机器学习SVM算法数字识别器
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习SVM算法数字识别器相关的知识,希望对你有一定的参考价值。
目录
1 SVM算法api
1.1 SVM算法api综述
-
SVM方法既可以用于分类(二/多分类),也可用于回归和异常值检测。
-
SVM具有良好的鲁棒性,对未知数据拥有很强的泛化能力,特别是在数据量较少的情况下,相较其他传统机器学习算法具有更优的性能。
使用SVM作为模型时,通常采用如下流程:
- 对样本数据进行归一化
- 应用核函数对样本进行映射**(最常采用和核函数是RBF和Linear,在样本线性可分时,Linear效果要比RBF好)**
- 用cross-validation和grid-search对超参数进行优选
- 用最优参数训练得到模型
- 测试
sklearn中支持向量分类主要有三种方法:SVC、NuSVC、LinearSVC,扩展为三个支持向量回归方法:SVR、NuSVR、LinearSVR。
- SVC和NuSVC方法基本一致,唯一区别就是损失函数的度量方式不同
- NuSVC中的nu参数和SVC中的C参数;
- LinearSVC是实现线性核函数的支持向量分类,没有kernel参数。
1.2 SVC
class sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3,coef0=0.0,random_state=None)
-
C:
惩罚系数,用来控制损失函数的惩罚系数,类似于线性回归中的正则化系数。
- C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样会出现训练集测试时准确率很高,但泛化能力弱,容易导致过拟合。
- C值小,对误分类的惩罚减小,容错能力增强,泛化能力较强,但也可能欠拟合。
-
kernel:
算法中采用的核函数类型,核函数是用来将非线性问题转化为线性问题的一种方法。
- 参数选择有RBF, Linear, Poly, Sigmoid或者自定义一个核函数。
- 默认的是"RBF",即径向基核,也就是高斯核函数;
- 而Linear指的是线性核函数,
- Poly指的是多项式核,
- Sigmoid指的是双曲正切函数tanh核;。
- 参数选择有RBF, Linear, Poly, Sigmoid或者自定义一个核函数。
-
degree:
- 当指定kernel为’poly’时,表示选择的多项式的最高次数,默认为三次多项式;
- 若指定kernel不是’poly’,则忽略,即该参数只对’poly’有用。
- 多项式核函数是将低维的输入空间映射到高维的特征空间。
-
coef0:
核函数常数值(y=kx+b中的b值),
- 只有‘poly’和‘sigmoid’核函数有,默认值是0。
1.3 NuSVC
class sklearn.svm.NuSVC(nu=0.5)
- nu: 训练误差部分的上限和支持向量部分的下限,取值在(0,1)之间,默认是0.5
1.4 LinearSVC
class sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', dual=True, C=1.0)
- penalty:正则化参数,
- L1和L2两种参数可选,仅LinearSVC有。
- loss:损失函数,
- 有hinge和squared_hinge两种可选,前者又称L1损失,后者称为L2损失,默认是squared_hinge,
- 其中hinge是SVM的标准损失,squared_hinge是hinge的平方
- dual:是否转化为对偶问题求解,默认是True。
- C:惩罚系数,
- 用来控制损失函数的惩罚系数,类似于线性回归中的正则化系数。
1.5 小结
- SVM的核方法
- 将原始输入空间映射到新的特征空间,从而,使得原本线性不可分的样本可能在核空间可分。
- SVM算法api
- sklearn.svm.SVC
- sklearn.svm.NuSVC
- sklearn.svm.LinearSVC
2 案例:数字识别器
2.1 案例背景介绍

MNIST(“修改后的国家标准与技术研究所”)是计算机视觉事实上的“hello world”数据集。自1999年发布以来,这一经典的手写图像数据集已成为分类算法基准测试的基础。随着新的机器学习技术的出现,MNIST仍然是研究人员和学习者的可靠资源。
本次案例中,我们的目标是从数万个手写图像的数据集中正确识别数字。
2.2 数据介绍
数据文件train.csv和test.csv包含从0到9的手绘数字的灰度图像。
每个图像的高度为28个像素,宽度为28个像素,总共为784个像素。
每个像素具有与其相关联的单个像素值,指示该像素的亮度或暗度,较高的数字意味着较暗。该像素值是0到255之间的整数,包括0和255。
训练数据集(train.csv)有785列。第一列称为“标签”,是用户绘制的数字。其余列包含关联图像的像素值。
训练集中的每个像素列都具有像pixelx这样的名称,其中x是0到783之间的整数,包括0和783。为了在图像上定位该像素,假设我们已经将x分解为x = i * 28 + j,其中i和j是0到27之间的整数,包括0和27。然后,pixelx位于28 x 28矩阵的第i行和第j列上(索引为零)。
例如,pixel31表示从左边开始的第四列中的像素,以及从顶部开始的第二行,如下面的ascii图中所示。
在视觉上,如果我们省略“像素”前缀,像素组成图像如下:
000 001 002 003 ... 026 027
028 029 030 031 ... 054 055
056 057 058 059 ... 082 083
| | | | ...... | |
728 729 730 731 ... 754 755
756 757 758 759 ... 782 783
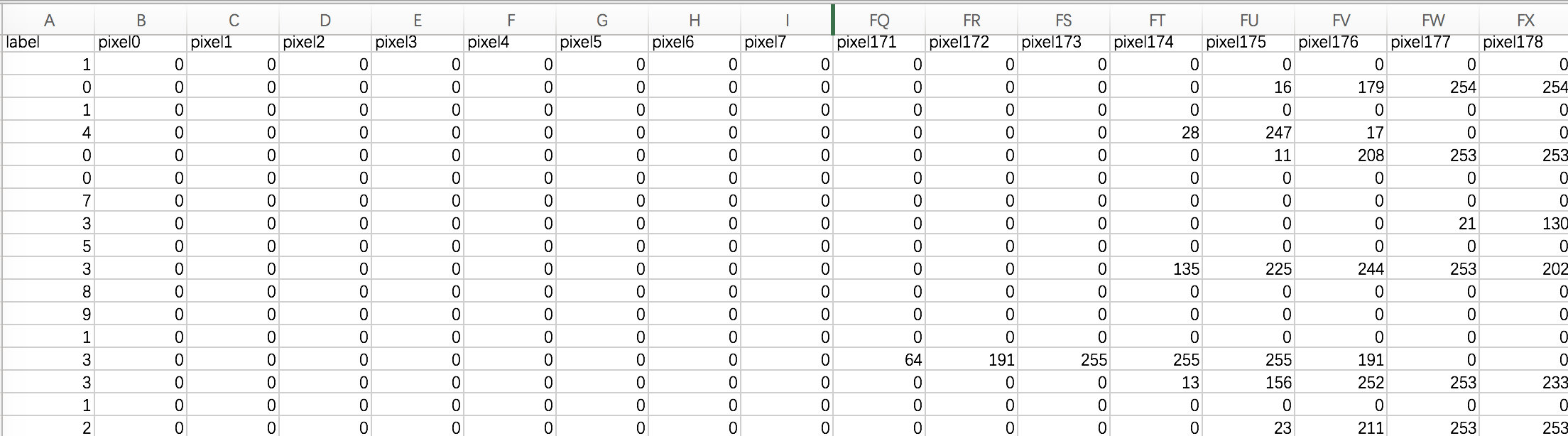
测试数据集(test.csv)与训练集相同,只是它不包含“标签”列。
2.3 案例实现
参考:案例_手写数字分类.ipynb
3 SVM总结
3.1 SVM基本综述
- SVM是一种二类分类模型。
- 它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。
- 1)当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
- 2)当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
- 3)当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
3.2 SVM优缺点
- SVM的优点:
- 在高维空间中非常高效;
- 即使在数据维度比样本数量大的情况下仍然有效;
- 在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的;
- 通用性:不同的核函数与特定的决策函数一一对应;
- SVM的缺点:
- 如果特征数量比样本数量大得多,在选择核函数时要避免过拟合;
- 对缺失数据敏感;
- 对于核函数的高维映射解释力不强
以上是关于机器学习SVM算法数字识别器的主要内容,如果未能解决你的问题,请参考以下文章