svm算法是啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了svm算法是啥?相关的知识,希望对你有一定的参考价值。
SVM是由模式识别中广义肖像算法(generalized portrait algorithm)发展而来的分类器,其早期工作来自前苏联学者Vladimir N. Vapnik和Alexander Y. Lerner在1963年发表的研究。
1964年,Vapnik和Alexey Y. Chervonenkis对广义肖像算法进行了进一步讨论并建立了硬边距的线性SVM。此后在二十世纪70-80年代,随着模式识别中最大边距决策边界的理论研究、基于松弛变量的规划问题求解技术的出现,和VC维的提出,SVM被逐步理论化并成为统计学习理论的一部分。

svm算法的性质:
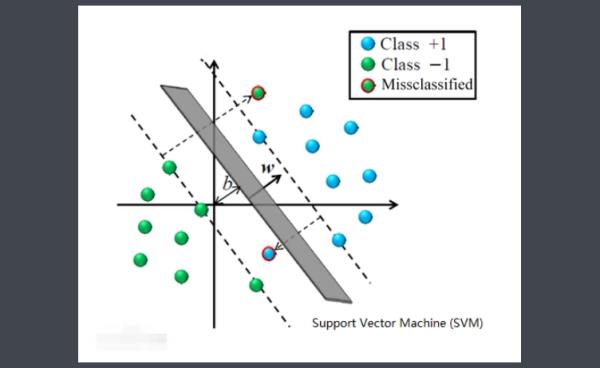
SVM的优化问题同时考虑了经验风险和结构风险最小化,因此具有稳定性。从几何观点,SVM的稳定性体现在其构建超平面决策边界时要求边距最大,因此间隔边界之间有充裕的空间包容测试样本。
SVM使用铰链损失函数作为代理损失,铰链损失函数的取值特点使SVM具有稀疏性,即其决策边界仅由支持向量决定,其余的样本点不参与经验风险最小化。在使用核方法的非线性学习中,SVM的稳健性和稀疏性在确保了可靠求解结果的同时降低了核矩阵的计算量和内存开销。
以上内容参考:百度百科-支持向量机
参考技术ASVM(Support Vector Machine)中文名为支持向量机,是常见的一种判别方法。
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。
数值求解特点:
SVM的求解可以使用二次凸优化问题的数值方法,例如内点法和序列最小优化算法,在拥有充足学习样本时也可使用随机梯度下降。
在二次凸优化问题中,SMO的每步迭代都严格地优化了SVM的对偶问题,且迭代会在有限步后收敛于全局极大值。SMO算法的迭代速度与所选取乘子对KKT条件的偏离程度有关,因此SMO通常采用启发式方法选取拉格朗日乘子。
在每次迭代时,SGD首先判定约束条件,若该样本不满足约束条件,则SGD按学习速率最小化结构风险;若该样本满足约束条件,为SVM的支持向量,则SGD根据正则化系数平衡经验风险和结构风险,即SGD的迭代保持了SVM的稀疏性。
SVM 分类任务中 word2vec 特征的输入格式是啥?
【中文标题】SVM 分类任务中 word2vec 特征的输入格式是啥?【英文标题】:What is the input format for word2vec features in SVM classification task?SVM 分类任务中 word2vec 特征的输入格式是什么? 【发布时间】:2019-07-17 16:23:29 【问题描述】:我正在 scikit learn 中使用线性 SVM 执行二进制分类任务。我使用名义特征和词向量。我使用预训练的 Google word2vec 获得了词向量,但是,我不确定 SVM 如何将词向量作为特征来处理。 似乎我需要将每个向量“拆分”为 300 个单独的特征(= 300 个向量维度),因为我无法将向量作为一个整体传递给 SVM。但这似乎不对,因为向量应该被视为一个特征。 在这种情况下,表示向量的正确方法是什么?
【问题讨论】:
【参考方案1】:许多特征的向量
从 SVM 的角度来看,词向量的每个维度都是一个单独的数字特征 - 该向量中的每个维度都代表一个代表不同事物的数字度量。
这同样适用于非 SVM 分类器。例如,如果您有一个神经网络,并且您的输入特征是长度为 300 的词向量,并且(为了一个粗略的例子)有点说明该词是否大写,那么您将连接这些东西并将有 301 个数字作为您的输入;您会将该特征视为 300 个维度中的每一个。
【讨论】:
感谢您的快速回复! 所以你想说我们必须取word2vec特征的平均值。 @BilalChandio 不,我绝对不想这么说;我打算向 OP 保证,是的,将向量“拆分”为 300 个独立特征是合适的方法。我看不出答案中建议取特征的平均值,如果你能指出这种解释,我会改变答案来修复它。以上是关于svm算法是啥?的主要内容,如果未能解决你的问题,请参考以下文章