智能体的相关信息。
本文提出的MAGNet,是以关联图的形式学习这些关联信息,并将其融入强化学习过程中。该方法分为两个阶段进行。在第一阶段,学习关联图;在第二阶段,该图与状态信息一起送到Actor-Critic 强化学习网络,该网络负责主体的决策,并结合了沿关联图的消息传递技术。
下面介绍几种多智能体强化学习算法:
1.1 Multi-agent Deep Q-Networks
MADQN:
[2109.04986] Multi-agent deep reinforcement learning (MADRL) meets multi-user MIMO systems (arxiv.org)https://arxiv.org/abs/2109.04986 多Agent深度Q网络方法通过两个重复步骤中执行训练来修改多Agent系统这一过程,首先,他们一次训练一个Agent,同时保持其他Agent的策略固定。当Agent完成训练后,它会将其策略作为一个额外的环境变量分发给其他Agent.
1.2 Multi-agent Deep Deterministic Policy Gradient
当处理连续动作空间时,上述MADQN方法不能应用,为克服这一局限,提出了Actor-Critic。
DDPG:
MADDPG:
1.3 QMIX
最近另一种有前途的深度多智能体强化学习方法是QMIX。它对每个智能体使用单独的Q函数,对一组智能体使用联合Q函数。QMIX体系结构由三种类型的神经网络组成,Agent网络(Agent Network)为接受当前观察和先前操作的Agent评估单个Q函数,混合网络(Mixing Network)将Agent网络中的单个Q函数和当前状态作为输入,然后计算所有Agent的联合Q函数,超级网络(Hyper Network)增加了混合网络的复杂性。超级网络不是直接将当前状态传递给混合网络,而是将其作为输入并计算混合网络每一层的权重乘数。我们请读者参考原文以获得更完整的解释。
2 MAGNet算法和体系架构
下图为MAGNet方法的总体网络架构。整个过程可分为关联图生成阶段(左图)和决策阶段(右图)。在此体系结构中,当前状态和前一个操作的连接形成了模型的输入,而输出则是下一个操作。下面描述这两个过程的细节。
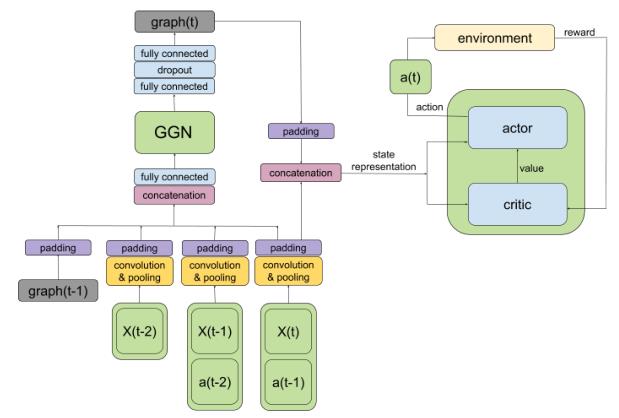
2.1 关联图生成阶段
MAGNet方法的第一部分中,训练神经网络生成一个相关图,该图用数值矩阵|A| ×(|A|+|O|)表示,其中|A|是agent的数量,|O|是给定的环境对象的最大数量.关联图表示Agent之间以及Agent与环境之间的关系,Agent A和另Agent B或环境对象之间的边的绝对权重越高,对Agent A任务的完成就越重要。
训练关联图有两种选择:(1)为每个Agent单独训练关联图;(2)为团队中的所有Agent训练一个相同的共享图(GS)。
2.2 决策阶段
负责决策的Agent AI被表示为一个神经网络,其输入是累积的消息和环境的当前状态。网络的输出是要执行的动作。此操作通过消息传递系统分4个步骤计算。
step 1:通过神经网络将个体(即特定于位置的)观测数据预处理为信息向量(表示为数值向量)。该神经网络是随机初始化的,并在整个学习过程中使用相同的全局损失函数进行训练。
step 2:神经网络(也经过训练)获取Agent的信息向量,并将其映射为消息(也是数值向量),每个消息对应于关联图中每个连接的顶点类型。该消息与相应边的权重相乘,并传递给相应的顶点。
step 3:关联图中的每个agent或对象更新其信息向量,同样使用一个训练过的网络,基于传入的消息和之前的信息向量。
step 4 输出动作
由于消息传递系统输出一个动作,我们将其视为DDPG Actor-Critic算法[9]中的一个Actor,并对其进行相应的训练。
初始化消息向量:每个顶点都有一个初始化网络
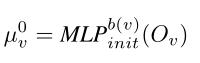
消息生成:消息生成根据每条边输出消息,然后乘以相关图中相应边的权值:
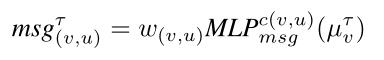
消息处理:该网络将所有传入的消息向量与上一步得到的信息向量相加作为输入:
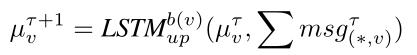
动作选择:
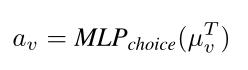
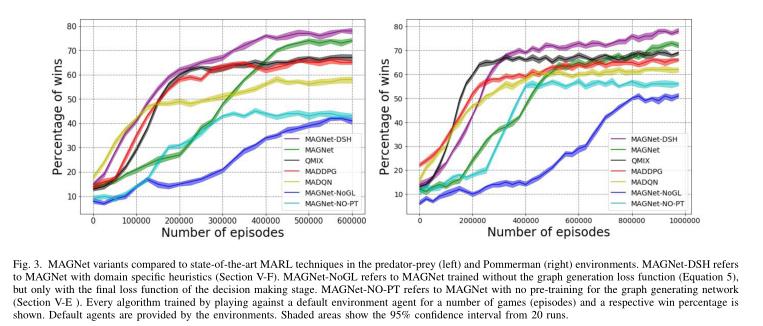
3 实验
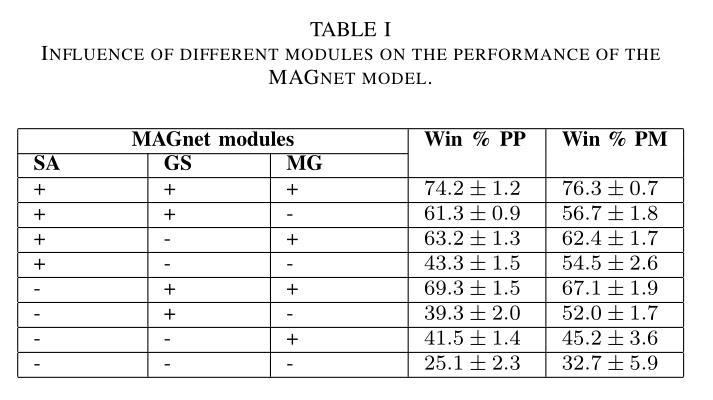
其中,SA:self-attention;GS:graph sharing;MG:message generation
以上是关于MAGNet: 面向深度多智能体强化学习(MADRL)的多智能体图网络(Graph Network)的主要内容,如果未能解决你的问题,请参考以下文章
强化学习|多智能体深度强化学习(博弈论—>多智能体强化学习)