美多商城项目之商品搜索商品详情页页面静态化用户浏览记录
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美多商城项目之商品搜索商品详情页页面静态化用户浏览记录相关的知识,希望对你有一定的参考价值。
一、商品搜索
1.1 全文检索方案Elasticsearch
1. 全文检索和搜索引擎原理
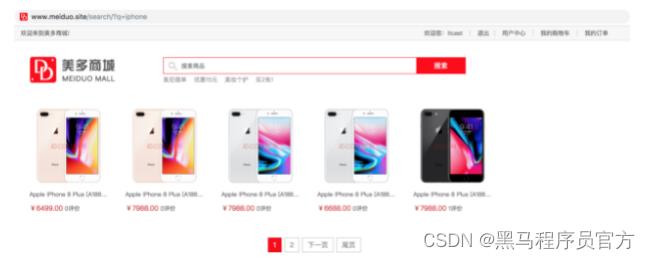
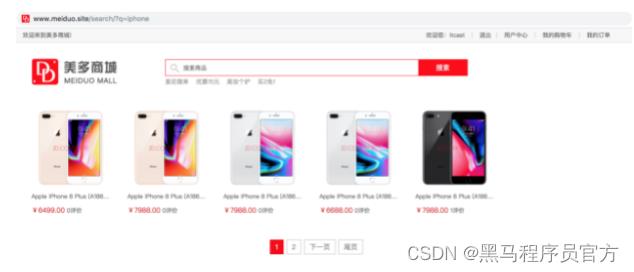
商品搜索需求
- 当用户在搜索框输入商品关键字后,我们要为用户提供相关的商品搜索结果。
商品搜索实现
- 可以选择使用模糊查询
like关键字实现。 - 但是 like 关键字的效率极低。
- 查询需要在多个字段中进行,使用 like 关键字也不方便。
全文检索方案
- 我们引入全文检索的方案来实现商品搜索。
- 全文检索即在指定的任意字段中进行检索查询。
- 全文检索方案需要配合搜索引擎来实现。
搜索引擎原理
- 搜索引擎进行全文检索时,会对数据库中的数据进行一遍预处理,单独建立起一份索引结构数据。
- 索引结构数据类似新华字典的索引检索页,里面包含了关键词与词条的对应关系,并记录词条的位置。
- 搜索引擎进行全文检索时,将关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。

结论:
- 搜索引擎建立索引结构数据,类似新华字典的索引检索页,全文检索时,关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。
2. Elasticsearch介绍
实现全文检索的搜索引擎,首选的是
Elasticsearch。
- Elasticsearch是用 Java 实现的,开源的搜索引擎。
- 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github等都采用它。
- Elasticsearch 的底层是开源库Lucene 。但是,没法直接使用 Lucene,必须自己写代码去调用它的接口。
分词说明
- 搜索引擎在对数据构建索引时,需要进行分词处理。
- 分词是指将一句话拆解成多个单字或词,这些字或词便是这句话的关键词。
- 比如:
我是中国人- 分词后:
我、是、中、国、人、中国等等都可以是这句话的关键字。
- 分词后:
- Elasticsearch 不支持对中文进行分词建立索引,需要配合扩展
elasticsearch-analysis-ik来实现中文分词处理。
3. 使用Docker安装Elasticsearch
1.获取Elasticsearch-ik镜像
# 从仓库拉取镜像
$ sudo docker image pull delron/elasticsearch-ik:2.4.6-1.0
# 解压教学资料中本地镜像
$ sudo docker load -i elasticsearch-ik-2.4.6_docker.tar
2.配置Elasticsearch-ik
- 将教学资料中的
elasticsearc-2.4.6目录拷贝到home目录下。 - 修改
/home/ubuntu/Desktop/elasticsearc-2.4.6/config/elasticsearch.yml第54行。 - 更改ip地址为本机真实ip地址。

3.使用Docker运行Elasticsearch-ik
sudo docker run -dti --name=elasticsearch --network=host -v /home/ubuntu/Desktop/elasticsearch-2.4.6/config:/usr/share/elasticsearch/config delron/elasticsearch-ik:2.4.6-1.0
1.2 Haystack扩展建立索引
提示:
- Elasticsearch的底层是开源库Lucene。但是没法直接使用 Lucene,必须自己写代码去调用它的接口。
思考:
- 我们如何对接 Elasticsearch服务端?
解决方案:
- Haystack
1. Haystack介绍和安装配置
1.Haystack介绍
- Haystack 是在Django中对接搜索引擎的框架,搭建了用户和搜索引擎之间的沟通桥梁。
- 我们在Django中可以通过使用 Haystack 来调用 Elasticsearch 搜索引擎。
- Haystack 可以在不修改代码的情况下使用不同的搜索后端(比如
Elasticsearch、Whoosh、Solr等等)。
2.Haystack安装
$ pip install django-haystack
$ pip install elasticsearch==2.4.1
3.Haystack注册应用和路由
INSTALLED_APPS = [
'haystack', # 全文检索
]
4.Haystack配置
- 在配置文件中配置Haystack为搜索引擎后端
- 文档
# Haystack
HAYSTACK_CONNECTIONS =
'default':
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'URL': 'http://192.168.103.158:9200/', # Elasticsearch服务器ip地址,端口号固定为9200
'INDEX_NAME': 'meiduo_mall', # Elasticsearch建立的索引库的名称
,
# 当添加、修改、删除数据时,自动生成索引
# HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
重要提示:
- HAYSTACK_SIGNAL_PROCESSOR配置项保证了在Django运行起来后,有新的数据产生时,Haystack仍然可以让Elasticsearch实时生成新数据的索引
2. Haystack建立数据索引
1.创建索引类
- 通过创建索引类,来指明让搜索引擎对哪些字段建立索引,也就是可以通过哪些字段的关键字来检索数据。
- 本项目中对SKU信息进行全文检索,所以在
goods应用中新建search_indexes.py文件,用于存放索引类。
from haystack import indexes
from .models import SKU
class SKUIndex(indexes.SearchIndex, indexes.Indexable):
"""SKU索引数据模型类"""
text = indexes.CharField(document=True, use_template=True)
def get_model(self):
"""返回建立索引的模型类"""
return SKU
def index_queryset(self, using=None):
"""返回要建立索引的数据查询集"""
return self.get_model().objects.filter(is_launched=True)
- 索引类SKUIndex说明:
- 在
SKUIndex建立的字段,都可以借助Haystack由Elasticsearch搜索引擎查询。 - 其中
text字段我们声明为document=True,表名该字段是主要进行关键字查询的字段。 text字段的索引值可以由多个数据库模型类字段组成,具体由哪些模型类字段组成,我们用use_template=True表示后续通过模板来指明。
- 在
2.创建
text字段索引值模板文件
- 在
templates目录中创建text字段使用的模板文件 - 具体在
templates/search/indexes/goods/sku_text.txt文件中定义
object.id
object.name
object.caption
- 模板文件说明:当将关键词通过text参数名传递时
- 此模板指明SKU的
id、name、caption作为text字段的索引值来进行关键字索引查询。
- 此模板指明SKU的
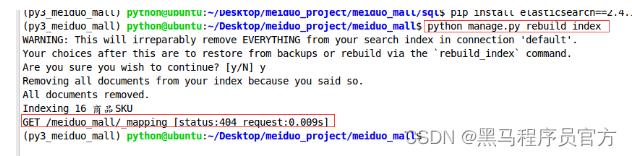
3.手动生成初始索引
$ python manage.py rebuild_index
3. 全文检索测试
1.准备测试表单
- 请求方法:
GET - 请求地址:
/search/ - 请求参数:
q

4. 添加后端逻辑
在 goods.views.py 文件中添加如下代码:
# 导入:
from haystack.views import SearchView
from django.http import JsonResponse
class MySearchView(SearchView):
'''重写SearchView类'''
def create_response(self):
# 获取搜索结果
context = self.get_context()
data_list = []
for sku in context['page'].object_list:
data_list.append(
'id':sku.object.id,
'name':sku.object.name,
'price':sku.object.price,
'default_image_url':sku.object.default_image.url,
'searchkey':context.get('query'),
'page_size':context['page'].paginator.num_pages,
'count':context['page'].paginator.count
)
# 拼接参数, 返回
return JsonResponse(data_list, safe=False)
5. 添加子路由
goods.urls.py
# 搜索路由--千万注意: 没有as_view()
path('search/', views.MySearchView()),1.3 渲染商品搜索结果
Haystack搜索结果分页
1.设置每页返回数据条数
- 通过
HAYSTACK_SEARCH_RESULTS_PER_PAGE可以控制每页显示数量 - 每页显示五条数据:
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 5
二、商品详情页
2.1 商品详情页分析和准备
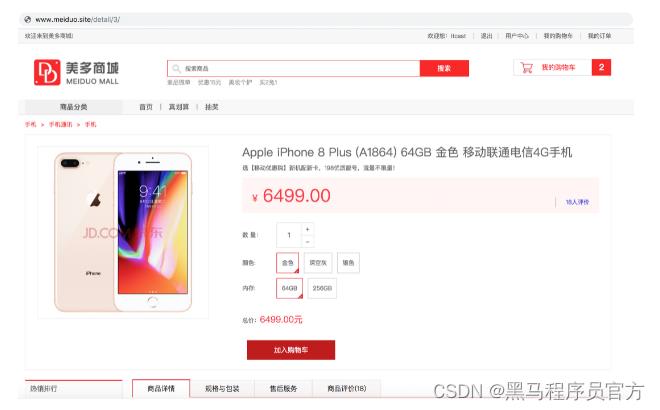
1. 商品详情页组成结构分析
1.商品频道分类
- 已经提前封装在
contents.utils.py文件中,直接调用方法即可。
2.面包屑导航
- 已经提前封装在
goods.utils.py文件中,直接调用方法即可。
3.热销排行
- 该接口已经在商品列表页中实现完毕,前端直接调用接口即可。
4.商品SKU信息(详情信息)
- 通过
sku_id可以找到SKU信息,然后渲染模板即可。 - 使用Ajax实现局部刷新效果。
5.SKU规格信息
- 通过
SKU可以找到SPU规格和SKU规格信息。
6.商品详情介绍、规格与包装、售后服务
- 通过
SKU可以找到SPU信息,SPU中可以查询出商品详情介绍、规格与包装、售后服务。
7.商品评价
- 商品评价需要在生成了订单,对订单商品进行评价后再实现,商品评价信息是动态数据。
- 使用Ajax实现局部刷新效果。
2. 商品详情页接口设计和定义
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | GET |
| 请求地址 | /detail/(?P<sku_id>\\d+)/ |
2.请求参数:路径参数
| 参数名 | 类型 | 是否必传 | 说明 |
|---|---|---|---|
| sku_id | string | 是 | 商品SKU编号 |
3. 商品详情页初步渲染
渲染商品频道分类、面包屑导航、商品热销排行
- 将原先在商品列表页实现的代码拷贝到商品详情页即可。
- 添加
detail.js
class DetailView(View):
"""商品详情页"""
def get(self, request, sku_id):
"""提供商品详情页"""
# 获取当前sku的信息
try:
sku = SKU.objects.get(id=sku_id)
except SKU.DoesNotExist:
return render(request, '404.html')
# 查询商品频道分类
categories = get_categories()
# 查询面包屑导航
breadcrumb = get_breadcrumb(sku.category)
# 渲染页面
context =
'categories':categories,
'breadcrumb':breadcrumb,
'sku':sku,
return render(request, 'detail.html', context)2.2 展示详情页数据
1. 查询和渲染SKU规格信息
查询SKU规格信息
class DetailView(View):
"""商品详情页"""
def get(self, request, sku_id):
"""提供商品详情页"""
# 获取当前sku的信息
try:
sku = models.SKU.objects.get(id=sku_id)
except models.SKU.DoesNotExist:
return render(request, '404.html')
# 查询商品频道分类
categories = get_categories()
# 查询面包屑导航
breadcrumb = get_breadcrumb(sku.category)
# 查询SKU规格信息
goods_specs=goods_specs = get_goods_and_spec(sku_id)
# 渲染页面
context =
'categories':categories,
'breadcrumb':breadcrumb,
'sku':sku,
'specs': goods_specs,
return render(request, 'detail.html', context)2.3 统计分类商品访问量
提示:
- 统计分类商品访问量 是统计一天内该类别的商品被访问的次数。
- 需要统计的数据,包括商品分类,访问次数,访问时间。
- 一天内,一种类别,统计一条记录。

1. 统计分类商品访问量模型类
模型类定义在
goods.models.py中,然后完成迁移建表。
class GoodsVisitCount(BaseModel):
"""统计分类商品访问量模型类"""
category = models.ForeignKey(GoodsCategory, on_delete=models.CASCADE, verbose_name='商品分类')
count = models.IntegerField(verbose_name='访问量', default=0)
date = models.DateField(auto_now_add=True, verbose_name='统计日期')
class Meta:
db_table = 'tb_goods_visit'
verbose_name = '统计分类商品访问量'
verbose_name_plural = verbose_name
2. 统计分类商品访问量后端逻辑
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | POST |
| 请求地址 | /detail/visit/(?P<category_id>\\d+)/ |
2.请求参数:路径参数
| 参数名 | 类型 | 是否必传 | 说明 |
|---|---|---|---|
| category_id | string | 是 | 商品分类id |
3.响应结果:JSON
| 字段 | 说明 |
|---|---|
| code | 状态码 |
| errmsg | 错误信息 |
4.后端接口定义和实现,
- 如果访问记录存在,说明今天不是第一次访问,不新建记录,访问量直接累加。
- 如果访问记录不存在,说明今天是第一次访问,新建记录并保存访问量。
class DetailVisitView(View):
"""详情页分类商品访问量"""
def post(self, request, category_id):
try:
# 1.获取当前商品
category = GoodsCategory.objects.get(id=category_id)
except Exception as e:
return JsonResponse('code': 400, 'errmsg': '缺少必传参数')
# 2.查询日期数据
from datetime import date
# 获取当天日期
today_date = date.today()
from apps.goods.models import GoodsVisitCount
try:
# 3.如果有当天商品分类的数据 就累加数量
count_data = category.goodsvisitcount_set.get(date=today_date)
except:
# 4. 没有, 就新建之后在增加
count_data = GoodsVisitCount()
try:
count_data.count += 1
count_data.category = category
count_data.save()
except Exception as e:
return JsonResponse('code': 400, 'errmsg': '新增失败')
return JsonResponse('code': 0, 'errmsg': 'OK')三、页面静态化
3.1 首页广告页面静态化
思考:
- 美多商城的首页访问频繁,而且查询数据量大,其中还有大量的循环处理。
问题:
- 用户访问首页会耗费服务器大量的资源,并且响应数据的效率会大大降低。
解决:
- 页面静态化
1. 页面静态化介绍
1.为什么要做页面静态化
- 减少数据库查询次数。
- 提升页面响应效率。
2.什么是页面静态化
- 将动态渲染生成的页面结果保存成html文件,放到静态文件服务器中。
- 用户直接去静态服务器,访问处理好的静态html文件。
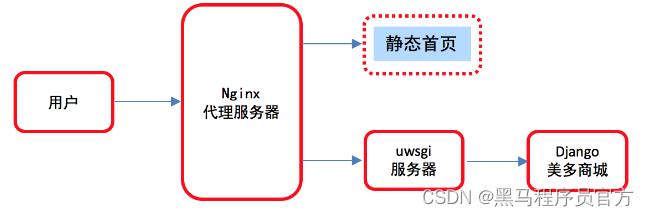
3.页面静态化注意点
- 用户相关数据不能静态化:
- 用户名、购物车等不能静态化。
- 动态变化的数据不能静态化:
- 热销排行、新品推荐、分页排序数据等等。
- 不能静态化的数据处理:
- 可以在用户得到页面后,在页面中向后端发送Ajax请求获取相关数据。
- 直接使用模板渲染出来。
- 其他合理的处理方式等等。
2. 首页页面静态化实现
1.首页页面静态化实现步骤
- 查询首页相关数据
- 获取首页模板文件
- 渲染首页html字符串
- 将首页html字符串写入到指定目录,命名'index.html'
2.首页页面静态化实现
import os
import time
from django.conf import settings
from django.template import loader
from apps.contents.models import ContentCategory
from apps.contents.utils import get_categories
def generate_static_index_html():
"""
生成静态的主页html文件
"""
print('%s: generate_static_index_html' % time.ctime())
# 获取商品频道和分类
categories = get_categories()
# 广告内容
contents =
content_categories = ContentCategory.objects.all()
for cat in content_categories:
contents[cat.key] = cat.content_set.filter(status=True).order_by('sequence')
# 渲染模板
context =
'categories': categories,
'contents': contents
# 获取首页模板文件
template = loader.get_template('index.html')
# 渲染首页html字符串
html_text = template.render(context)
# 将首页html字符串写入到指定目录,命名'index.html'
file_path = os.path.join(os.path.dirname(settings.BASE_DIR), 'front_end_pc/index.html')
with open(file_path, 'w', encoding='utf-8') as f:
f.write(html_text)
3.首页页面静态化测试效果
提示:静态首页的访问测试
3. 定时任务crontab静态化首页
重要提示:
- 对于首页的静态化,考虑到页面的数据可能由多名运营人员维护,并且经常变动,所以将其做成定时任务,即定时执行静态化。
- 在Django执行定时任务,可以通过
django-crontab扩展来实现。
1.安装 django-crontab
$ pip install django-crontab
2.注册 django-crontab 应用
INSTALLED_APPS = [
'django_crontab', # 定时任务
]
3.设置定时任务
定时时间基本格式 :
* * * * *
分 时 日 月 周 命令
M: 分钟(0-59)。每分钟用 * 或者 */1 表示
H:小时(0-23)。(0表示0点)
D:天(1-31)。
m: 月(1-12)。
d: 一星期内的天(0~6,0为星期天)。
定时任务分为三部分定义:
- 任务时间
- 任务方法
- 任务日志
CRONJOBS = [
# 每1分钟生成一次首页静态文件
('*/1 * * * *', 'apps.contents.crons.generate_static_index_html', '>> ' + os.path.join(BASE_DIR, 'logs/crontab.log'))
]
解决 crontab 中文问题
- 在定时任务中,如果出现非英文字符,会出现字符异常错误
CRONTAB_COMMAND_PREFIX = 'LANG_ALL=zh_cn.UTF-8'
4.管理定时任务
# 添加定时任务到系统中
$ python manage.py crontab add
# 显示已激活的定时任务
$ python manage.py crontab show
# 移除定时任务
$ python manage.py crontab remove

3.2 商品详情页面静态化
提示:
- 商品详情页查询数据量大,而且是用户频繁访问的页面。
- 类似首页广告,为了减少数据库查询次数,提升页面响应效率,我们也要对详情页进行静态化处理。
静态化说明:
- 首页广告的数据变化非常的频繁,所以我们最终使用了
定时任务进行静态化。- 详情页的数据变化的频率没有首页广告那么频繁,而且是当SKU信息有改变时才要更新的,所以我们采用新的静态化方案。
- 方案一:通过Python脚本手动一次性批量生成所有商品静态详情页。
- 方案二:后台运营人员修改了SKU信息时,异步的静态化对应的商品详情页面。
- 我们在这里先使用方案一来静态详情页。当有运营人员参与时才会补充方案二。
注意:
- 用户数据和购物车数据不能静态化。
- 热销排行和商品评价不能静态化。
1. 定义批量静态化详情页脚本文件
1.准备脚本目录和Python脚本文件
2.指定Python脚本解析器
#!/usr/bin/env python
3.添加Python脚本导包路径
#!/usr/bin/env python
import sys
sys.path.insert(0, '../')
4.设置Python脚本Django环境
#!/usr/bin/env python
import sys
sys.path.insert(0, '../')
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "meiduo_mall.settings")
import django
django.setup()
5.编写静态化详情页Python脚本代码
#!/usr/bin/env python
import sys
sys.path.insert(0, '../')
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "meiduo_mall.settings")
import django
django.setup()
from django.template import loader
from django.conf import settings
from apps.goods import models
from apps.contents.utils import get_categories
from apps.goods.utils import get_breadcrumb
def generate_static_sku_detail_html(sku_id):
"""
生成静态商品详情页面
:param sku_id: 商品sku id
"""
# 获取当前sku的信息
sku = models.SKU.objects.get(id=sku_id)
# 查询商品频道分类
categories = get_categories()
# 查询面包屑导航
breadcrumb = get_breadcrumb(sku.category)
# 构建当前商品的规格键
sku_specs = sku.specs.order_by('spec_id')
sku_key = []
for spec in sku_specs:
sku_key.append(spec.option.id)
# 获取当前商品的所有SKU
skus = sku.spu.sku_set.all()
# 构建不同规格参数(选项)的sku字典
spec_sku_map =
for s in skus:
# 获取sku的规格参数
s_specs = s.specs.order_by('spec_id')
# 用于形成规格参数-sku字典的键
key = []
for spec in s_specs:
key.append(spec.option.id)
# 向规格参数-sku字典添加记录
spec_sku_map[tuple(key)] = s.id
# 获取当前商品的规格信息
goods_specs = sku.spu.specs.order_by('id')
# 若当前sku的规格信息不完整,则不再继续
if len(sku_key) < len(goods_specs):
return
for index, spec in enumerate(goods_specs):
# 复制当前sku的规格键
key = sku_key[:]
# 该规格的选项
spec_options = spec.options.all()
for option in spec_options:
# 在规格参数sku字典中查找符合当前规格的sku
key[index] = option.id
option.sku_id = spec_sku_map.get(tuple(key))
spec.spec_options = spec_options
# 上下文
context =
'categories': categories,
'breadcrumb': breadcrumb,
'sku': sku,
'specs': goods_specs,
template = loader.get_template('detail.html')
html_text = template.render(context)
file_path = os.path.join(os.path.dirname(settings.BASE_DIR), 'front_end_pc/goods/'+str(sku_id)+'.html')
with open(file_path, 'w') as f:
f.write(html_text)
if __name__ == '__main__':
skus = models.SKU.objects.all()
for sku in skus:
print(sku.id)
generate_static_sku_detail_html(sku.id)
2. 执行批量静态化详情页脚本文件
1.添加Python脚本文件可执行权限
$ chmod +x regenerate_detail_html.py
2.执行批量静态化详情页脚本文件
$ cd ~/meiduo_mall/scripts
$ ./generic_detail_html.py四、用户浏览记录
4.1 设计浏览记录存储方案
- 当登录用户在浏览商品的详情页时,我们就可以把详情页这件商品信息存储起来,作为该登录用户的浏览记录。
- 用户未登录,我们不记录其商品浏览记录。
1. 存储数据说明
- 虽然浏览记录界面上要展示商品的一些SKU信息,但是我们在存储时没有必要存很多SKU信息。
- 我们选择存储SKU信息的唯一编号(sku_id)来表示该件商品的浏览记录。
- 存储数据:
sku_id
2. 存储位置说明
- 用户浏览记录是临时数据,且经常变化,数据量不大,所以我们选择内存型数据库进行存储。
- 存储位置:
Redis数据库 3号库
CACHES =
"history": # 用户浏览记录
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/3",
"OPTIONS":
"CLIENT_CLASS": "django_redis.client.DefaultClient",
,
3. 存储类型说明
- 由于用户浏览记录跟用户浏览商品详情的顺序有关,所以我们选择使用Redis中的
list类型存储 sku_id- 每个用户维护一条浏览记录,且浏览记录都是独立存储的,不能共用。所以我们需要对用户的浏览记录进行唯一标识。
- 我们可以使用登录用户的ID来唯一标识该用户的浏览记录。
- 存储类型:
'history_user_id' : [sku_id_1, sku_id_2, ...]
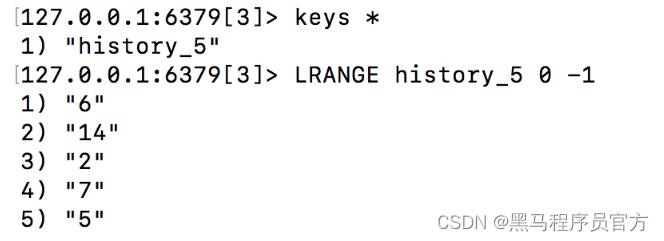
4. 存储逻辑说明
- SKU信息不能重复。
- 最近一次浏览的商品SKU信息排在最前面,以此类推。
- 每个用户的浏览记录最多存储五个商品SKU信息。
- 存储逻辑:先去重,再存储,最后截取。
4.2 保存和查询浏览记录
1. 保存用户浏览记录
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | POST |
| 请求地址 | /browse_histories/ |
2.请求参数:JSON
| 参数名 | 类型 | 是否必传 | 说明 |
|---|---|---|---|
| sku_id | string | 是 | 商品SKU编号 |
3.响应结果:JSON
| 字段 | 说明 |
|---|---|
| code | 状态码 |
| errmsg | 错误信息 |
4.后端接口定义和实现
from apps.goods.models import SKU
from django_redis import get_redis_connection
class UserBrowseHistory(View):
"""用户浏览记录"""
def post(self, request):
"""保存用户浏览记录"""
# 接收参数
json_dict = json.loads(request.body.decode())
sku_id = json_dict.get('sku_id')
# 校验参数
try:
SKU.objects.get(id=sku_id)
except SKU.DoesNotExist:
return JsonResponse('code': 400, 'errmsg': 'sku不存在')
# 保存用户浏览数据
redis_conn = get_redis_connection('history')
pl = redis_conn.pipeline()
user_id = request.user.id
# 先去重
pl.lrem('history_%s' % user_id, 0, sku_id)
# 再存储
pl.lpush('history_%s' % user_id, sku_id)
# 最后截取
pl.ltrim('history_%s' % user_id, 0, 4)
# 执行管道
pl.execute()
# 响应结果
return JsonResponse('code': 0, 'errmsg': 'OK')
2. 查询用户浏览记录
1.请求方式
| 选项 | 方案 |
|---|---|
| 请求方法 | GET |
| 请求地址 | /browse_histories/ |
2.请求参数:
无
3.响应结果:JSON
| 字段 | 说明 |
|---|---|
| code | 状态码 |
| errmsg | 错误信息 |
| skus[ ] | 商品SKU列表数据 |
| id | 商品SKU编号 |
| name | 商品SKU名称 |
| default_image_url | 商品SKU默认图片 |
| price | 商品SKU单价 |
"code":"0",
"errmsg":"OK",
"skus":[
"id":6,
"name":"Apple iPhone 8 Plus (A1864) 256GB 深空灰色 移动联通电信4G手机",
"default_image_url":"http://image.meiduo.site:8888/group1/M00/00/02/CtM3BVrRbI2ARekNAAFZsBqChgk3141998",
"price":"7988.00"
,
......
]
4.后端接口定义和实现
class UserBrowseHistory(View):
"""用户浏览记录"""
def get(self, request):
"""获取用户浏览记录"""
# 获取Redis存储的sku_id列表信息
redis_conn = get_redis_connection('history')
sku_ids = redis_conn.lrange('history_%s' % request.user.id, 0, -1)
# 根据sku_ids列表数据,查询出商品sku信息
skus = []
for sku_id in sku_ids:
sku = SKU.objects.get(id=sku_id)
skus.append(
'id': sku.id,
'name': sku.name,
'default_image_url': sku.default_image.url,
'price': sku.price
)
return JsonResponse('code': 0, 'errmsg': 'OK', 'skus': skus)

以上是关于美多商城项目之商品搜索商品详情页页面静态化用户浏览记录的主要内容,如果未能解决你的问题,请参考以下文章