大数据技术---数据仓库Hive
Posted 努力学习的程序媛儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术---数据仓库Hive相关的知识,希望对你有一定的参考价值。
MapReduce相关介绍请看此文:https://blog.csdn.net/qq_43752469/article/details/120640340?spm=1001.2014.3001.5501
一、数据仓库Hive概述
1、数据仓库
数据仓库:是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
根本目的:支持企业内部的商业分析和决策,基于数据仓库的分析结果,做出相关的经营决策。
 2、数据仓库和传统数据库的区别?
2、数据仓库和传统数据库的区别?
(1)数据仓库相对稳定
(2)传统数据库只能保留某一时刻的状态信息,数据仓库保留所有的历史数据,帮助企业构建经营分析系统。
(3)面临挑战:传统数据仓库无法满足快速增长的海量数据存储需求、无法有效处理不同类型的数据、计算和处理能力不足
3、Hive简介
Hive:构建在Hadoop核心组件基础之上,不支持数据的存储和处理,只是提供了一种编程语言(HiveQL,类似于SQL)。用户利用HiveQL来运行具体的mapreduce任务。
Hadoop:支持大规模数据存储的组件叫HDFS,支持大规模数据处理的组件叫MapReduce。
Hive特性:
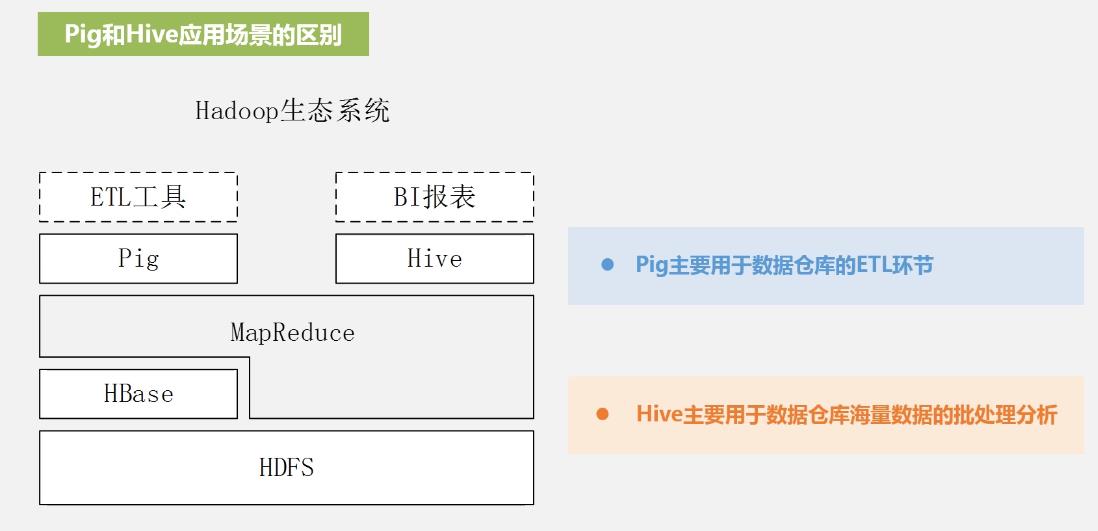
(1)批处理的方式处理海量数据:Hive会把HiveQL语句转换成mapreduce任务进行运行;数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需快速响应给出结果,而且数据本身也不会频繁变化。
(2)Hive提供了一系列对数据进行提取、转换、加载(ETL)的工具:可以存储、查询和分析存储在Hadoop中的大规模数据。

二、Hive系统架构和工作原理
Hive系统架构:
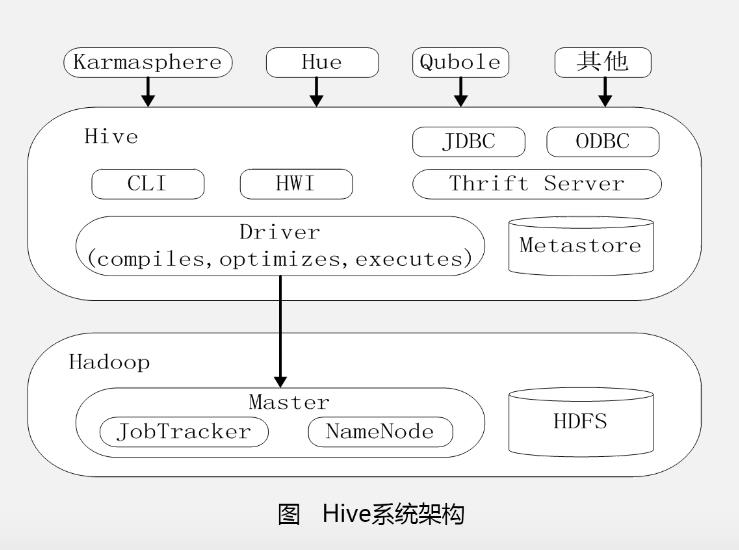
1、对外访问的接口
 2、驱动模块(driver)
2、驱动模块(driver)
包含编译器、优化器、执行器。负责把 hiveQL 语句转换成一系列 mapreduce 作业。
3、元数据存储模块(metastore)
是一个独立的关系型数据库。通过mysql数据库来存储hive的元数据。
SQL转换成MapReduce的原理:
1、连接:利用MapReduce来实现数据库的连接操作。
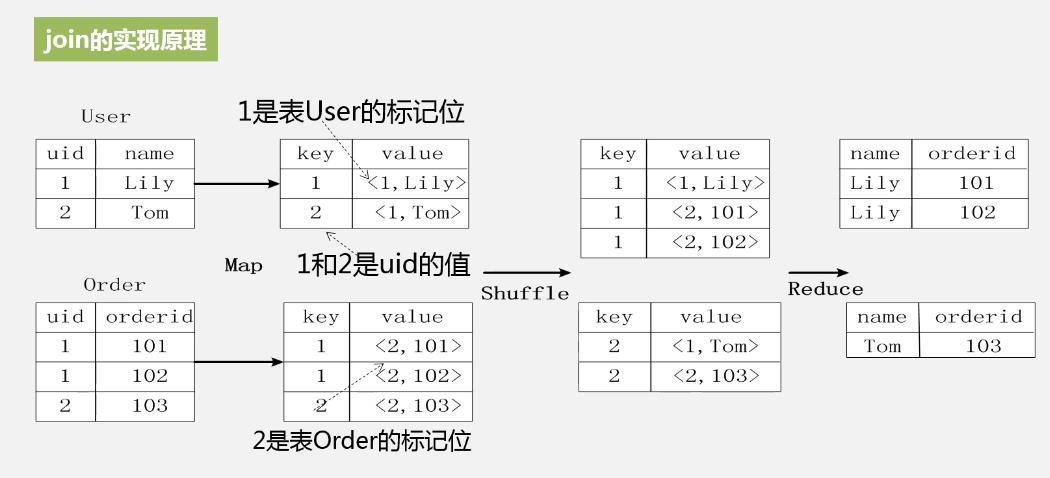
2、当用户向hive输入一段命令或者查询时,hive表需要和Hadoop交互工作来完成该操作。
三、Impala简介
1、Impala简介
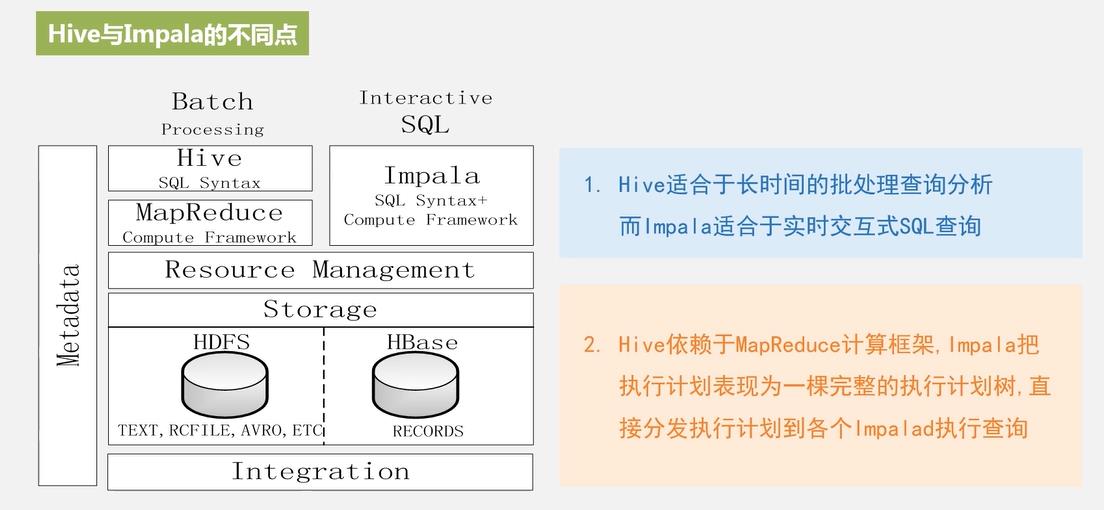
hive:hive是建立在Hadoop平台上,依赖底层的mapreduce和hdfs,所以它的延时比较高。
Impala:是由Cloudera公司开发的新型查询系统,运行需要依赖于hive的元数据,通过分布式查询引擎直接与hdfs和hbase进行交互查询。
2、Impala系统架构
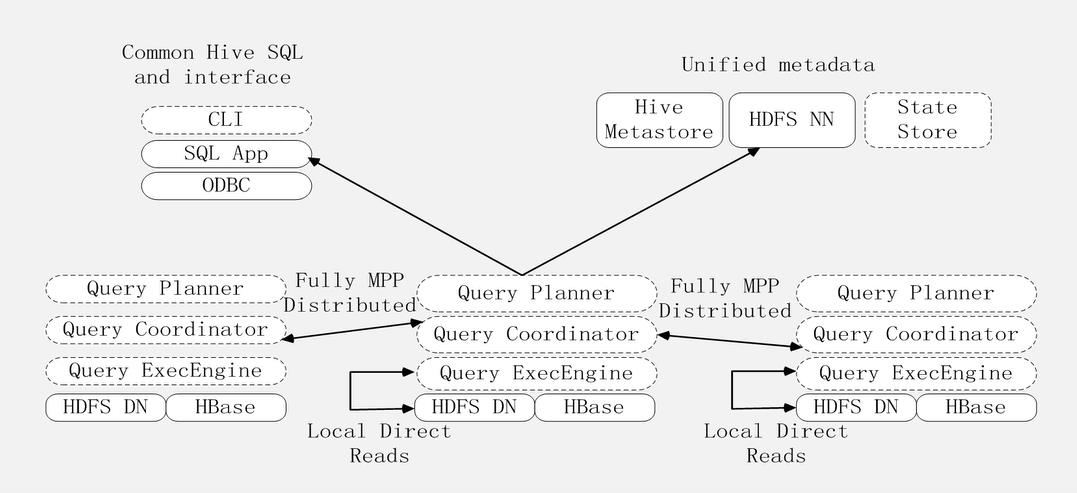
组件:
(1)Impalad:查询计划器、查询协调器、查询引擎。负责协调客户端提交的查询执行,与hdfs的数据运行在同一节点上。

(2)State Store:负责收集分布在集群中各个Impalad进程的资源信息,用于查询调度。
(3)CLI:给用户提供查询的命令行工具。

3、Impala查询执行过程
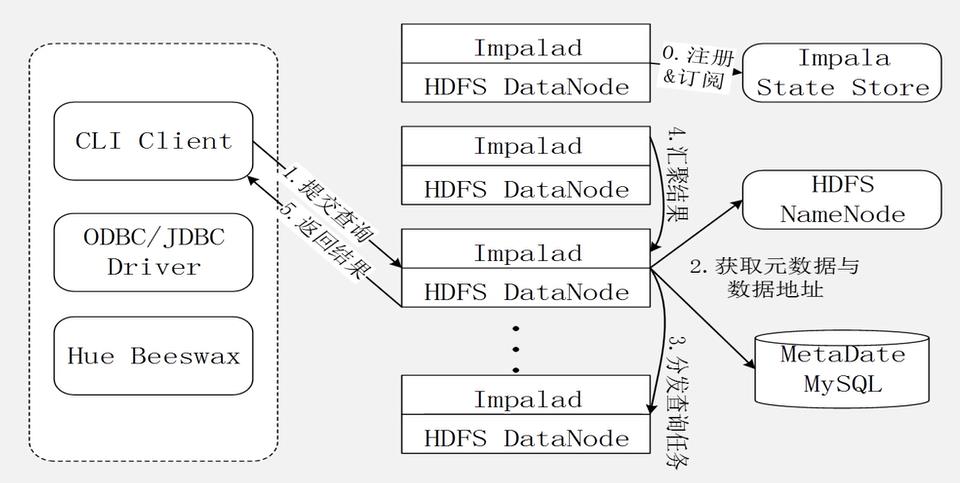
执行查询的具体过程:
(1)当用户提交查询前,Impala先创建一个负责协调客户端提交的查询的Impalad进程,该进程会向Impala state store提交注册订阅信息,state store 会创建一个statestore进程,statesored进程通过创建多个线程来处理Impalad的注册订阅信息。
(2)用户通过CLI客户端提交一个查询到Impalad进程,Impalad的query planner对SQL进行解析,生成解析树,planner把这个查询的解析树变成若干个planfragment(分片),发送到query coordinator。
(3)coordinator通过MySQL元数据库中获取元数据,从hdfs的名称节点中获取数据地址,以得到存储这个查询相关数据的所有数据节点。
(4)coordinator初始化相应Impalad上的任务执行,把查询任务分配给所有存储这个查询相关数据的数据节点。
(5)query executor通过流式交换中间输出,并由query coordinator汇聚来自各个Impalad的结果。
(6)coordinator把汇总后的结果返回给CLI客户端。
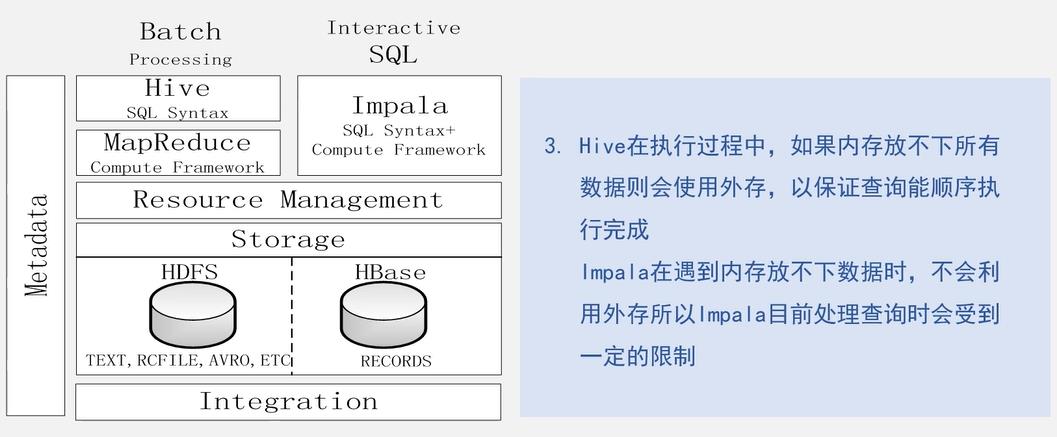
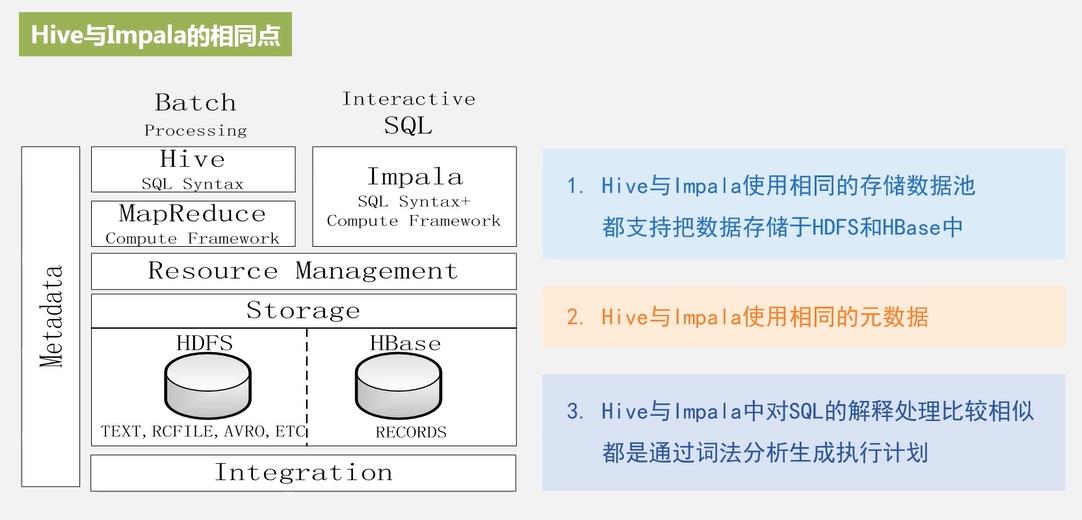
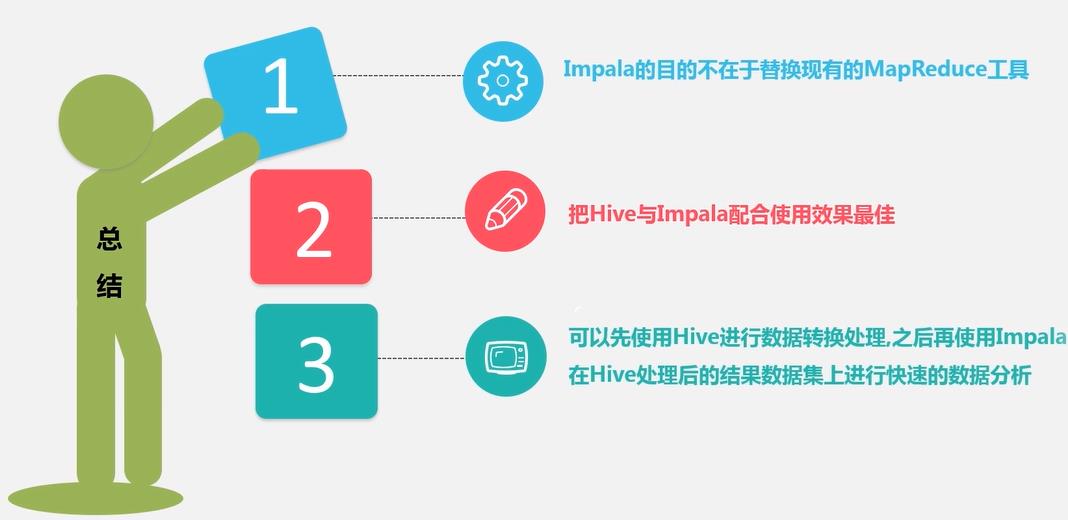
4、Impala和Hive对比?
不同点:
相同点:
以上是关于大数据技术---数据仓库Hive的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_18_大数据离线平台_04_数据分析 + Hive 之 hourly 分析 + 常用 Maven 仓库地址