大数据开发|Hive数据仓库环境构建
Posted 读数会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据开发|Hive数据仓库环境构建相关的知识,希望对你有一定的参考价值。
提前说明一下,大数据的搭建环境都是在Linux系统下构建,可能针对一些没有Linux编程基础的同学来说会有一些吃力,请各位客官放心,小店伙计后期会专门有几期来讲解Linux编程基础。绝对保证零基础完成大数据环境的构建。今天主要是构建hive数据仓库。
一
hive数据仓库介绍
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
二
准备工作
2.1
安装mysql数据库
下载MySQL数据库
百度网盘下载链接:http://pan.baidu.com/s/1gfjGXxx 密码:4oo0

解压
解压MySQLtar包到/opt/modules/mysql/
tar -zxvf mysql-5.6.26.tar.gz -C /opt/modules/mysql/
编译环境准备
编译环境准备:
yum -y install gcc gcc-c++ gdb cmake ncurses-devel bison bison-devel
编译监测
进入到解压目录:/opt/modules/mysql/mysql-5.6.26
cd /opt/modules/mysql/mysql-5.6.26
进行编译监测
cmake \
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql \
-DMYSQL_DATADIR=/usr/local/mysql/data \
-DSYSCONFDIR=/etc \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DWITH_PARTITION_STORAGE_ENGINE=1 \
-DMYSQL_UNIX_ADDR=/tmp/mysql.sock \
-DMYSQL_TCP_PORT=3306 \
-DDEFAULT_CHARSET=utf8 \
-DDEFAULT_COLLATION=utf8_general_ci
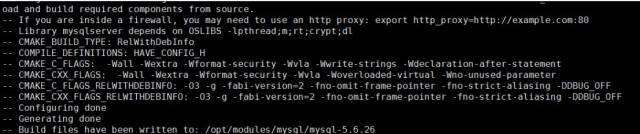
编译安装
make&&make install
2.2
配置MySQL
配置用户
监测是否有用户及用户组
cat /etc/passwd 查看用户列表
cat /etc/group 查看用户组列表
如果没有就创建
#groupadd mysql
#useradd -r -g mysqlmysql
确认一下创建结果
id mysql

修改/usr/local/mysql目录权限
chown -R mysql:mysql /usr/local/mysql
初始化配置
安装运行MySQL测试脚本需要的perl
yum install perl
进入MySQL安装路径
cd /usr/local/mysql
执行初始化配置脚本,创建系统自带的数据库和表
scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --user=mysql
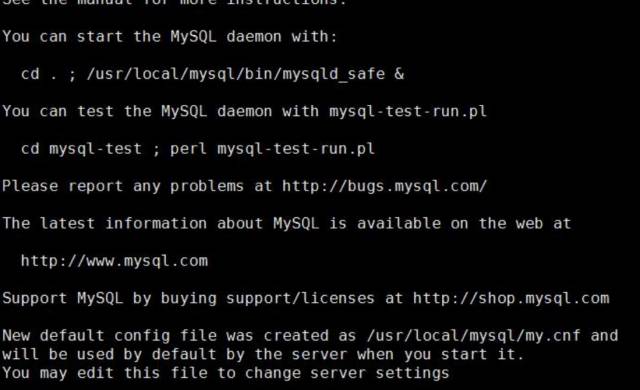
启动MySQL
添加服务,拷贝服务脚本到init.d目录,并设置开机启动
cp support-files/mysql.server /etc/init.d/mysql
ll /etc/init.d/mysql ###查看有无可执行权限,如果没有则执行chmod u+x /etc/init.d/mysql
chkconfig mysql on ####设置开启自启动
service mysql start ##启动MySQL

配置MySQL账号及密码
MySQL启动成功后,root默认没有密码,我们需要设置root密码。
设置之前,我们需要先设置PATH,要不不能直接调用mysql
修改/etc/profile文件,在文件末尾添加
PATH=/usr/local/mysql/bin:$PATH
export PATH

运行下面的命令,让配置立即生效
source /etc/profile
现在,我们可以在终端内直接输入mysql进入,mysql的环境了
执行下面的命令修改root密码
mysql -uroot
mysql>SET PASSWORD=PASSWORD('123456');
若要设置root用户可以远程访问,执行
mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
flush privileges;
远程访问时的密码可以和本地不同。
为了后面hive的需要,我们还是新创建一个用户
mysql>create user 'hive'@'%' identified by 'hive';mysql>grant all on *.* to 'hive'@'%' identified by 'hive';mysql>flush privileges;
自此MySQL就安装完成了。
三
hive的安装
下载hive软件安装包

解压hive包
tar -zxvf hive-1.1.0-cdh5.4.0.tar.gz /home/hadoop/

修改hive配置文件
创建一个hive-site.xml文件,添加如下配置

#vi /home/hadoop/hive/conf/hive-site.xml
加入如下内容:
<configuration>
#mysql 数据库配置
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop4:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
#加载mysql jdbc数据驱动包
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
#配置hive UI
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-1.1.0-cdh5.4.0.jar</value>
<description>This sets the path to the HWI war file, relative to ${HIVE_HOME}. </description>
</property>
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
<description>This is the host address the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/home/hadoop/hive/data/hive/hive-${user.name}</value>
<description>Scratch space for Hive jobs</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/hive/data/hive/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
</configuration>
创建配置文件中需要的目录
mkdir -p /home/hadoop/hive/data/hive/
上传mysql JDBC的jar到hive的lib下

cp mysql-connector-java-5.1.32-bin.jar /home/hadoop/hive/lib
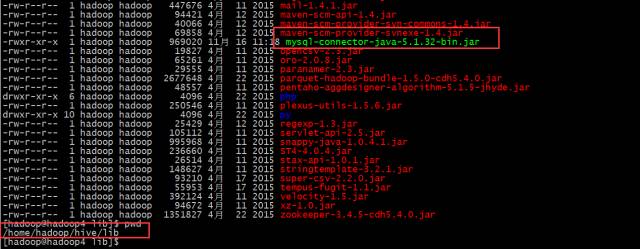
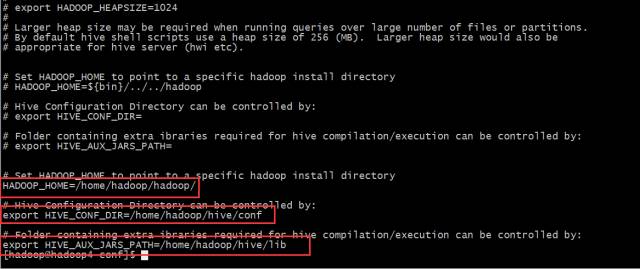
设置hive-env.xml
将hive-env.sh.template复制一份为hive-env.sh
cp hive-env.sh.template hive-env.sh

修改内容如下:
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/home/hadoop/hadoop/
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/home/hadoop/hive/conf
# Folder containing extra ibraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/home/hadoop/hive/lib
启动hive与测试
启动hive:
/home/hadoop/hive/bin/hive

测试hive:
创建hive表
hive> create table wyd(
name string,
age int
) row format delimited fields terminated by ','
stored as textfile;

在Linux的本地构建一个测试数据文件

hive> load data local inpath '/home/hadoop/wyd_hive_test/hive_test.txt' overwrite into table wyd;

测试查询
select * from wyd;

测试mapreduce,统计数据的记录数
select count(*) from wyd;
至此hive安装完成。
后面会不定期的更新有关大数据、云计算、数据挖掘等方面的知识点,欢迎大家持续关注。如果对该知识点有疑问,欢迎在留言区留言讨论。
以上是关于大数据开发|Hive数据仓库环境构建的主要内容,如果未能解决你的问题,请参考以下文章