用于视觉语言导航的自监督三维语义表示学习
Posted tzc_fly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用于视觉语言导航的自监督三维语义表示学习相关的知识,希望对你有一定的参考价值。

目录
前置内容
VLN:连接CV和robot agent的桥梁
VLN来源于CVPR2018的 “Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments”。提出了Room-to-Romm数据集(基于2017年的Matterport3D数据集),R2R使用了Matterport3D数据集中1万多张全景图(panoramic images),包括了90个building中的不同室内场景。
对于每一个building,都有一个导航图,即navigation graph:
agent可以从一个节点移动到下一个节点,在每个节点上都有一个全景图,agent收到外部指令(language),从起点移动到下一个节点,获得当前节点的全景图,然后再获取指令,一直走到终点(从当前节点移动到下一个节点可以给agent一个action实现)。
VLN任务可以形容为:给定自然语言指令,agent在视觉环境下找到目标位置。
VLN的评估指标包括:
- Trajectory Length轨迹长度TL:平均路径长度,单位为米;
- Navigation Error导航误差NE:agent最终位置到目标的平均距离,单位为米;
- Success Rate成功率SR:是距离目标位置不到3米的agent的最终定位的百分比;
- SP(success weighted by Path Length)将SR与TL进行权衡,得分越高,导航效率越高。
对于室内VLN,分为四个难度等级(Room-to-Room Navigation,Visible Object Localization,Hidden Object Localization,Ask-to-find),R2R属于最简单的一级。
- Room-to-Room Navigation:从一个离散节点到另一个离散节点;
- Visible Object Localization:从起点到终点,并能锁定视觉场景中的目标对象;
- Hidden Object Localization:从起点到终点,并能锁定视觉场景中的目标对象(但这个对象不可见,比如放在抽屉里);
- Ask-to-find:我们询问agent某个目标对象,agent可以自动导航并去找到它。
Embodied AI(具象AI)
与具象AI对立的词是Internet AI,指通过互联网上的数据进行学习,比如传统的CV,NLP任务,而Embodied AI是指agent从与环境的交互中学习。
NLP+CV+RL可能是通往AI未来的方向,具象AI也包含另一种方向:如何通过互联网上丰富的多模态数据,训练一个通用模型,可以根据指令在环境中执行各种任务。
具象AI有以下两个难点:
- 如何提升学习效率:正如LeCun说的,通过与环境交互学习有很大风险,效率也低,比如正向奖励太少,而通过observation,利用现有数据学习效率才更高,这样也可以延续pretraining-finetuning(以及pretraining-prompt)的范式,把更多的知识迁移到下游;
- 复杂的输入输出和环境:在最复杂的情况下,模型的输入是多模态指令,输出是可以在真实环境下执行的动作。同时,输出的动作空间大小、环境是模拟的还是真实的,都会带来不同的挑战;
关于Prompt,是与预训练搭配的新范式,NLP发展可以分为4个阶段:
- 全监督学习(非神经网络)。仅在目标任务的输入输出样本数据集上训练特定任务模型,其严重依赖特征工程。
- 全监督学习(神经网络)。使得特征学习与模型训练相结合,于是研究重点转向了架构工程,即通过设计一个网络架构(如CNN,RNN,Transformer)能够学习数据特征。
- Pre-train,Fine-tune。先在大数据集上预训练,再根据特定任务对模型进行微调,以适应于不同的下游任务。在这种范式下,研究重点转向了目标工程,设计在预训练和微调阶段使用的训练目标(损失函数)。
- Pre-train,Prompt,Predict。无需fine-tune,让预训练模型直接适应下游任务。更加方便,不需要不同任务使用不同的参数。
具体Prompt的做法是,将人为的指令给到预训练模型,使模型可以更好地理解人的指令,以便更好地利用预训练模型。例如,在情感分类任务中,输入为"I love this movie.",希望输出的是"positive/negative"中的一个标签。那么可以设置一个Prompt,形如:“The movie is ___”,然后让模型输出情感状态的答案(label),如positive/negative,甚至更细粒度一些的“fantastic”,“boring”等,将空补全作为输出。
摘要
在视觉语言导航任务中,embodied agent遵循语言指令并导航到指定目标位置。它在许多实际场景中都很重要,并引起了计算机视觉和机器人领域的广泛关注。然而,现有的大多数工作仅使用RGB图像,而忽略了场景的三维语义信息。为此,我们开发了一种新的自监督训练框架,将体素级(voxel-level)三维语义重建编码为三维语义表示。具体而言,region query任务被设计为pretext任务,预测特定3D区域中特定类别的对象的存在或不存在。然后,我们构建了一个基于LSTM的导航模型,并在vision-language pairs上使用所提出的3D语义表示和BERT语言特征对其进行训练。实验表明,该方法在R2R数据集的不可见验证集(validation unseen)和不可见测试集(test unseen)上分别达到68%和66%的success rates(SR),优于大多数使用vision-language Transformer的方法。
1.Introduction
在视觉语言导航(VLN)任务中,embodied agent的"视觉感知-语言理解-决策"组合为一个循环,使agent能够按照指令在环境中导航。在计算机视觉和机器人领域出现了许多相关工作。大多数现有工作使用全景RGB图像作为输入,并将其编码为各种特征。
尽管以 RGB 观测作为输入,VLN 基准测试的性能已经有显着提高,但RGB图像忽略了agent可以获得的深度信息。由于只有RGB信息,训练过程中不可避免地引入了许多语义无关的纹理细节,导致模型存在过拟合问题,并且训练的agent将不具备足够的三维环境感知能力。为了解决这个问题,有人提出了一种使用depth特征对RGB特征进行正则化的网络,但只观察到了轻微的性能改进。可能是因为"视觉-语言-动作"的联合学习实际上需要更多的高级3D语义信息来克服过拟合问题。一种可能的方法是将3D语义信息引入VLN任务,但这也是一种挑战。虽然三维语义重建可以从RGB-D数据中获得,但在VLN任务的上下文中,有限的注释数据使得三维语义特征的编码难以学习,更不用说三维语义编码器和导航模型的联合学习了。
为了解决上述挑战,我们开发了一种新的自监督三维语义表示学习框架,用于视觉语言导航任务。受DETR检测器的启发,设计了一个region query任务作为pretext任务,该任务期望模型回答指定类别对象是否出现在场景的指定3D区域中。基于此机制,模型可以学习将三维语义重建编码为有意义的表示,并用于导航任务。实验表明,与传统全景RGB特征相比,提出的三维语义表示提高了VLN性能。
我们的贡献总结如下:
- 我们分析了三维语义表示在视觉语言导航任务中的重要作用,并建立了一个新的学习和融合框架。
- 我们利用region query作为pretext任务设计了一种自监督学习方法,用于从无标记的三维语义重建中进行三维语义表示学习。
- 在R2R数据集上的实验结果表明,与之前的RGB-D方法相比,我们提出的方法的SR提高了10%以上。此外,对于基于LSTM的导航模型,我们提出的方法优于大多数基于RGB vision-language Transformer的方法。
2.Related Work
Methods for VLN
最近,针对VLN任务提出了许多方法,主要侧重于提高跨模态视觉语言关联和场景泛化能力。对于视觉语言推理,一些工作引入了跨模态注意力结构和其他任务,如导航进度和路径匹配度预测,以建立每个步骤的观测和指令之间的对应关系。对于场景泛化,指令和场景的数据增强方法在很多工作中进行了研究。
此外,随着预训练Transformer在视觉语言pair任务中的广泛使用,vision-language Transformer被引入到VLN任务中,以在每一步建立跨模态推理。然而,上述大多数方法仅使用基于RGB观测的特征,无法有效地将depth信息集成到导航任务中。
用于embodied navigation的depth和3D语义表示
3D语义信息为embodied agent在环境中导航提供了有价值的线索。它可以通过使用depth传感器获得,并且已经用于视觉语义导航任务(visual semantic navigation),其中图像或语义标签被表示为agent导航的目标,不要求模型具有强大的语言处理能力。另一方面,在视觉语言导航任务这种包含语言丰富信息的视觉导航任务中,很少使用具有depth信息的三维语义表示,部分原因是难以用端到端的方法训练具有三维语义输入的模型。曾经有人试图将depth特征应用到导航模型中,但只观察到了微小的改进,这意味着难以将3D信息纳入视觉语言导航任务。
自监督学习
自监督特征学习旨在从大量未标记数据中学习有效的特征表示,然后将其用于下游任务。它在计算机视觉任务中得到了广泛的研究。最近,有一些工作试图将自监督表示学习技术应用于具体任务。例如,提出了一种称为SEAL的自监督学习框架,该框架利用在互联网图像上训练的感知模型来学习主动探索策略。而在我们的工作中,我们在视觉语言导航任务中采用自监督学习实现三维语义表示。
3.Method
在本节中,我们将介绍由导航任务的RGB-D输入构建的3D语义表示的学习框架,如图1所示。首先,我们描述了输入的观测如何转换为3D语义表示。在第二和第三部分中,我们介绍了语言指令的编码方法,以及3D特征如何适应视觉语言导航任务。最后,我们讨论了融合特征的策略。
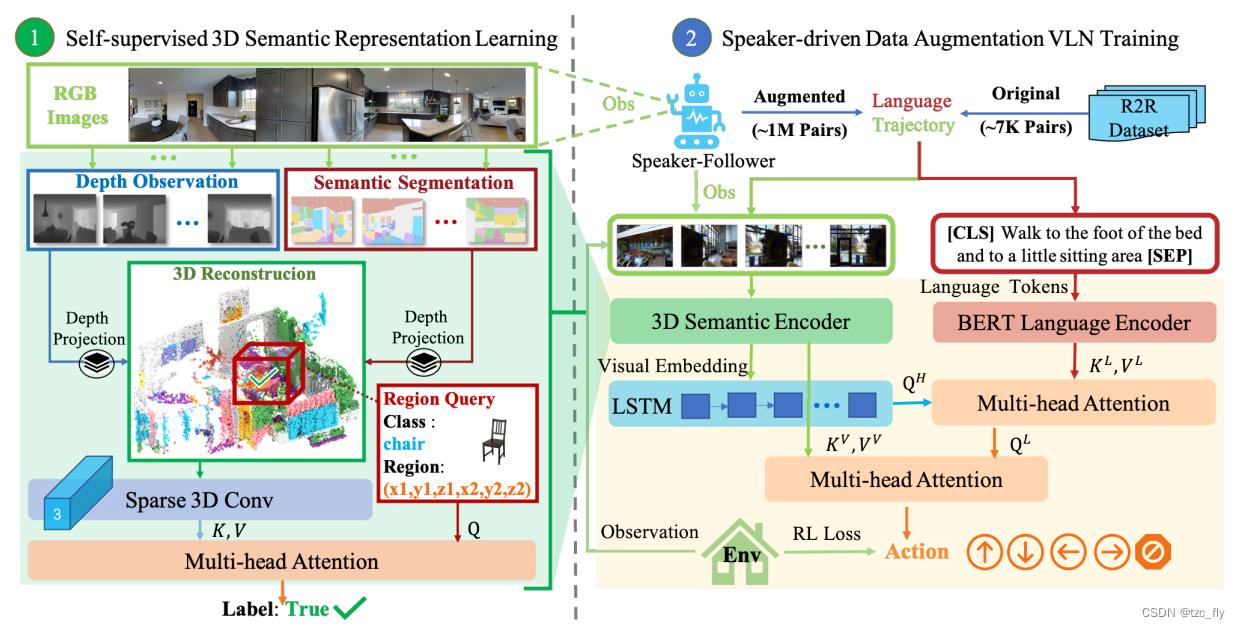
- 图1:我们提出的视觉语言导航方法。首先,为了通过自监督表示学习对局部3D语义信息进行编码,我们将RGB观测的segmentation与depth信息相结合,通过投影重建3D场景,我们以自监督方法训练3D Semantic Encoder,并执行regional object category是否存在的query任务。其次,我们使用前一步训练的3D Semantic Encoder生成3D语义表示,并通过预训练的BERT模型提取语言指令的特征。最后,我们使用基于LSTM的导航模型和注意力层,将语言特征和三维语义表示结合到VLN任务中。在该图中,Q,K和V表示多头交叉注意力网络的输入。
3.1.Self-Supervised Learning for 3D Semantic Representation
3D语义重建
为了从RGB-D观测重建3D环境,我们使用了在ADE20k上训练的150类SwinTransformer,但也可以使用其他分割模型(ADE20K是一个有2万张图片150种对象的场景语义分割数据集)。我们首先将指定位置agent的多个2D RGB观测输入到分割模型中,以获得2D语义分割,然后使用depth观测和相机参数将其投影到3D空间。然后,将RGB-D观测转换为3D语义点云。通过组合来自不同视点的三维点云,我们可以获得全景语义点云。请注意,使用的体素化参数在X轴和Y轴为0.125米,在Z轴为0.25米。对于agent,相对于agent中心的水平观测最大范围为±8m,垂直观测最大范围则为±4m。因此,基于体素的三维语义重建的维数为150×128×128×32,这导致导航训练占用大量内存。
为了解决这个问题,我们使用三维重建的稀疏表示(sparse representation),只记录至少一个非零语义类别的位置。这将产生一个形状为 k × 4 k×4 k×4的张量,记录了在一个mini-batch中的索引和位置,以及一个形状 k × 150 k×150 k×150的张量来记录语义类别,其中 k k k是非零语义类别的位置数。最后,使用稀疏卷积网络对三维重建的稀疏表示进行编码得到 4 × 4 × 2048 4×4×2048 4×4×2048张量,该张量表示为 F s e m F_sem Fsem。
自监督学习
虽然我们为三维语义表示设计了编码器,但由于VLN任务中的训练样本有限,如何确定大规模网络参数是一个挑战。
为了解决这个问题,我们开发了一种自监督方法来预训练稀疏卷积网络以对语义重建进行编码。为了使网络能够处理3D重建,我们设计了一个region query pretext task,其中需要3D视觉编码模型来回答特定区域中的对象是否存在问题。任务定义如下:
给定一个query(定义为一个元组 ( x 1 , y 1 , z 1 , x 2 , y 2 , z 2 , c ) (x_1,y_1,z_1,x_2,y_2,z_2,c) (x1,y1,z1,x2,y2,z2,c)),询问是否存在一个类别为 c c c的对象在区域 [ ( x 1 , x 2 ) , ( y 1 , y 2 ) , ( z 1 , z 2 ) ] [(x_1,x_2),(y_1,y_2),(z_1,z_2)] [(x1,x2),(y1,y2),(z1,z2)]内,模型应该回答True或者False。这是一个二分类问题,其训练样本和标签可以在相关场景中获得。
下面我们将介绍如何使用此pretext任务来训练网络。首先,使用MLP将查询编码为2048维向量
q
\\textbfq
q,其表示为:
q
=
M
L
P
(
[
(
x
1
,
x
2
,
y
1
,
y
2
,
z
1
,
z
2
)
;
W
c
c
]
)
\\textbfq=MLP([(x_1,x_2,y_1,y_2,z_1,z_2);W_c\\textbfc])
q=MLP([(x1,x2,y1,y2,z1,z2);Wcc])其中,
c
\\textbfc
c是类别
c
c
c的one-hot向量,
W
c
W_c
Wc是可学习参数。然后,我们使用基于多头注意力的模型的softmax输出来估计答案
a
n
s
∈
T
r
u
e
,
F
a
l
s
e
ans\\in\\left\\True,False\\right\\
ans∈True,False的概率:
p
r
o
b
(
a
n
s
)
=
s
o
f
t
m
a
x
(
W
h
h
+
W
q
q
)
prob(ans)=softmax(W_h\\textbfh+W_q\\textbfq)
prob(ans)=softmax(Whh+Wqq)其中,
h
\\textbfh
h是多头注意力的输出:
h
=
A
t
t
n
(
q
,
K
,
V
)
\\textbfh=Attn(\\textbfq,K,V)
h=Attn(q,K,V)其中
A
t
t
n
Attn
Attn表示标准的多头注意层,
K
K
K和
V
V
V均设置为3D语义特征
F
s
e
m
F_sem
Fsem。自监督训练任务的模型架构如图2所示。
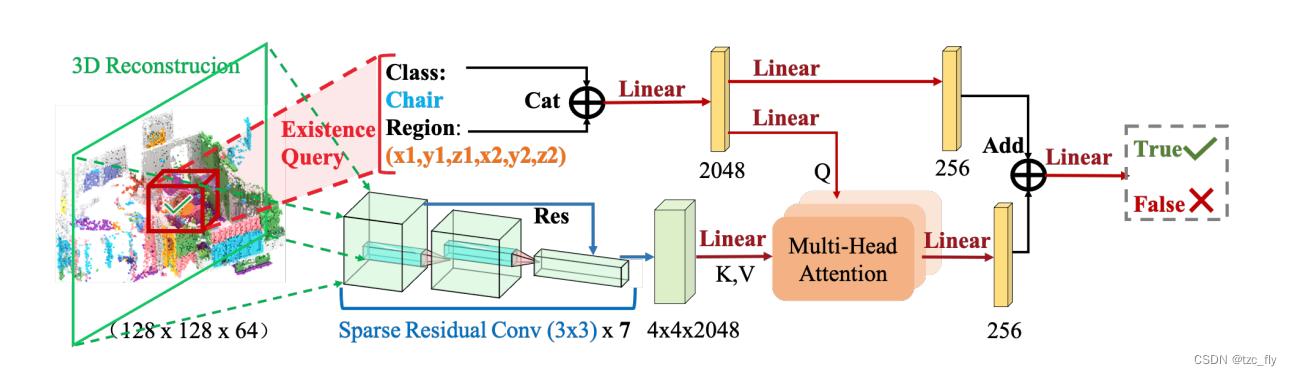
- 图2:用于自监督训练的模型结构。3D重建由稀疏卷积网络编码。将视觉embedding作为 K K K、 V V V,查询向量作为 Q Q Q分别馈送到多头注意网络中。如图中红色框所示,自监督训练任务要求模型识别指定区域中某个对象类别的存在。图2中的体素化参数Z轴为0.125米。
要使用此pretext任务进行训练,我们需要准备训练数据,这需要一组具有对象存在性注释的区域。由于语义重建中的随机采样区域可能包含比region query任务中的正样本多得多的负样本,我们使用一种简单的平衡技术来修改训练样本:对于一个mini-batch 3D语义重建,我们首先在一次重建中随机采样多个包含至少一种对象的区域。然后我们计算每个类的正样本数和负样本数,并将负样本数截断与正样本数相同。为了进一步提高在所提出的自监督方法中训练的模型的泛化能力,我们对点云应用随机噪声和仿射变换,包括缩放、平移和旋转,以生成更多不同的场景作为pretext任务的训练数据。我们期望所提出的3D视觉编码模型能够通过自监督query任务在不同的观察空间范围内感知语义信息。场景中空间位置与对象语义信息的关联有利于下游导航任务。
3.2.Language Encoder
在这项工作中,我们使用BERT作为语言编码器,生成两组导航指令向量: f L f_L fL作为语言特征, f L ∗ f_L^* fL∗作为句子级特征表示。这些语言表示将被导航模型进一步用于语言理解。
3.3.Navigation Model
导航模型是基于LSTM的模型设计。在初始time step,hidden state h 0 \\textbfh_0 h0,cell state c 0 \\textbfc_0 c0 和vision-language上下文表示 g 0 \\textbfg_0 g0被从句子级别表示 f L ∗ f_L^* fL∗进行初始化。在time step t t t,将当前3D语义特征和语言特征 f L f_L fL作为输入,使用之前的vision-language上下文 g t \\textbfg_t gt查询三维语义视觉特征,使用两层MLP网络 ψ ψ ψ获得: v t = ψ ( A t t n ( g t , K V , V V ) , g t ) \\textbfv_t=ψ(Attn(\\textbfg_t,K^V,V^V),\\textbfg_t) vt=ψ(Attn(g论文泛读171具有对抗性扰动的自监督对比学习,用于鲁棒的预训练语言模型
国科大人工智能学院《计算机视觉》课 —三维视觉—三维表达与语义建模
国科大人工智能学院《计算机视觉》课 —三维视觉—三维表达与语义建模