Spark基础学习笔记07:搭建Spark HA集群
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark基础学习笔记07:搭建Spark HA集群相关的知识,希望对你有一定的参考价值。
文章目录
- 零、本讲学习目标
- 一、Spark HA集群概述
- 二、Spark HA集群架构
- 三、集群角色分配表
- 四、Spark HA集群搭建步骤
- 五、启动Spark HA集群
- 六、测试Spark HA集群
零、本讲学习目标
- 了解Spark HA集群工作原理
- 掌握搭建Spark HA集群基本步骤
- 能够测试Spark HA集群的高可用性
一、Spark HA集群概述
- Spark Standalone和大部分Master/Slave模式一样,都存在Master单点故障问题,解决方式是基于ZooKeeper实现两个Master无缝切换,类似HDFS的NameNode HA(High Availability,高可用)或YARN的ResourceManager HA。
Spark可以在集群中启动多个Master,并使它们都向ZooKeeper注册,ZooKeeper利用自身的选举机制保证同一时间只有一个Master是活动状态(active)的,其他的都是备用状态(Standby)的。 - 当活动状态的Master出现故障时,ZooKeeper会从其他备用状态的Master选出一台成为活动Master,整个恢复过程大约在1分钟之内。对于恢复期间正在运行的应用程序,由于应用程序在运行前已经向Master申请了资源,运行时Driver负责与Executor进行通信,管理整个应用程序,因此Master的故障对应用程序的运行不会产生影响,但是会影响新应用程序的提交。
- 默认情况下,Standalone的Spark集群是Master-Slaves架构的集群模式,由一台master来调度资源,这就和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题。如何解决这个单点故障的问题呢?Spark提供了两种方案:基于文件系统的单点恢复(Single-Node Recovery with Local FileSystem)和基于ZooKeeper的Standby Masters(Standby Masters with ZooKeeper)。其中ZooKeeper是生产环境下的最佳选择。
- ZooKeeper提供了一个Leader Election机制,利用这个机制你可以在集群中开启多个master并使它们都注册到ZooKeeper实例,ZooKeeper会管理使其中只有一个是Active的,其他的都是Standby的,Active状态的master可以提供服务,standby状态的则不可以。ZooKeeper保存了集群的状态信息,该信息包括所有的Worker,Driver 和Application。当Active的Master出现故障时,ZooKeeper会从其他standby的master中选举出一台,然后该新选举出来的master会恢复挂掉了的master的状态信息,之后该Master就可以正常提供调度服务。整个恢复过程只需要1到2分钟。需要注意的是,在这1到2分钟内,只会影响新程序的提交,那些在master崩溃时已经运行在集群中的程序并不会受影响。为了开启这个恢复模式,你可以用下面的属性在
spark-env.sh中设置SPARK_DAEMON_JAVA_OPTS。
| System Property | Meaning |
|---|---|
| Dspark.deploy.recoveryMode | 设置zookeeper去启动备用master模式(默认为none) |
| Dspark.deploy.zookeeper.url | zookeeper集群url(如master:2181, slave1:2181, slave2:2181) |
| Dspark.deploy.zookeeper.dir | zookeeper保存恢复状态的目录(默认是/spark) |
二、Spark HA集群架构
- 以Spark Standalone模式的client提交方式为例,其HA的架构如下图所示。
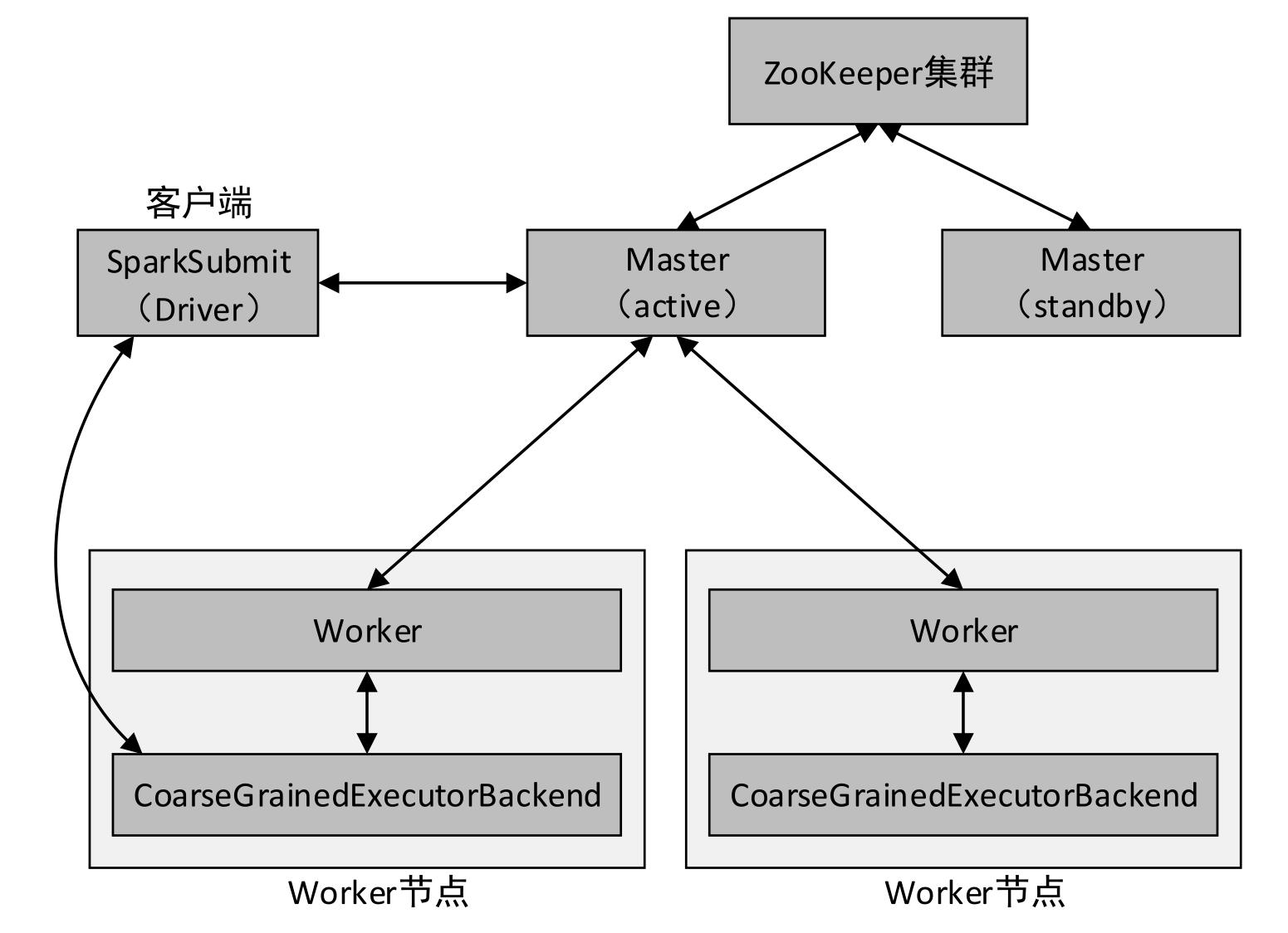
三、集群角色分配表
- 接着前面搭建好的Spark Standalone集群继续进行Spark HA的搭建,搭建前的角色分配如下表所示。
| 节点 | 角色 |
|---|---|
| master | MasterQuorumPeerMain |
| slave1 | MasterWorker QuorumPeerMain |
| slave2 | Worker QuorumPeerMain |
四、Spark HA集群搭建步骤
(一)安装配置ZooKeeper
- 如果要搭建高可用Hadoop集群或Spark集群,那么才需启动ZooKeeper集群
- ZooKeeper下载网址:
https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz

- 下载到hw_win7虚拟机上
1、在虚拟机master上安装配置ZooKeeper
- 将zookeeper安装包上传到/opt目录
- 执行命令
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local,将zookeeper安装解压到指定目录

- 将zookeeper解压目录更名为
zookeeper-3.7.0,执行命令:mv /usr/local/apache-zookeeper-3.7.0-bin /usr/local/zookeeper-3.7.0

- 进入zookeeper安装目录,创建
ZkData子目录

- 进入zookeeper配置目录conf,复制zoo_sample.cfg到zoo.cfg

- 执行命令:
vim zoo.cfg,修改zoo.cfg文件,配置数据目录和服务器选举id
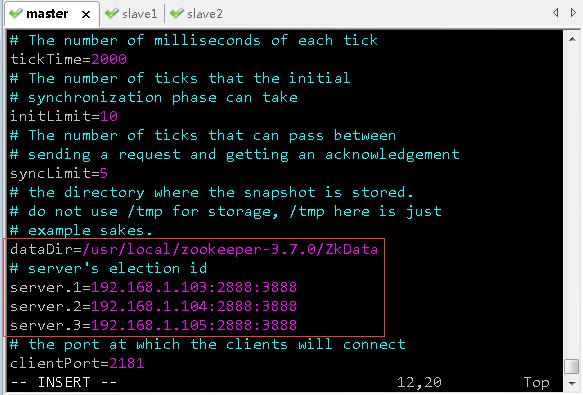
dataDir=/usr/local/zookeeper-3.7.0/ZkData
# server's election id
server.1=192.168.1.103:2888:3888
server.2=192.168.1.104:2888:3888
server.3=192.168.1.105:2888:3888
说明:server后面的数字是选举id,在选举过程中会用到
注意:数字一定要能比较出大小。
2888:原子广播端口号,可以自定义
3888:选举端口号,可以自定义
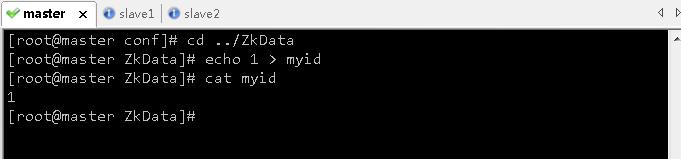
- 存盘退出,进入数据目录
ZkData,创建myid文件,内容为1
- 配置环境变量,执行命令
vim /etc/profile

JAVA_HOME=/usr/local/jdk1.8.0_231
ZK_HOME=/usr/local/zookeeper-3.7.0
HADOOP_HOME=/usr/local/hadoop-2.7.1
SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZK_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME
/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
export JAVA_HOME ZK_HOME HADOOP_HOME SPARK_HOME PATH CLASSPATH
- 存盘退出后,执行命令
source /etc/profile,让配置生效

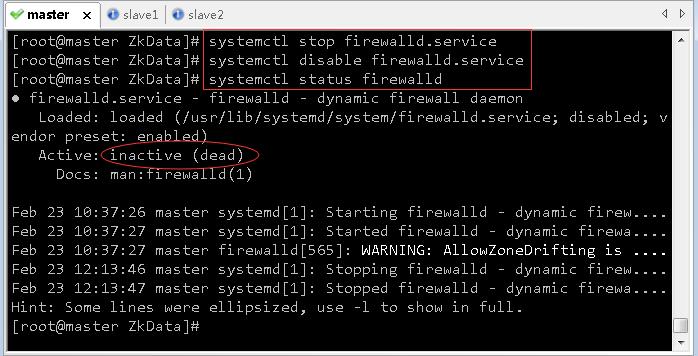
- 关闭防火墙
systemctl stop firewalld.service # 临时关闭防火墙
systemctl disable firewalld.service # 禁止开机启动防火墙
systemctl status firewalld # 查看防火墙状态
2、在虚拟机slave1上安装配置ZooKeeper
- 将虚拟机master上的zookeeper安装目录复制到虚拟机slave1相同目录,执行命令:
scp -r /usr/local/zookeeper-3.7.0 root@slave1:/usr/local

- 将虚拟机master上的/etc/profile复制到虚拟机slave1相同位置,执行命令:
scp /etc/profile root@slave1:/etc/profile

- 切换到虚拟机slave1,执行命令
source /etc/profile,让配置生效

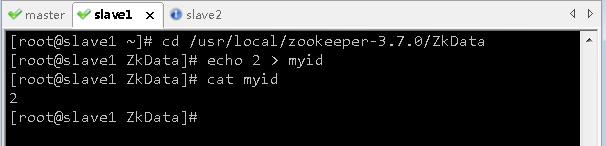
- 在虚拟机slave1上,进入
zookeeper-3.7.0/ZkData目录,修改myid的内容为2
3、在虚拟机slave2上安装配置ZooKeeper
-
将虚拟机master上的zookeeper安装目录复制到虚拟机slave2相同目录,执行命令:
scp -r /usr/local/zookeeper-3.7.0 root@slave2:/usr/local

-
将虚拟机master上的/etc/profile复制到虚拟机slave2相同位置,执行命令:
scp /etc/profile root@slave2:/etc/profile

-
切换到虚拟机slave2,执行命令
source /etc/profile,让配置生效

-
在虚拟机slave2上,进入
zookeeper-3.7.0/ZkData目录,修改myid的内容为3

(二)启动与关闭集群ZooKeeper服务
1、在虚拟机master上启动ZK服务
- 在master虚拟机上,执行命令:
zkServer.sh start

2、在虚拟机slave1上启动ZK服务
- 在slave1虚拟机上,执行命令:
zkServer.sh start

3、在虚拟机slave2上启动ZK服务
- 在slave2虚拟机上,执行命令:
zkServer.sh start

4、在三个虚拟机上查询ZK服务状态
- 在master虚拟机上,执行命令:
zkServer.sh status

- 在slave1虚拟机上,执行命令:
zkServer.sh status

- 在slave2虚拟机上,执行命令:
zkServer.sh status
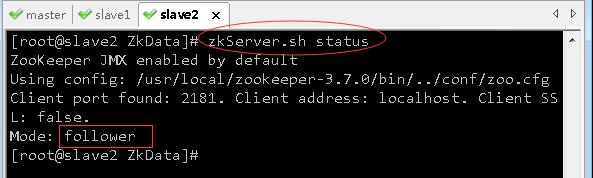
- 可以看到:虚拟机slave1是老大(leader),虚拟机master和虚拟机slave2是小弟(follower)。
5、测试集群三个节点是否同步
- 在虚拟机slave2上,执行命令:
zkCli.sh,启动zk客户端,创建一个节点/zk01

- 现在,去看集群另外两个节点master和slave1是否已经同步?


- 大家可以看到,集群三个节点的数据是同步的
- 在三个虚拟机上,执行
quit命令,退出zk客户端
6、关闭三台虚拟机上的ZK服务
- 关闭master虚拟机上的ZK服务
- 关闭slave1虚拟机上的ZK服务
- 关闭slave2虚拟机上的ZK服务
(三)在master节点上修改Spark环境配置文件 - spark-env.sh
- 进入Spark配置目录,执行命令:
vim spark-env.sh,记得删除其中的SPARK_MASTER_HOST属性配置

export JAVA_HOME=/usr/local/jdk1.8.0_231
export SPARK_MASTER_PORT=7077
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181
-Dspark.deploy.zookeeper.dir=/spark"
- 存盘退出后,执行
source spark-env.sh,让环境配置生效

(四)将master节点上的Spark环境配置文件分发到slave1和slave2
- 执行命令:
scp spark-env.sh root@slave1:$SPARK_HOME/conf
- 执行命令:
scp spark-env.sh root@slave2:$SPARK_HOME/conf

(五)在slave1和slave2上让Spark环境配置生效
- 在slave1上执行命令:
source $SPARK_HOME/conf/spark-env.sh

- 在slave2上执行命令:
source $SPARK_HOME/conf/spark-env.sh

五、启动Spark HA集群
(一)启动ZooKeeper集群
1、在master节点上启动ZK服务
- 执行命令:
zkServer.sh start

2、在slave1节点上启动ZK服务
- 执行命令:
zkServer.sh start

3、在slave2节点上启动ZK服务
- 执行命令:
zkServer.sh start
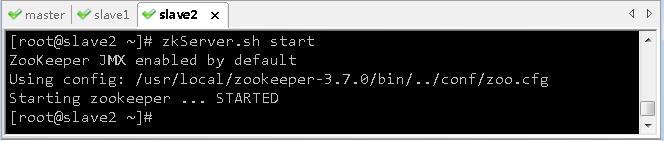
- 操作小技巧:如果需要在多个节点上执行同样的命令,可以打开SecureCRT的聊天窗口,将命令发布到多个会话对应的节点上,尤其当节点数较多时,这样操作显然可以提高效率。
(二)启动Spark集群
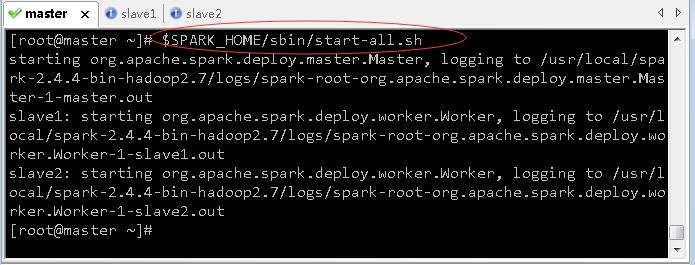
1、在master节点启动Spark集群
- 需要注意的是,在哪个节点上启动的Spark集群,活动状态的Master就存在于哪个节点上。
- 执行命令:
$SPARK_HOME/sbin/start-all.sh
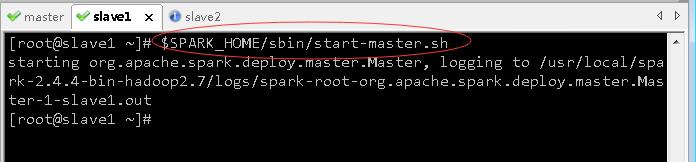
2、在slave1节点启动备用状态Master
- 执行命令:
$SPARK_HOME/sbin/start-master.sh
3、查看三个节点的进程
- 在master节点上执行
jps命令

- 在slave1节点上执行
jps命令

- 在slave2节点上执行
jps命令

六、测试Spark HA集群
(一)在Spark WebUI里查看两个Master状态
-
查看master节点上Master状态
-
访问
http://master:8080,但是访问不了

-
修改master节点上Spark环境配置文件,设置
SPARK_MASTER_WEBUI_PORT


-
存盘退出,执行
source spark-env.sh,让配置生效

-
将Spark环境配置文件分发到slave1和slave2

-
在slave1上执行
source spark-env.sh,让配置生效

-
在slave2上执行
source spark-env.sh,让配置生效

-
再次在master节点上启动Spark集群

-
在slave1节点上启动备用状态Master

-
访问
http://master:8088,查看master节点上Master状态 -alive(活动状态)

-
访问
http://slave1:8088,查看slave1节点上Master状态 -standby(备用状态)
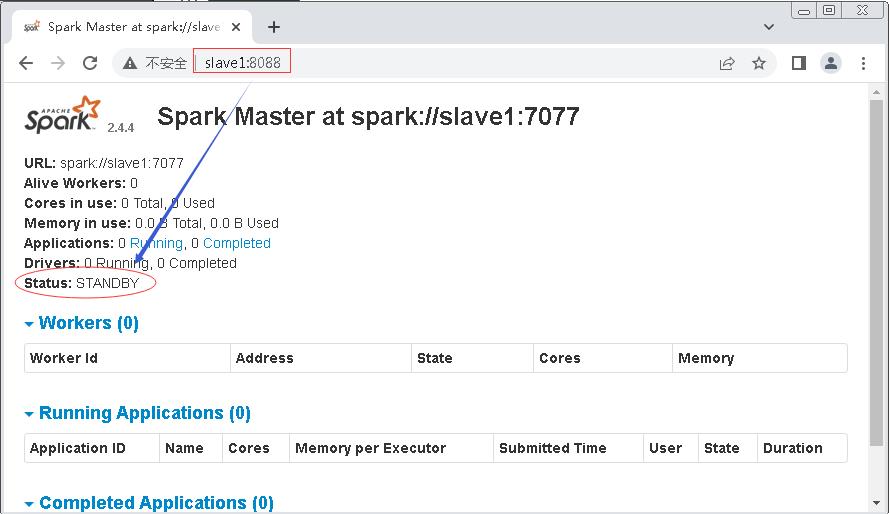
(二)测试Spark集群是否高可用
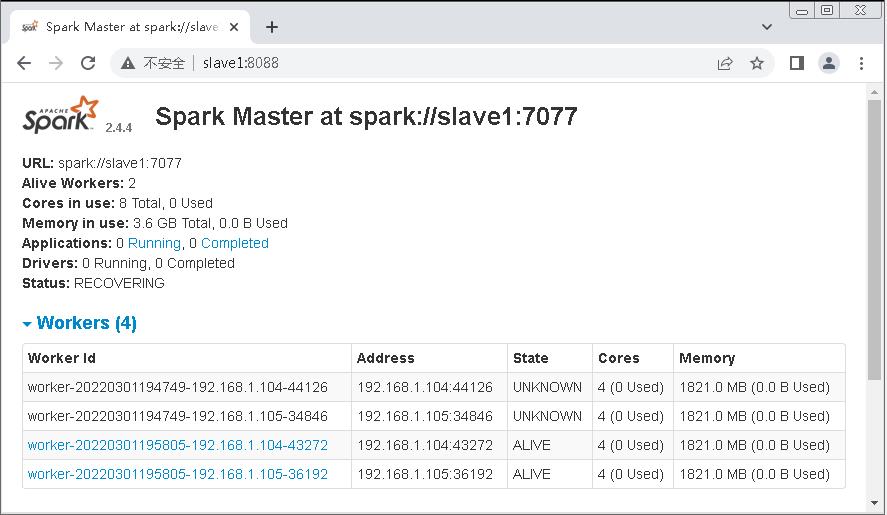
- 使用kill -9命令杀掉master节点的Master进程,稍等几秒后多次刷新slave1节点的WebUI,发现Master的状态由STANDBY首先变为了RECOVERING(恢复,该状态持续时间非常短暂),最后变为了ALIVE,如下所示。
- slave1节点Master处于
RECOVERING状态
- slave1节点Master处于
ALIVE状态
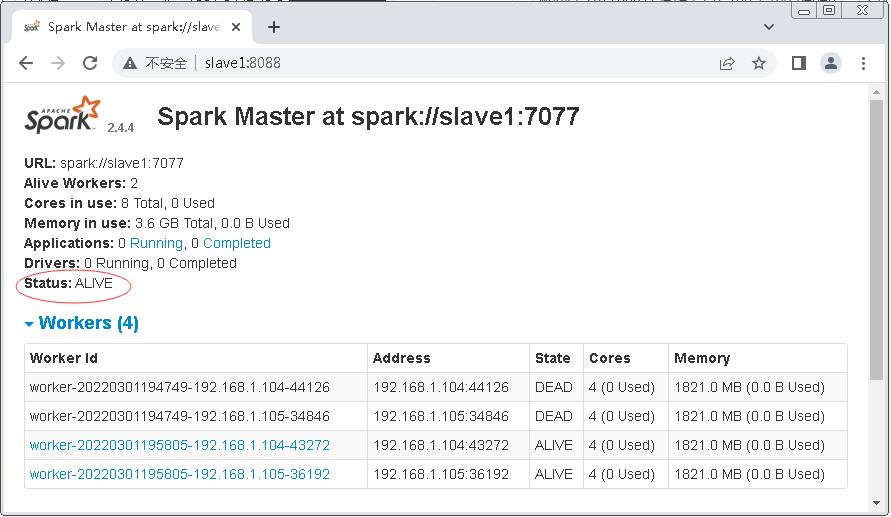
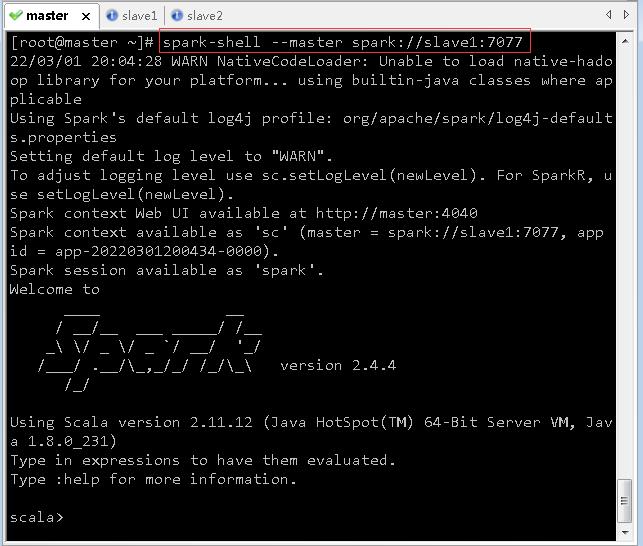
- 此时若需要连接Spark集群执行操作,则–master参数的连接地址需改为spark://slave1:7077
以上是关于Spark基础学习笔记07:搭建Spark HA集群的主要内容,如果未能解决你的问题,请参考以下文章
Spark基础学习笔记06:搭建Spark On YARN模式的集群