前沿 | DeepMind提出新型架构IMPALA:帮助实现单智能体的多任务强化学习
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前沿 | DeepMind提出新型架构IMPALA:帮助实现单智能体的多任务强化学习相关的知识,希望对你有一定的参考价值。
选自DeepMind
机器之心编译
参与:路雪、李泽南
深度强化学习(DeepRL)在很多任务中取得了成功,从机器人的连续控制问题到围棋、Atari 等游戏。不过这些领域中的进步还限制在单个任务,即在单个任务中对智能体进行调整和训练。DeepMind 最近提出的 IMPALA 开始尝试利用单智能体同时处理多个任务,其架构性能超越此前方法数倍,具有强大的可扩展性,同时也展示了积极的迁移性质。与新架构同时提出的还有任务集合 DMLab-30。
项目 GitHub:https://github.com/deepmind/lab/tree/master/game_scripts/levels/contributed/dmlab30
DeepMind 近期的研究尝试探索在多个任务上训练单个智能体。
今天,DeepMind 发布了新的任务集合 DMLab-30,其包含公共动作空间的视觉统一环境中的多种挑战性任务。想训练在多个任务中表现良好的智能体,我们需要高吞吐量和高效利用每个数据点的算法架构。因此,DeepMind 开发了一种可用于分布式训练的具备高扩展性的新型智能体架构 IMPALA(Importances Weighted Actor-Learner Architectures),该架构使用一种新型离策略修正算法 V-trace。
DMLab-30
DMLab-30 是使用 DeepMind 的开源强化学习环境 DeepMind Lab 设计出的新型任务集合。任意 DeepRL 研究者都可以使用这些环境在大量有趣的任务或多任务设置中测试系统。
设计者使这些任务尽可能多样化。它们具备不同的目标,从学习、记忆到导航等等。从视觉上来看它们也是不同的——从亮度、现代风格的纹理,从绿到浅棕色等等。它们包括不同的物理设置,从开放的多山地带到直角迷宫,再到开放的圆形房间。
此外,一些环境包括「bots」,可以执行内部的目标导向动作。同样重要的是,不同级别的任务目标和奖励也不同,从遵循语言命令、使用钥匙开门、采蘑菇,到绘画、沿着一条复杂、不可逆的路径行走。
但是,从动作和观察空间来看,这些环境基本上是一样的,允许单个智能体在该高度变化的任务集合的每一个环境中进行训练。关于环境的更多细节,详见:https://github.com/deepmind/lab。
IMPALA:Importance-Weighted Actor-Learner Architectures
为了解决智能体在 DMLab-30 中进行训练的问题,DeepMind 开发了一种新型分布式智能体 IMPALA,它利用高效的 TensorFlow 分布式架构最大化数据吞吐量。
IMPALA 受流行的 A3C 架构的启发,A3C 架构使用多个分布式 actor 来学习智能体的参数。在此类模型中,每个 actor 使用策略参数在环境中动作。actor 周期性地暂停探索,和中央参数服务器共享它们计算出的梯度,用于梯度更新(见下图)。
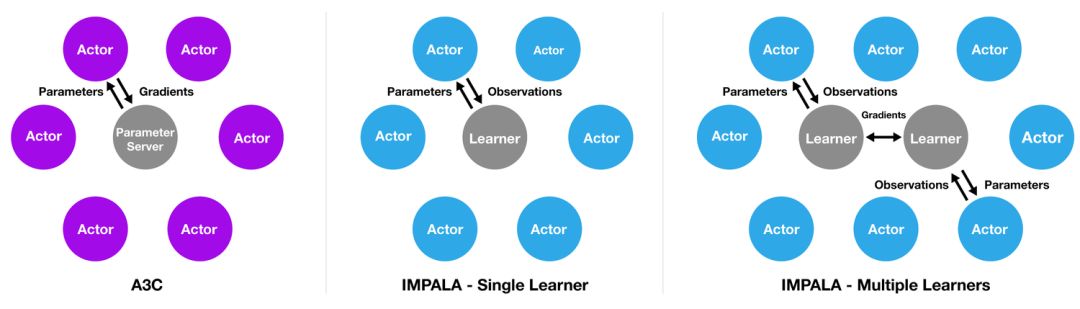
IMPALA 的 actor 不用于计算梯度,而是用于收集经验,然后传输至可计算梯度的中央学习器,生成一个具备完全独立的 actor 和 learner 的模型。为了利用现代计算系统,IMPALA 可使用单个学习器或执行同步更新的多个学习器来实现。用这种方式分离学习和动作可以有效地提高整个系统的吞吐量,因为 actor 不再需要等待学习步(像 batched A2C 架构中那样)。这使得我们可以在多个有趣的环境中训练 IMPALA,无需经历帧渲染时间的变动或耗时的任务重启。
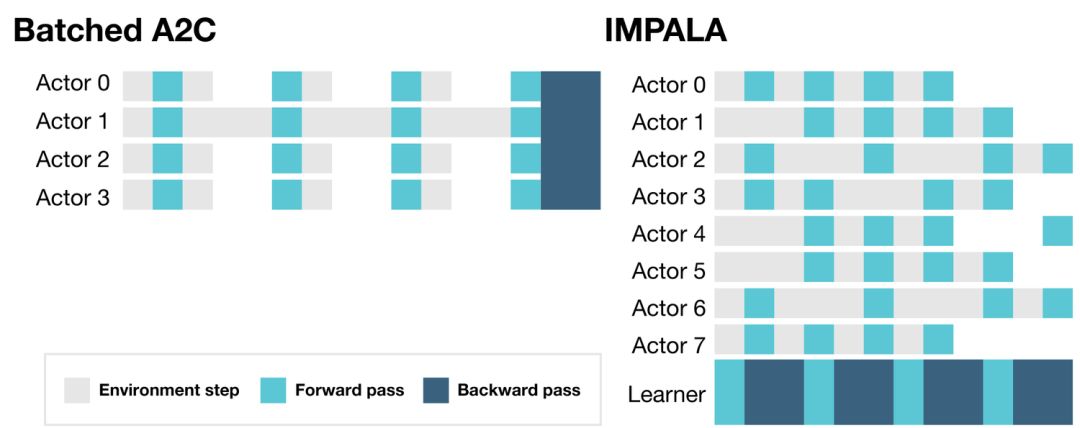
与其他需要在每个学习步骤上暂停的架构不同,IMPALA 是持续学习的
但是,决策与学习的分离会导致 actor 中的策略落后于学习器。为了弥补这一差异,DeepMind 引入了一种原则性离策略优势 actor critic 算法——V-trace,它通过 actor 的离策略弥补了轨迹。关于 V-trace 的具体细节可参考论文《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》(见文末)。
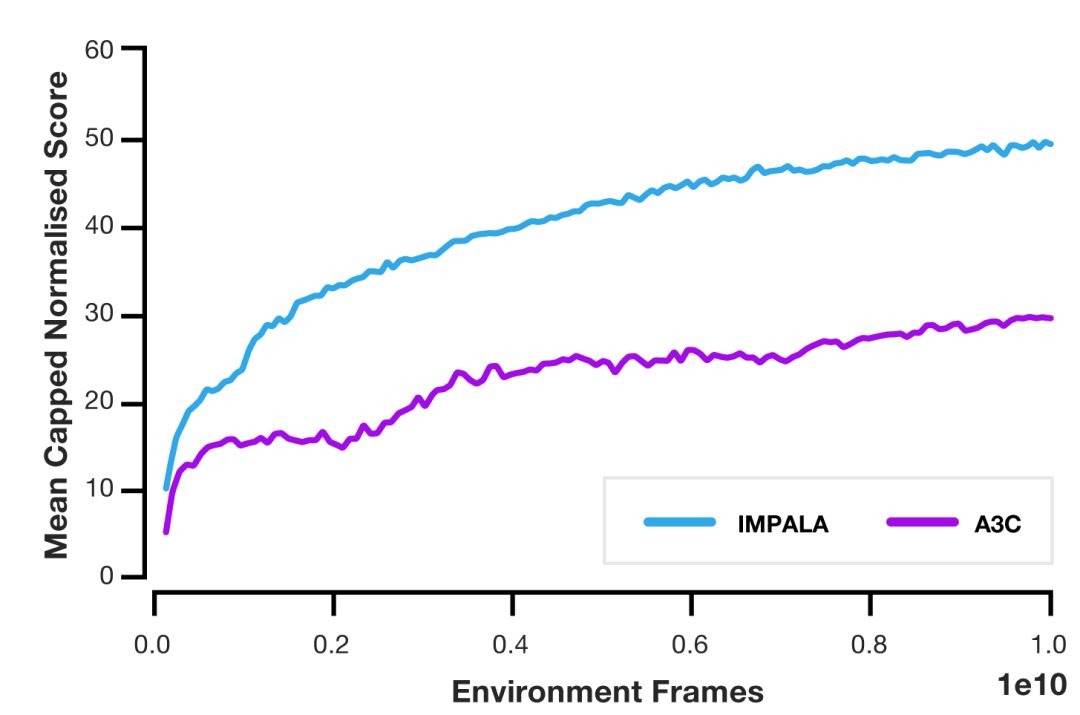
由于 IMPALA 的优化模型相对于类似智能体而言,可以处理一到两个数量级的更多经验,让复杂环境中的学习变为可能。DeepMind 比较了 IMPALA 与几种流行的 actor-critic 方法,发现新方法的速度有显著提高。此外,使用 IMPALA 的吞吐量增长与 actor 和 learner 的增加呈线性关系,这意味着分布式智能体模型和 V-trace 算法可以处理大规模实验,上千台机器都没有问题。
在 DMLab-30 的测试中,IMPALA 处理数据的效率是分布式 A3C 的 10 倍,最终得分是后者的 2 倍。另外,IMPALA 在多任务设置的训练中,相比单任务训练还展示了正向迁移的性质。
论文:IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
论文链接:https://arxiv.org/abs/1802.01561
摘要:在本研究中,我们专注于使用单一强化学习智能体与单一参数集解决大型任务集合的问题。在这样的条件下,最主要的挑战是处理越来越大的数据量和不断增加的训练时间——这在单一任务学习中已经是一个挑战。我们开发了一种新的分布式智能体 IMPALA(Importance-Weighted Actor Learner Architecture),它可以扩展到数千台机器上,每秒吞吐量高达 25 万帧。我们通过结合决策和学习分离与新型离策略修正方法 V-trace,达到了很高的吞吐量,实现了稳定学习,这对于学习的稳定性至关重要。我们展示了 IMPALA 在 DMLab-30(DeepMind Lab 环境中一组 30 个任务的集合)和 Atari-57(Arcade Learning Environment 中所有可用的 Atari 游戏)中进行多任务强化学习的有效性。我们的结果展示了 IMPALA 的性能优于之前的智能体,使用的数据更少,更重要的是新方法可以在多任务中展现出积极的迁移性质。
原文链接:https://deepmind.com/blog/impala-scalable-distributed-deeprl-dmlab-30/
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
以上是关于前沿 | DeepMind提出新型架构IMPALA:帮助实现单智能体的多任务强化学习的主要内容,如果未能解决你的问题,请参考以下文章
Nature 亮点丨精确预测蛋白结构可以依赖Google吗?DeepMind团队开发新型深度学习算法精确预测蛋白结构