技术干货三分钟了解数据仓库Hive
Posted 国泰安大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术干货三分钟了解数据仓库Hive相关的知识,希望对你有一定的参考价值。
Hive在Hadoop的生态体系结构中占有及其重要的地位,在实际的业务当中用的也非常多,也是由于Hive的存在,才使得Hadoop非常流行。
那么Hive究竟是什么,为什么在Hadoop生态中占有这么重要的地位,本篇文章将介绍Hive的体系架构、操作、以及Hive与Hbase的区别等对Hive进行全方面的阐述。
- 01 -
Hive是什么
Hive 是一个基于 Hadoop 的开源数据仓库工具,用于存储和处理海量结构化数据。它把海量数据存储于 hadoop 文件系统,而不是数据库,但提供了一套类数据库的数据存储和处理机制,并采用 HQL (类 SQL )语言对这些数据进行自动化管理和处理。
Hive可以认为是MapReduce的一个封装、包装。Hive的意义就是在业务分析中将用户容易编写、会写的Sql语言转换为复杂难写的MapReduce程序,从而大大降低了Hadoop学习的门槛,让更多的用户可以利用Hadoop进行数据挖掘分析。
- 02 -
Hive的业务场景
在介绍Hive的架构之前,先给大家看一个业务场景,让大家感受一下为什么Hive如此的受欢迎。
业务描述:统计业务表consumer.txt中北京的客户有多少位?下面是相应的业务数据:
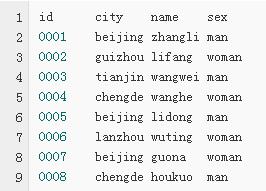
首先先用大家所熟悉的MapReduce程序来实现这个业务分析,完整代码如下(共81行):
........

MapReduce程序代码运行结果如下:
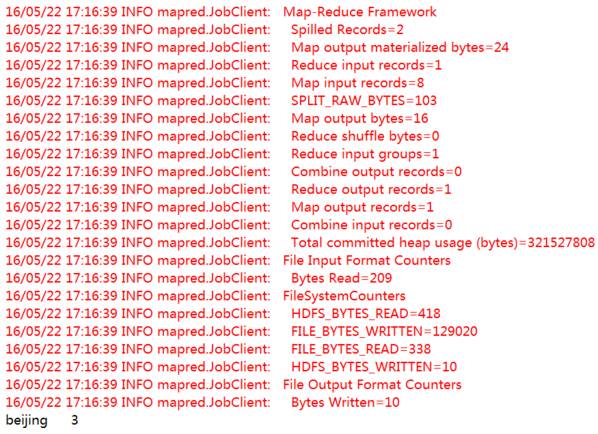
从运行结果可以看出:在consumer.txt业务表中,北京的客户共有三位。下面我们将用Hive来实现相同的功能,即统计业务表consumer.txt中北京的客户有多少位?
Hive操作如下:

Hive运行结果如下:

现在是不是感觉Hive这个运行框架很神奇—–对于相同的业务逻辑只需要写几行Sql命令就可以获取我们所需要的结果,这也恰恰是Hive为什么这么流行的原因。
- 03 -
Hive的优势
Hive支持标准的SQL语法,免去了用户编写MapReduce程序的过程,大大减少了公司的开发成本。
Hive的出现可以让那些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户能够在HDFS大规模数据集上很方便地利用SQL 语言查询、汇总、分析数据,毕竟精通SQL语言的人要比精通Java语言的多得多。
Hive是为大数据批量处理而生的,Hive的出现解决了传统的关系型数据库(mysql、Oracle)在大数据处理上的瓶颈。
- 04 -
Hive的架构
下面是Hive的体系结构图:
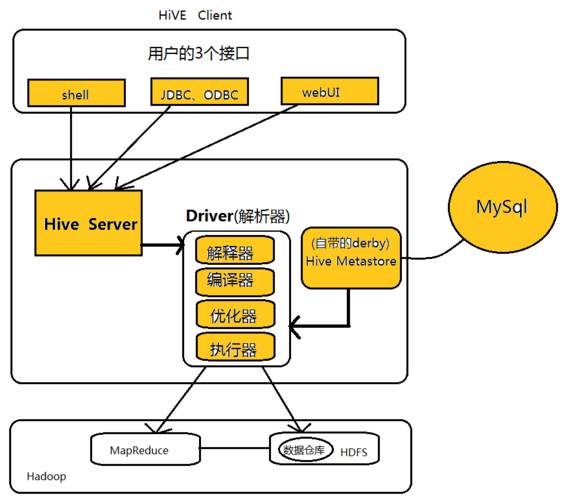
Hive的体系结构可以分为以下几个部分:
① 用户接口:包括shell命令、Jdbc/Odbc和WebUi,其中最常用的是shell这个客户端方式对Hive进行相应操作
②Hive解析器(驱动Driver):Hive解析器的核心功能就是根据用户编写的Sql语法匹配出相应的MapReduce模板,形成对应的MapReduce job进行执行。
③Hive元数据库(MetaStore):Hive将表中的元数据信息存储在数据库中,如derby(自带的)、Mysql(实际工作中配置的),Hive中的元数据信息包括表的名字、表的列和分区、表的属性(是否为外部表等)、表的数据所在的目录等。Hive中的解析器在运行的时候会读取元数据库MetaStore中的相关信息。
④Hadoop:Hive用HDFS进行存储,用MapReduce进行计算——-Hive这个数据仓库的数据存储在HDFS中,业务实际分析计算是利用MapReduce执行的。
从上面的体系结构中可以看出,在Hadoop的HDFS与MapReduce以及MySql的辅助下,Hive其实就是利用Hive解析器将用户的SQl语句解析成对应的MapReduce程序而已。
- 05 -
Hive的运行机制
Hive的运行机制正如图所示:创建完表之后,用户只需要根据业务需求编写Sql语句,而后将由Hive框架将Sql语句解析成对应的MapReduce程序,通过MapReduce计算框架运行job,便得到了我们最终的分析结果。
在Hive的运行过程中,用户只需要创建表、导入数据、编写Sql分析语句即可,剩下的过程将由Hive框架自动完成,而创建表、导入数据、编写Sql分析语句其实就是数据库的知识了,Hive的运行过程也说明了为什么Hive的存在大大降低了Hadoop的学习门槛以及为什么Hive在Hadoop家族中占有着那么重要的地位。
- 06 -
Hive与Hbase的区别
Hive从某种程度上讲就是很多“SQL—MapReduce”框架的一个封装,即Hive就是MapReduce的一个封装,Hive的意义就是在业务分析中将用户容易编写、会写的Sql语言转换为复杂难写的MapReduce程序。
Hbase可以认为是hdfs的一个包装。他的本质是数据存储,是个NoSql数据库;hbase部署于hdfs之上,并且克服了hdfs在随机读写方面的缺点。
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase非常适合用来进行大数据的实时查询。Facebook用Hive进行消息和实时的分析。它也可以用来统计Facebook的连接数。
参考博客:http://blog.csdn.net/a2011480169/article/details/51482799
以上是关于技术干货三分钟了解数据仓库Hive的主要内容,如果未能解决你的问题,请参考以下文章