机器学习SVM算法入门
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习SVM算法入门相关的知识,希望对你有一定的参考价值。
目录
1 SVM算法简介
1.1 SVM算法导入
在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
魔鬼在桌子上似乎有规律放了两种颜色的球,说:
“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”
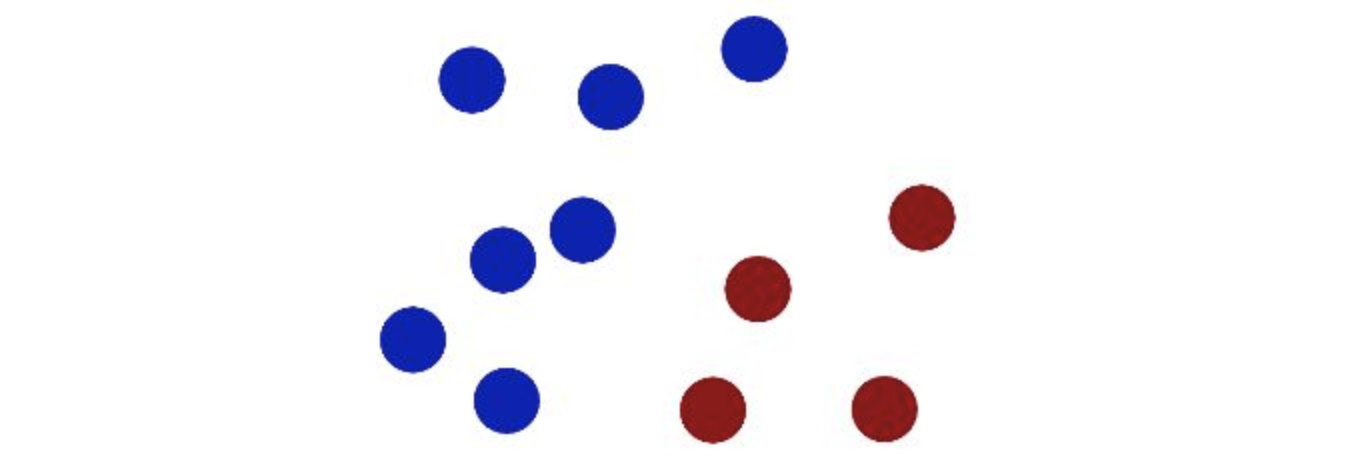
于是大侠这样放,干的不错?

然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。
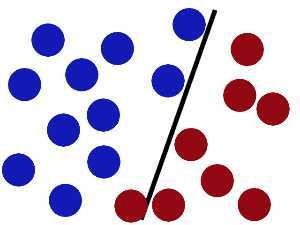
怎么办??
把分解的小棍儿变粗。
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
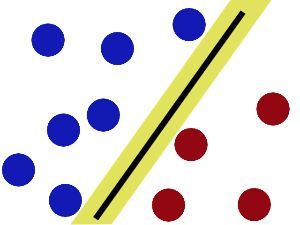
现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。

然后,在SVM 工具箱中有另一个更加重要的技巧( trick)。 魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。

现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?
当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。
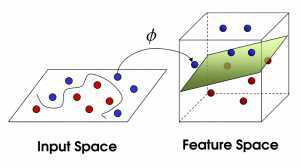
现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。

再之后,无聊的大人们,把上面的物体起了别名:
- 球—— 「data」数据
- 棍子—— 「classifier」分类
- 最大间隙——「optimization」最优化
- 拍桌子——「kernelling」核方法
- 纸——「hyperplane」超平面
案例来源:http://bytesizebio.net/2014/02/05/support-vector-machines-explained-well/
支持向量机直观感受:https://www.youtube.com/watch?v=3liCbRZPrZA
1.2 SVM算法定义
1.2.1 定义
SVM:SVM全称是supported vector machine(支持向量机),即寻找到一个超平面使样本分成两类,并且间隔最大。
SVM能够执行线性或非线性分类、回归,甚至是异常值检测任务。它是机器学习领域最受欢迎的模型之一。SVM特别适用于中小型复杂数据集的分类。
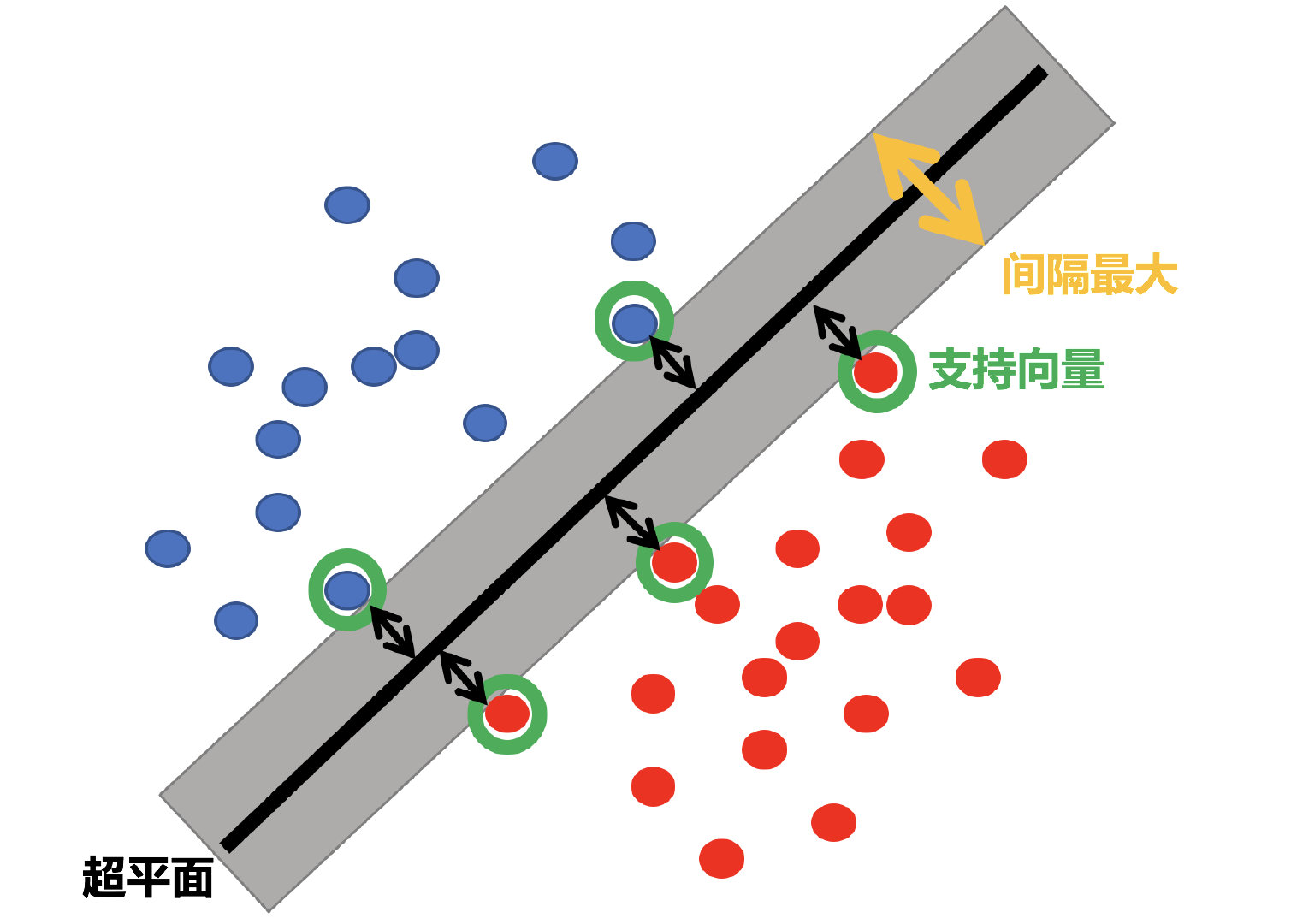
1.2.2 超平面最大间隔介绍
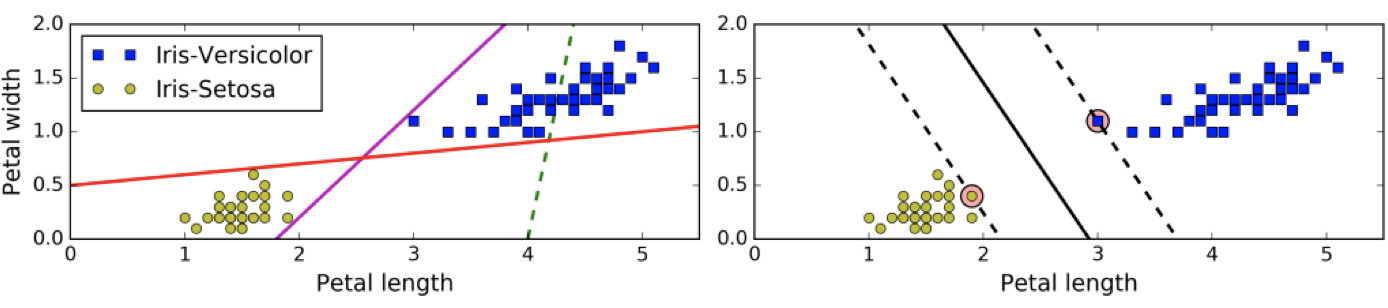
上左图显示了三种可能的线性分类器的决策边界:
虚线所代表的模型表现非常糟糕,甚至都无法正确实现分类。其余两个模型在这个训练集上表现堪称完美,但是它们的决策边界与实例过于接近,导致在面对新实例时,表现可能不会太好。
右图中的实线代表SVM分类器的决策边界,不仅分离了两个类别,且尽可能远离最近的训练实例。
1.2.3 硬间隔和软间隔
1.2.3.1 硬间隔分类
在上面我们使用超平面进行分割数据的过程中,如果我们严格地让所有实例都不在最大间隔之间,并且位于正确的一边,这就是硬间隔分类。
硬间隔分类有两个问题,首先,它只在数据是线性可分离的时候才有效;其次,它对异常值非常敏感。
当有一个额外异常值的鸢尾花数据:左图的数据根本找不出硬间隔,而右图最终显示的决策边界与我们之前所看到的无异常值时的决策边界也大不相同,可能无法很好地泛化。
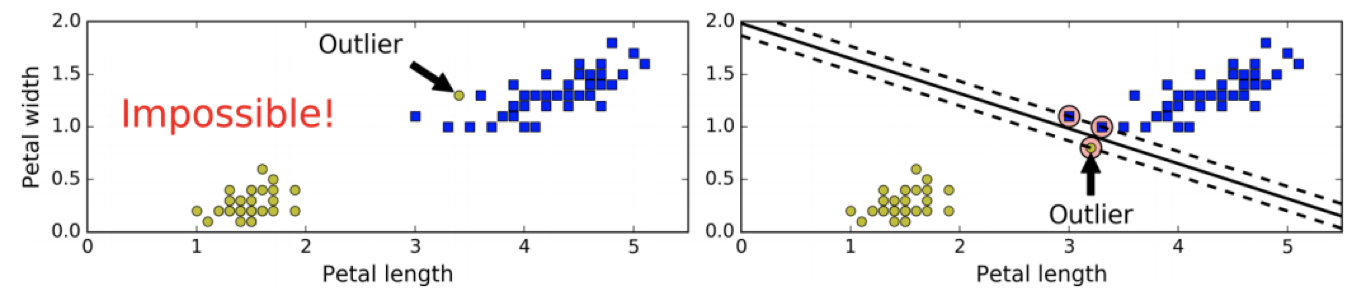
1.2.3.2 软间隔分类
要避免这些问题,最好使用更灵活的模型。目标是尽可能在保持最大间隔宽阔和限制间隔违例(即位于最大间隔之上,甚至在错误的一边的实例)之间找到良好的平衡,这就是软间隔分类。
要避免这些问题,最好使用更灵活的模型。目标是尽可能在保持间隔宽阔和限制间隔违例之间找到良好的平衡,这就是软间隔分类。
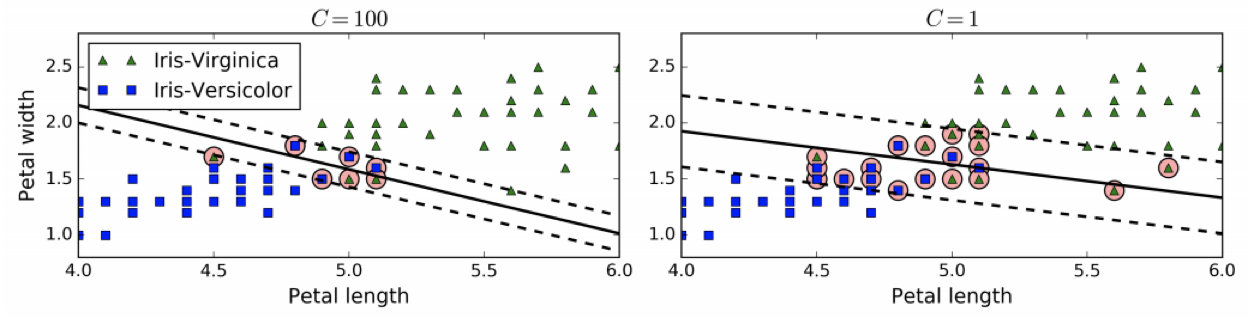
在Scikit-Learn的SVM类中,可以通过超参数C来控制这个平衡:C值越小,则间隔越宽,但是间隔违例也会越多。上图显示了在一个非线性可分离数据集上,两个软间隔SVM分类器各自的决策边界和间隔。
左边使用了高C值,分类器的错误样本(间隔违例)较少,但是间隔也较小。
右边使用了低C值,间隔大了很多,但是位于间隔上的实例也更多。看起来第二个分类器的泛化效果更好,因为大多数间隔违例实际上都位于决策边界正确的一边,所以即便是在该训练集上,它做出的错误预测也会更少。
。
1.3 小结
- SVM算法定义【了解】
- 寻找到一个超平面使样本分成两类,并且间隔最大。
- 硬间隔和软间隔【知道】
- 硬间隔
- 只有在数据是线性可分离的时候才有效
- 对异常值非常敏感
- 软间隔
- 尽可能在保持最大间隔宽阔和限制间隔违例之间找到良好的平衡
- 硬间隔
2 SVM算法api初步使用
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
在拟合后, 这个模型可以用来预测新的值:
>>> clf.predict([[2., 2.]])
array([1])
以上是关于机器学习SVM算法入门的主要内容,如果未能解决你的问题,请参考以下文章