hive数据仓库--Hive介绍
Posted 懒羊羊大帝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive数据仓库--Hive介绍相关的知识,希望对你有一定的参考价值。
1 什么是Hive
Hive是基于Hadoop的⼀个数据仓库⼯具,⽤来进⾏数据提取、转化、加载,这是⼀
种可以存储、查询和分析存储在Hadoop中的⼤规模数据的机制。Hive数据仓库⼯具能
将结构化的数据⽂件映射为⼀张数据库表,并提供类SQL的查询功能,能将SQL语句转
变成 MapReduce 任务来执⾏。它是由Facebook开发,⽤于解决海量结构化⽇志的
数据统计⼯具。
2 Hive的本质
Hive通过HQL语⾔进⾏数据查询,本质上是将HQL语句转化为MapReduce任务。
下图展示HQL的查询过程。
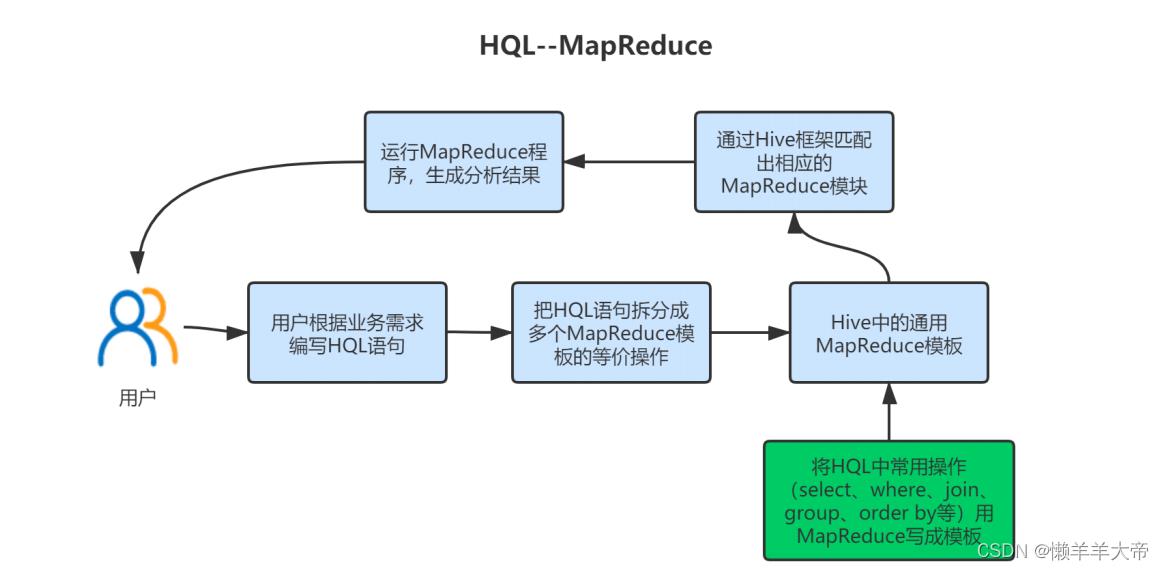
Hive中的数据存储在HDFS上
Hive分析数据是通过MapReduce实现的
Hive是运⾏在Yarn上的
所以Hive是运⾏在Hadoop之上的⼀种数据仓库⼯具。
3 Hive的优缺点
3.1 优点
Hive的查询采⽤类 SQL 的HQL语⾔,提供快速开发的能⼒(简单、容易上⼿)。
HQL可以⾃动转化成多个MapReduce任务,通过执⾏MapReduce任务达到数据操
作的⽬的。避免了开发⼈员去写 MapReduce的过程,学习成本低。
Hive 的执⾏延迟⽐较⾼,因此 Hive 常⽤于数据分析,对实时性要求不⾼的场合。
Hive⼗分适合对数据仓库进⾏统计分析。
Hive 优势在于处理⼤数据,对于处理⼩数据没有优势,因为 Hive 的执⾏延迟⽐较
⾼。
Hive ⽀持⽤户⾃定义函数,⽤户可以根据⾃⼰的需求来实现⾃⼰的函数。
Hive具有良好的可申缩性、可扩展性、容错性、输⼊格式的松散耦合。
3.2 缺点
Hive不适合⽤于联机事务处理(OLTP),也不提供实时查询功能。对实时性要求较
⾼的OLAP也不适⽤。
Hive 的 HQL 语⾔表达能⼒不⾜
⽆法表达迭代式算法
不擅⻓数据挖掘⼯作,由于 MapReduce 数据处理流程的限制,效率更⾼的算法
⽆法实现。
Hive 的效率⽐较低
Hive ⾃动⽣成的 MapReduce 作业不够智能化,存在任务冗余及任务调度不合理
情况。
Hive 调优⽐较困难,粒度较粗。
4 Hive架构
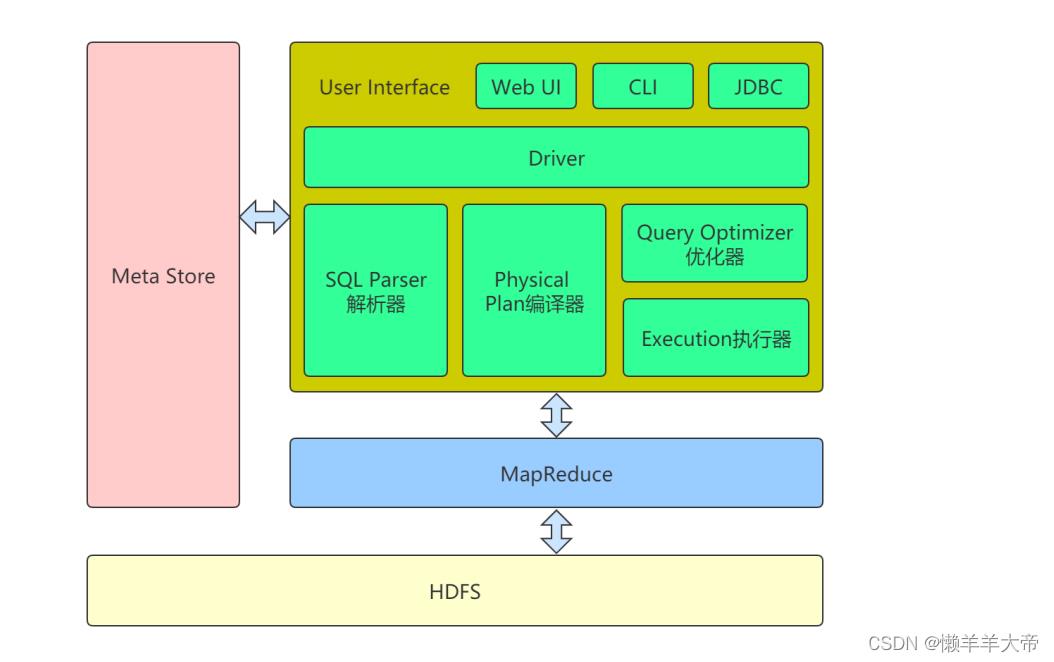
(1) ⽤户接⼝(User Interface)
⽤户访问Hive的接⼝,包括CLI(Command-Line Interface)、JDBC/ODBC(jdbc 访问 hive)、WebUI(浏览器访问 hive)⼏种形式。
(2) Driver
jdbc驱动程序
(3) SQL Parser解析器
将 SQL 字符串转换成抽象语法树 AST,这⼀步⼀般都⽤第 三⽅⼯具库完成,⽐如
antlr;对 AST 进⾏语法分析,⽐如表是否存在、字段是否存在、SQL 语义是否有误。
(4) Physical Plan编译器
将 AST 编译⽣成逻辑执⾏计划。
(5) Query Optimizer优化器
对逻辑执⾏计划进⾏优化。
(6) Execution执⾏器
把逻辑执⾏计划转换成可以运⾏的物理计划。对于 Hive 来 说,就是MapReduce。
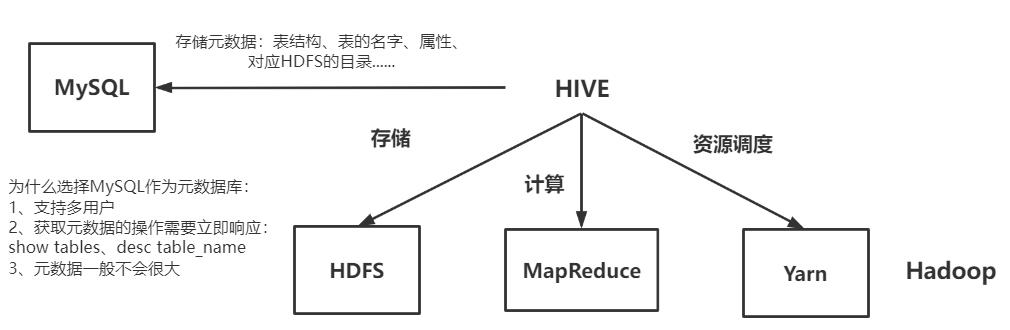
(7) Meta Store (元数据)
元数据包括表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字
段、 表的类型(是否是外部表)、表的数据所在⽬录等。默认存储在⾃带的 derby 数
据库中,推荐使⽤ mysql 存储 Metastore。
4.1 Hive和Hadoop之间的⼯作流程
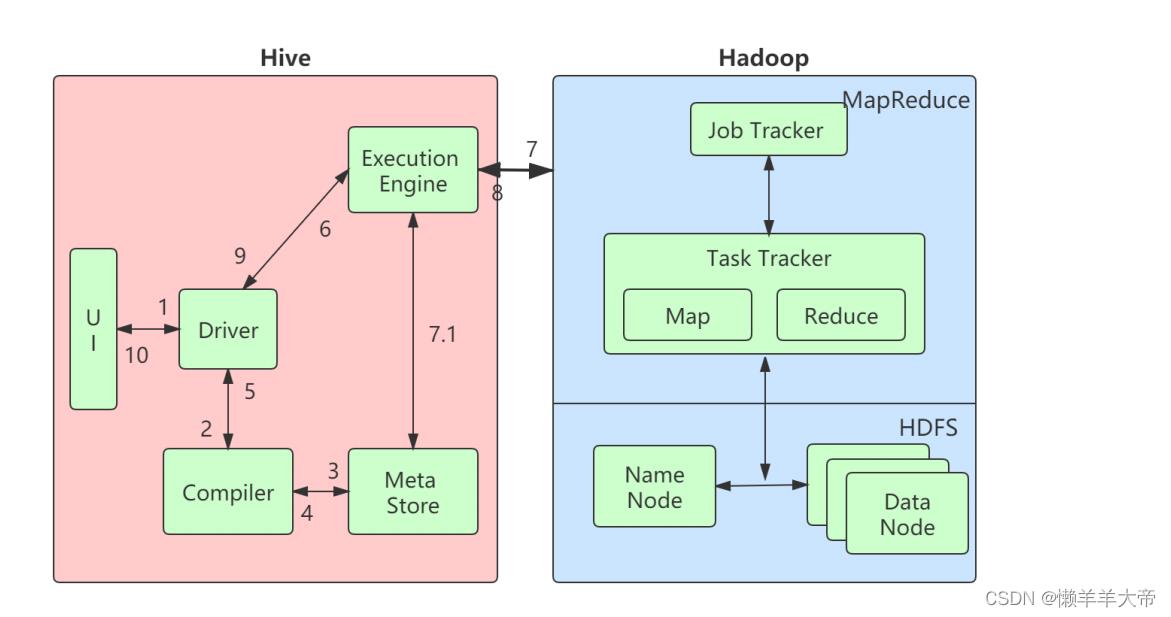
下表定义了Hive如何与Hadoop框架交互:
步骤号 操作
1 ”执⾏查询” Hive接⼝(如命令⾏或Web UI)向Driver(任何数据库驱动程
序,如JDBC,ODBC等)发送查询以执⾏。
2 ”获取计划” 驱动程序在查询编译器的帮助下解析查询以检查语法和查询计
划或查询的要求。
3 ”获取元数据” 编译器将元数据请求发送到Metastore(任何数据库)。
4
”发送元数据” Metastore将元数据作为响应发送给编译器。
5
”发送计划” 编译器检查需求并将计划重新发送给驱动程序。到此为⽌,查
询的解析和编译已完成。
6
”执⾏计划” 驱动程序将执⾏计划发送给执⾏引擎。
7 ”执⾏作业” 在内部,执⾏作业的过程是⼀个MapReduce作业。执⾏引擎
将作业发送到名称节点中的JobTracker,并将该作业分配给数据节点中的
TaskTracker。在这⾥,查询执⾏MapReduce作业。
7.1 ”元数据操作” 同时在执⾏时,执⾏引擎可以使⽤Metastore执⾏元数据操
作。
8 ”取结果” 执⾏引擎从Data节点接收结果。
9 ”发送结果” 执⾏引擎将这些结果值发送给驱动程序。
10 ”发送结果” 驱动程序将结果发送给Hive Interfaces。
5 Hive与数据库的⽐较
Hive虽然采⽤了类似SQL的查询语⾔HQL(Hive Query Language),但除了查询
语⾔相似之外,不要把Hive理解成是⼀种数据库。
数据库主要应⽤于在线事务处理(OLTP)和在线分析处理(OLAP),强调的是
事务的时效性与可靠性。⽽Hive是⼀种数据仓库技术,主要⽤应于对时效性要求不⾼的
批量数据统计分析,它强调的是数据处理的吞吐率。
下⾯介绍两者之间的主要差别:
5.1 数据规模⽅⾯
Hive集群采⽤的是分布式计算技术,天然⽀持并⾏计算,具有很好的申缩性、可扩
展性、安全性。因此可以⽀持很⼤规模的数据。
数据库集群⼀般采⽤的是分库分表的技术,⽀持纵向扩展,但难以进⾏横向扩展,
集群规模较⼩,所以数据库可以⽀持的数据规模较⼩,申缩性、可扩展性不好。
5.2 查询语⾔⽅⾯
SQL被⼴泛的应⽤于数据库技术中,有着⼴泛的⽤户群体,为了降低初学者的学习
成本。因此,把Hive的查询语⾔HQL设计成了类 SQL 的查询语⾔。熟悉 SQL 的开发者
可以很⽅便地使⽤ Hive。
5.3 数据更新⽅⾯
Hive数据仓库具有读多写少的特点。因此,Hive不建议对数据进⾏改写,所有的数
据都是在加载的时候确定好的。原因是Hive是建⽴在Hadoop基础上的,⽽HDFS是只⽀
持追加数据不⽀持修改数据。
数据库中的数据要保证能够随时查询、新增、修改和删除。
5.4 执⾏延时⽅⾯
Hive执⾏延时⾼主要有两个原因:
(1)查询⼀般不使⽤索引,需要扫描整个表
(2)采⽤ MapReduce 框架。由于 MapReduce 本身具有较⾼的延迟,因此Hive也
有较⾼的延迟。
数据库的执⾏延迟较低是有条件的,即数据规模较⼩,当数据规模⼤到超过数据库
的处理能⼒的时候,Hive 的并⾏计算就能体现出优势。
5.5 应⽤场景⽅⾯
Hive主要应⽤于时实性要求不⾼的⼤规模数据的统计分析;数据库主要应⽤于数据
规模较⼩、实时性要求较⾼的在线事务处理(OLTP)和在线分析处理(OLAP)。
1Hive数据仓库——概念及架构
文章目录
- Hive 1.2.1
Hive 1.2.1

大数据体系概述
Hive架构
数据仓库
很久很久以前,我们的世界分为:人族、矮人族、精灵、兽族…本来世界很和平。
突然有一天,有一个人,有一个想法,这个想法很可怕,打破了这样的平静,他想统治整个世界,怎么做呢?
他想了一个主意,他会魔法,他用他的魔法,打造出魔戒,然后他把这个魔戒分别送个各个种族的首领,方便各个首领更好的统治;
然后他又偷偷的制造了一个至尊魔戒,这个至尊魔戒可以统治普通的魔戒,以此实现他的统一世界的梦想。。。。。。
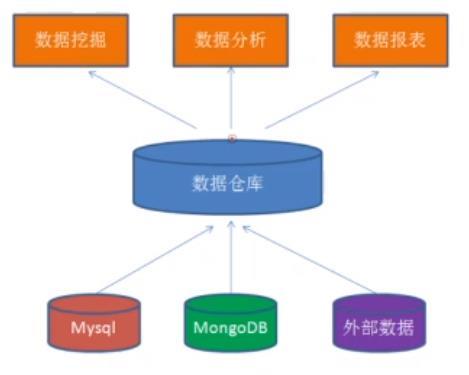
如果把世界上每一个生物当作一条记录,那么魔戒就好比数据库,而我们的至尊魔戒就是数据仓库。
数据仓库(Data WareHouse) 实际上是为了公司能够统一各种业务数据,将各个不同数据源中的数据融合,这些数据通常可以做数据分析、数据挖掘、报表,帮助公司做决策。
Hive 是什么
Hive是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转化加载( ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive相当于hadoop的客户端工具,部署时不一定放在集群管理节点中,可以放在某个节点上。
Hive的安装
Hive的详细安装过程请点击下方靓仔原创博客链接:

版本介绍
- Hive数据仓库——环境搭建及简单使用
- 1.2.1和1.2.2 稳定版本,为Hive2版本(主流版本)
- 1.2.1的程序只能连接hive1.2.1 的hiveserver2
学习Hive
- java 1.8.0_171
- hadoop 2.7.6
- hive 1.2.1
- mysql:5.7
自己使用的过程中一定严格按照这个版本去使用(版本兼容)
安装主要流程
- 安装MySQL服务
- 安装hive包,解压
- 修改配置文件,连接mysql,连接hadoop
- 启动
Hive的详细安装过程请点击下方靓仔原创博客链接:
Hive与传统数据库比较
| 查询语言 | HiveQL | SQL |
|---|---|---|
| 数据存储位置 | HDFS | Raw Device or 本地 FS |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 | 不支持(1.x以后版本支持) | 支持 |
| 索引 | 新版本有,但弱 | 有 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
- 查询语言,类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
- 数据存储位置,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
- 数据格式,Hive 中没有定义专门的数据格式。而在数据库中,所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
- 数据更新,Hive 对数据的改写和添加比较弱化,0.14版本之后支持,需要启动配置项。而数据库中的数据通常是需要经常进行修改的。
- 索引,Hive 在加载数据的过程中不会对数据进行任何处理。因此访问延迟较高。数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
- 执行计算,Hive 中执行是通过 MapReduce 来实现的而数据库通常有自己的执行引擎。
- 数据规模,由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive的存储格式
- Hive的数据存储基于Hadoop HDFS。
- Hive没有专门的数据文件格式,常见的有以下几种:
- TEXTFILE
- SEQUENCEFILE
- AVRO
- RCFILE
- ORCFILE
- PARQUET
TextFile
TEXTFILE 即正常的文本格式,是Hive默认文件存储格式,因为大多数情况下源数据文件都是以text文件格式保存(便于查看验数和防止乱码)。此种格式的表文件在HDFS上是明文,可用hadoop fs -cat命令查看,从HDFS上get下来后也可以直接读取。
TEXTFILE 存储文件默认每一行就是一条记录,可以指定任意的分隔符进行字段间的分割。但这个格式无压缩,需要的存储空间很大。虽然可结合Gzip、Bzip2、Snappy等使用,使用这种方式,Hive不会对数据进行切分,从而无法对数据进行并行操作。
一般只有与其他系统由数据交互的接口表采用TEXTFILE 格式,其他事实表和维度表都不建议使用。
RCFile
Record Columnar的缩写。是Hadoop中第一个列文件格式。能够很好的压缩和快速的查询性能。通常写操作比较慢,比非列形式的文件格式需要更多的内存空间和计算量。 RCFile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
ORCFile
Hive从0.11版本开始提供了ORC的文件格式,ORC文件不仅仅是一种列式文件存储格式,最重要的是有着很高的压缩比,并且对于MapReduce来说是可切分 (Split) 的。因此,在Hive中使用ORC作为表的文件存储格式,不仅可以很大程度的节省HDFS存储资源,而且对数据的查询和处理性能有着非常大的提升,因为ORC较其他文件格式压缩比高,查询任务的输入数据量减少,使用的Task也就减少了。ORC能很大程度的节省存储和计算资源,但它在读写时候需要消耗额外的CPU资源来压缩和解压缩,当然这部分的CPU消耗是非常少的。
Parquet
通常我们使用关系数据库存储结构化数据,而关系数据库中使用数据模型都是扁平式的,遇到诸如List、Map和自定义Struct的时候就需要用户在应用层解析。但是在大数据环境下,通常数据的来源是服务端的埋点数据,很可能需要把程序中的某些对象内容作为输出的一部分,而每一个对象都可能是嵌套的,所以如果能够原生的支持这种数据,这样在查询的时候就不需要额外的解析便能获得想要的结果。
Parquet的灵感来自于2010年Google发表的Dremel论文,文中介绍了一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能。Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定。这也是parquet相较于orc的仅有优势:支持嵌套结构。Parquet 没有太多其他可圈可点的地方,比如他不支持update操作(数据写成后不可修改),不支持ACID等。
SEQUENCEFILE
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以 <key,value> 的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。 SequenceFile最重要的优点就是Hadoop原生支持较好,有API,但除此之外平平无奇,实际生产中不会使用。
AVRO
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。Avro提供的机制使动态语言可以方便地处理Avro数据。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop 和 Hcatalog。
Hive的四大常用存储格式存储效率及执行速度对比
| 存储格式 | 占用空间 | 压缩率%(压缩后:压缩前) | sql编号 | 执行时间(s) |
|---|---|---|---|---|
| TextFile | 15.1 | 100.0 | 1 | 118 |
| 2 | 217 | |||
| ORC | 1.3 | 8.61 | 1 | 33 |
| 2 | 3 | |||
| Parquet | 4.3 | 28.48 | 1 | 40 |
| 2 | 71 | |||
| RCFile | 12.3 | 81.64 | 1 | 88 |
| 2 | 71 |
| 编号 | sql |
|---|---|
| 1 | select count(*) from table_test; |
| 2 | select name,sum(table_test.price) as nums from table_test group by name; |
| 3 | benchmark 其它很多增删改的操作 |
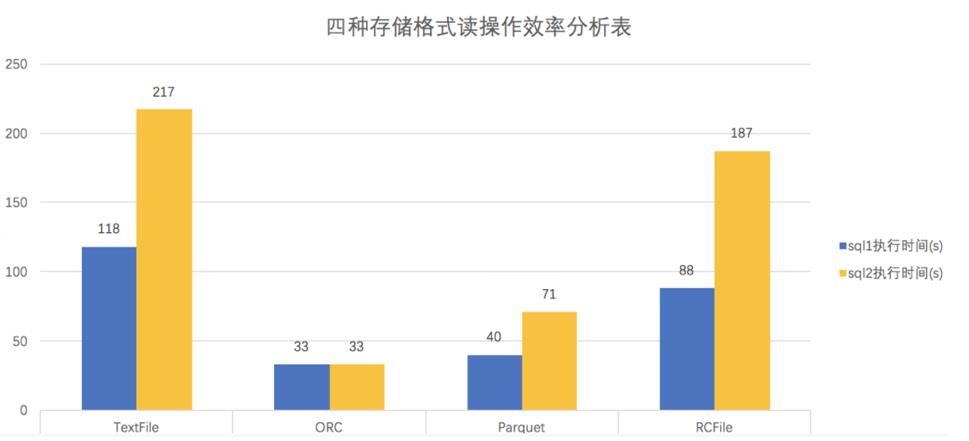
结论:ORCFile存储文件读操作效率最高
耗时比较:ORC<Parquet<RC<Text
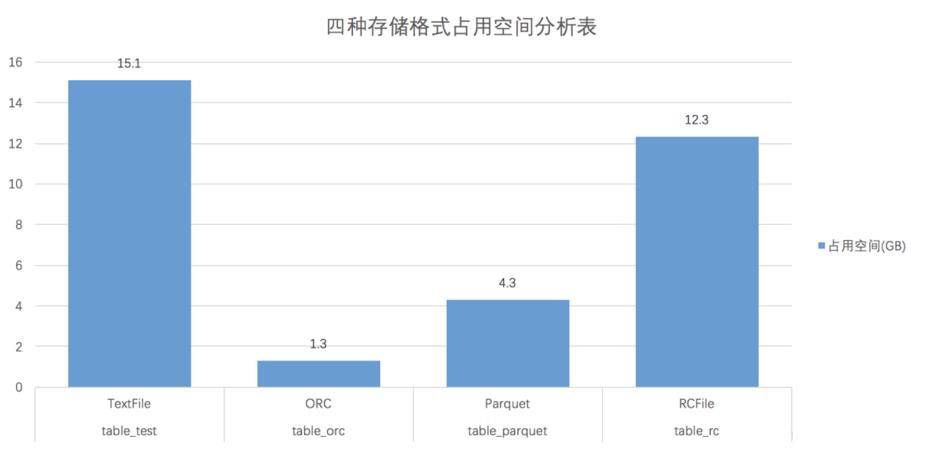
结论:ORCFile存储文件占用空间少,压缩效率高
占用空间:ORC<Parquet<RC<Text
Hive操作客户端
常用的2个:CLI,JDBC/ODBC
- CLI,即Shell命令行
- JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似。
- Hive 将元数据存储在数据库中 (metastore) ,目前只支持 mysql、derby。
- Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等;由解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划 (plan) 的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
Hive的metastore
- metastore是hive元数据的集中存放地。
- metastore默认使用内嵌的derby数据库作为存储引擎。
- Derby引擎的缺点:一次只能打开一个会话。
- 使用MySQL作为外置存储引擎,多用户同时访问
- 元数据表结构
Hive元数据表结构
1、存储Hive版本的元数据表(VERSION)
该表比较简单,但很重要。
| VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
|---|---|---|
| ID主键 | Hive版本 | 版本说明 |
| 1 | 1.2.1 | Set by MetaStore |
如果该表出现问题,根本进入不了Hive-Cli。比如该表不存在,当启动Hive-Cli时候,就会报错”Table ‘hive.version’ doesn’t exist”。
2、Hive数据库相关的元数据表(DBS、DATABASE_PARAMS)
DBS:该表存储Hive中所有数据库的基本信息,字段如下:
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| DB_ID | 数据库ID | 1 |
| DESC | 数据库描述 | Default Hive database |
| DB_LOCATION_URI | 数据HDFS路径 | hdfs://193.168.100.100:9000/test-warehouse |
| NAME | 数据库名 | default |
| OWNER_NAME | 数据库所有者用户名 | public |
| OWNER_TYPE | 所有者角色 | ROLE |
DATABASE_PARAMS:该表存储数据库的相关参数,在CREATE DATABASE时候用WITH
DBPROPERTIES(property_name=property_value, …)指定的参数。
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| DB_ID | 数据库ID | 1 |
| PARAM_KEY | 参数名 | createdby |
| PARAM_VALUE | 参数值 | root |
DBS和DATABASE_PARAMS这两张表通过DB_ID字段关联。
3、Hive表和视图相关的元数据表
主要有TBLS、TABLE_PARAMS、TBL_PRIVS,这三张表通过TBL_ID关联。
TBLS:该表中存储Hive表,视图,索引表的基本信息。
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| TBL_ID | 表ID | 21 |
| CREATE_TIME | 创建时间 | 1645194826 |
| DB_ID | 数据库ID | 1 |
| LAST_ACCESS_TIME | 上次访问时间 | 1645194826 |
| OWNER | 所有者 | root |
| RETENTION | 保留字段 | 0 |
| SD_ID | 序列化配置信息 | 41,对应SDS表中的SD_ID |
| TBL_NAME | 表名 | ex_detail_ufdr_30streaming |
| TBL_TYPE | 表类型 | EXTERNAL_TABLE |
| VIEW_EXPANDED_TEXT | 视图的详细HQL语句 | |
| VIEW_ORIGINAL_TEXT | 视图的原始HQL语句 |
TABLE_PARAMS:该表存储表/视图的属性信息
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| TBL_ID | 表ID | 1 |
| PARAM_KEY | 属性名 | totalSize,numRows,EXTERNAL |
| PARAM_VALUE | 属性值 | 970107336、21231028、TRUE |
TBL_PRIVS:该表存储表/视图的授权信息
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| TBL_GRANT_ID | 授权ID | 1 |
| CREATE_TIME | 授权时间 | 1645194826 |
| GRANT_OPTION | 授与权限 | 0 |
| GRANTOR | 授权执行用户 | root |
| GRANTOR_TYPE | 授权者类型 | USER |
| PRINCIPAL_NAME | 被授权用户 | username |
| PRINCIPAL_TYPE | 被授权用户类型 | USER |
| TBL_PRIV | 权限 | Select、Alter |
| TBL_ID | 表ID | 21,对应TBLS表的TBL_ID |
4、Hive文件存储信息相关的元数据表
主要涉及SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。
SDS:该表保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息。
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| SD_ID | 存储信息ID | 41 |
| CD_ID | 字段信息ID | 21,对应CDS表 |
| INPUT_FORMAT | 文件输入格式 | org.apache.hadoop.mapred.TextInputFormat |
| IS_COMPRESSED | 是否压缩 | 0 |
| IS_STOREDASSUBDIRECTORIES | 是否以子目录存储 | 0 |
| LOCATION | HDFS路径 | username |
| PRINCIPAL_TYPE | 被授权用户类型 | hdfs://193.168.100.100:9000/detail_ufdr_streaming_test |
| NUM_BUCKETS | 分桶数量 | 0 |
| OUTPUT_FORMAT | 文件输出格式 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat |
| SERDE_ID | 序列化类ID | 41,对应SERDES表 |
SD_PARAMS: 该表存储Hive存储的属性信息,在创建表时候使用STORED BY ‘storage.handler.class.name’ [WITH SERDEPROPERTIES (…)指定。
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| SD_ID | 存储配置ID | 41 |
| PARAM_KEY | 存储属性名 | |
| PARAM_VALUE | 存储属性值 |
SERDES:该表存储序列化使用的类信息
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| SERDE_ID | 序列化类配置ID | 41 |
| NAME | 序列化类别名 | NULL |
| SLIB | 序列化类 | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
SERDE_PARAMS:该表存储序列化的一些属性、格式信息,比如:行、列分隔符
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| SERDE_ID | 序列化类配置ID | 41 |
| PARAM_KEY | 属性名 | field.delim |
| PARAM_VALUE | 属性值 | I |
5、Hive表字段相关的元数据表
要涉及COLUMNS_V2
COLUMNS_V2:该表存储表对应的字段信息
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| CD_ID | 字段信息ID | 21 |
| COMMENT | 字段注释 | NULL |
| COLUMN_NAME | 字段名 | air_port_duration |
| TYPE_NAME | 字段类型 | bigint |
| INTEGER_IDX | 字段顺序 | 119 |
6、Hive表分分区相关的元数据表
主要涉及PARTITIONS、PARTITION_KEYS、PARTITION_KEY_VALS、PARTITION_PARAMS
PARTITIONS:该表存储表分区的基本信息
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| PART_ID | 分区ID | 21 |
| CREATE_TIME | 分区创建时间 | 1645194826 |
| LAST_ACCESS_TIME | 最后一次访问时间 | 0 |
| PART_NAME | 分区名 | hour=15/last_msisdn=0 |
| SD_ID | 分区存储ID | 43 |
| TBL_ID | 表ID | 22 |
| LINK_TARGET_ID | 链接模板ID | NULL |
PARTITION_KEYS:该表存储分区的字段信息
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| TBL_ID | 表ID | 22 |
| PKEY_COMMENT | 分区字段说明 | NULL |
| PKEY_NAME | 分区字段名 | hour |
| PKEY_TYPE | 分区字段类型 | int |
| INTEGER_IDX | 分区字段顺序ID | 0 |
PARTITION_KEY_VALS:该表存储分区字段值
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| PART_ID | 分区ID | 21 |
| PART_KEY_VAL | 分区字段值 | 0 |
| INTEGER_IDX | 分区字段值顺序 | 1 |
PARTITION_PARAMS:该表存储分区的属性信息
| 表字段 | 说明 | 示例数据 |
|---|---|---|
| PART_ID | 分区ID | 21 |
| PARAM_KEY | 分区属性名 | 0 |
| INTEGER_IDX | 分区字段值顺序 | numFiles,numRows |
| PARAM_VALUE | 分区属性值 | 1,502195 |
6、其他不常用的元数据表
- DB_PRIVS,数据库权限信息表。通过GRANT语句对数据库授权后,将会在这里存储。
- IDXS,索引表,存储Hive索引相关的元数据。
- INDEX_PARAMS,索引相关的属性信息。
- TBL_COL_STATS,表字段的统计信息。使用ANALYZE语句对表字段分析后记录在这里。
- TBL_COL_PRIVS,表字段的授权信息。
- PART_PRIVS,分区的授权信息。
- PART_COL_PRIVS, 分区字段的权限信息。
- PART_COL_STATS,分区字段的统计信息。
- FUNCS,用户注册的函数信息。
- FUNC_RU,用户注册函数的资源信息。
到底啦!关注靓仔学习更多的大数据知识 (❁´◡`❁)
以上是关于hive数据仓库--Hive介绍的主要内容,如果未能解决你的问题,请参考以下文章