Spark基础学习笔记02:搭建Spark环境
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark基础学习笔记02:搭建Spark环境相关的知识,希望对你有一定的参考价值。
文章目录
- 零、本讲学习目标
- 一、搭建Spark单机版环境
- 二、搭建Spark伪分布式环境
- 三、搭建Spark完全分布式环境
- (一)Spark集群拓扑
- (二) 搭建服务器集群
- (二)配置分布式Hadoop
零、本讲学习目标
- 学会搭建Spark单机版环境
- 学会搭建Spark伪分布式环境
- 掌握搭建Spark完全分布式环境
一、搭建Spark单机版环境
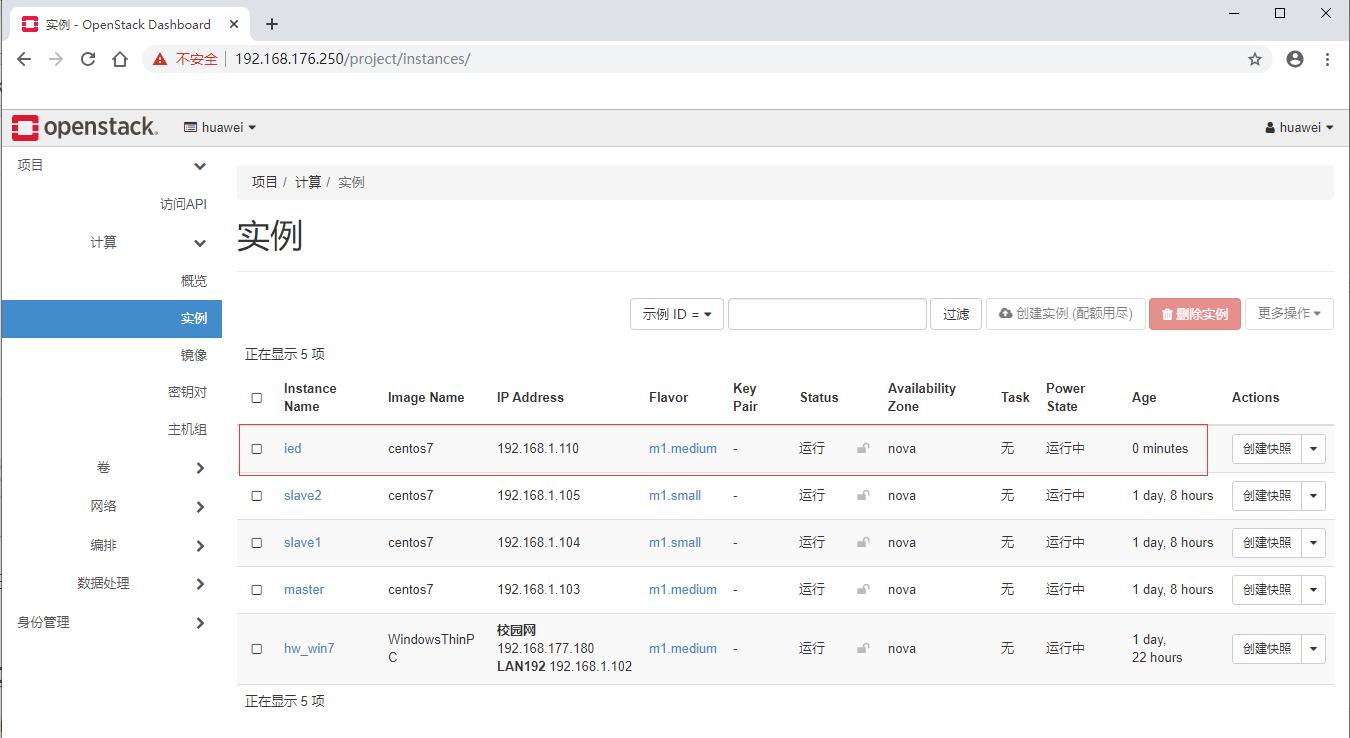
(一)在私有云上创建ied实例
- 给子网LAN192创建端口 - hw_port5
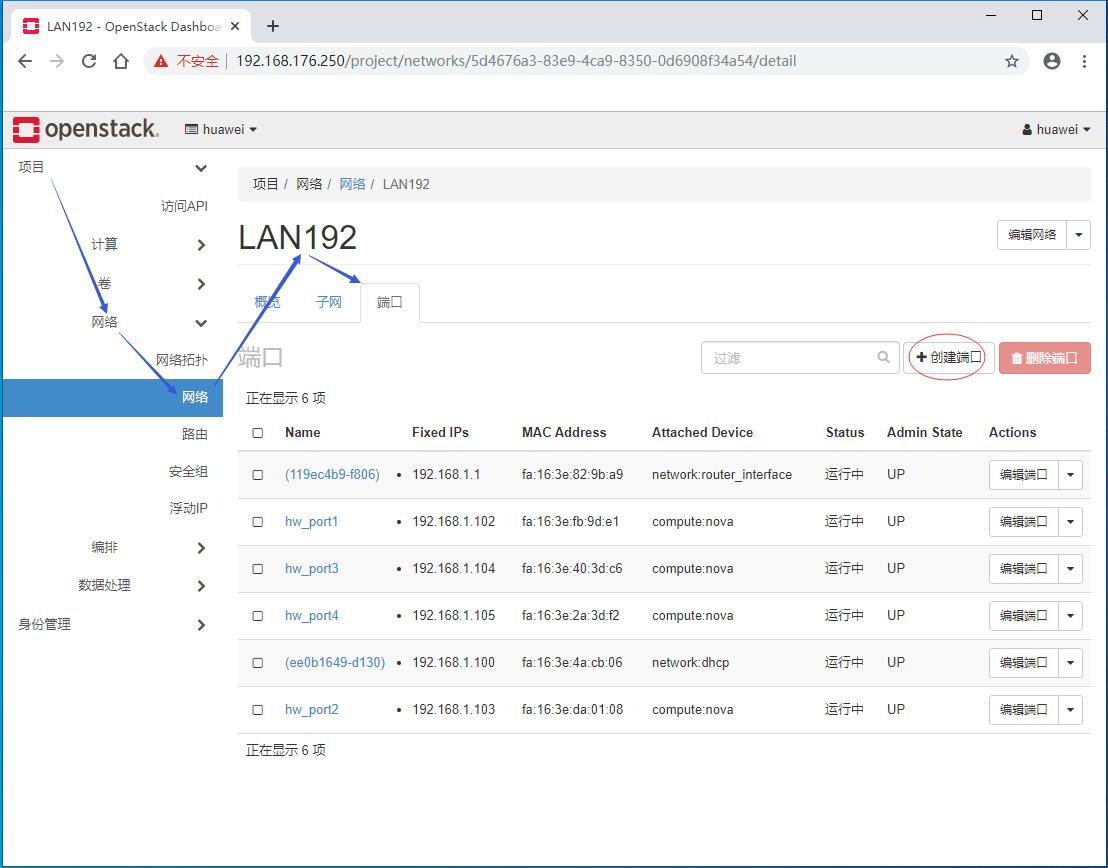
- 单击【创建端口】按钮
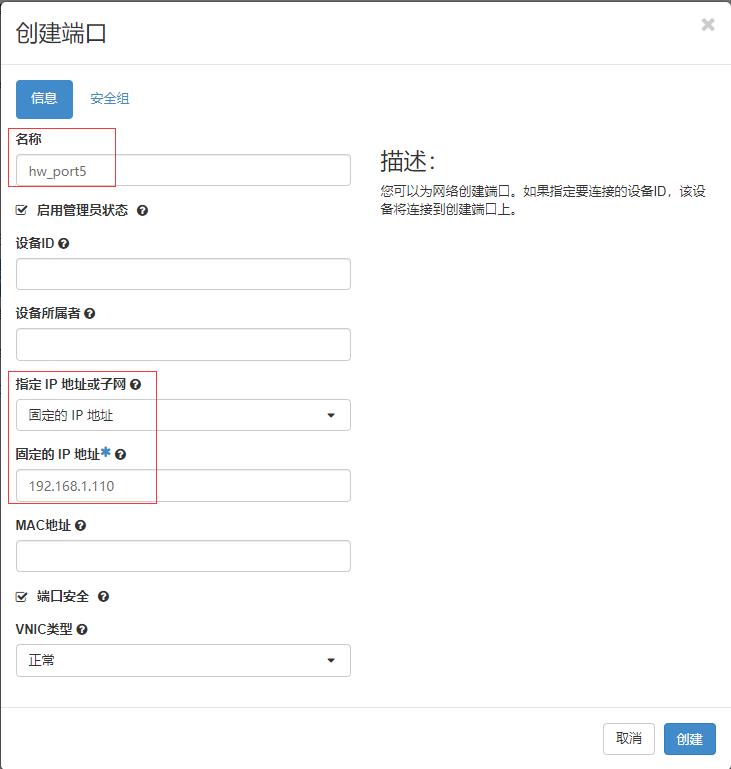
- 单击【创建】按钮

- 项目 - 计算 - 实例
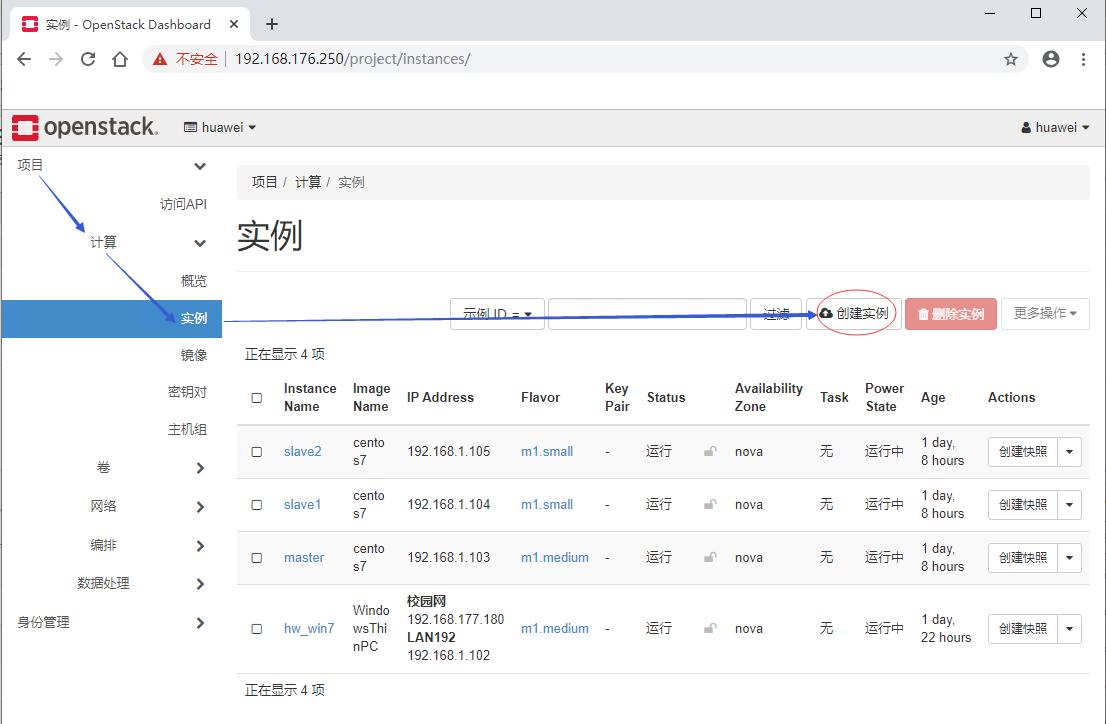
- 单击【创建实例】按钮
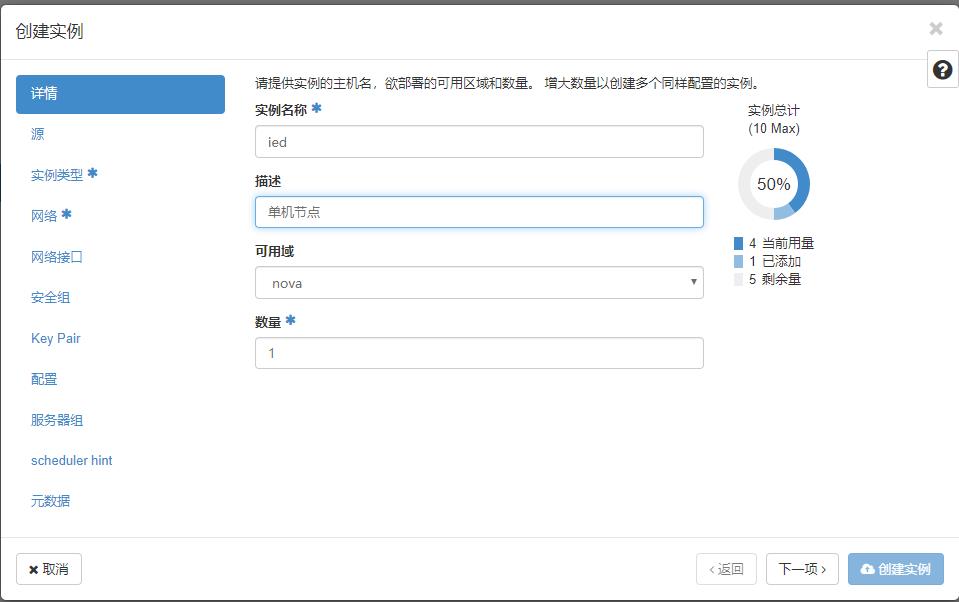
- 单击【下一项】按钮
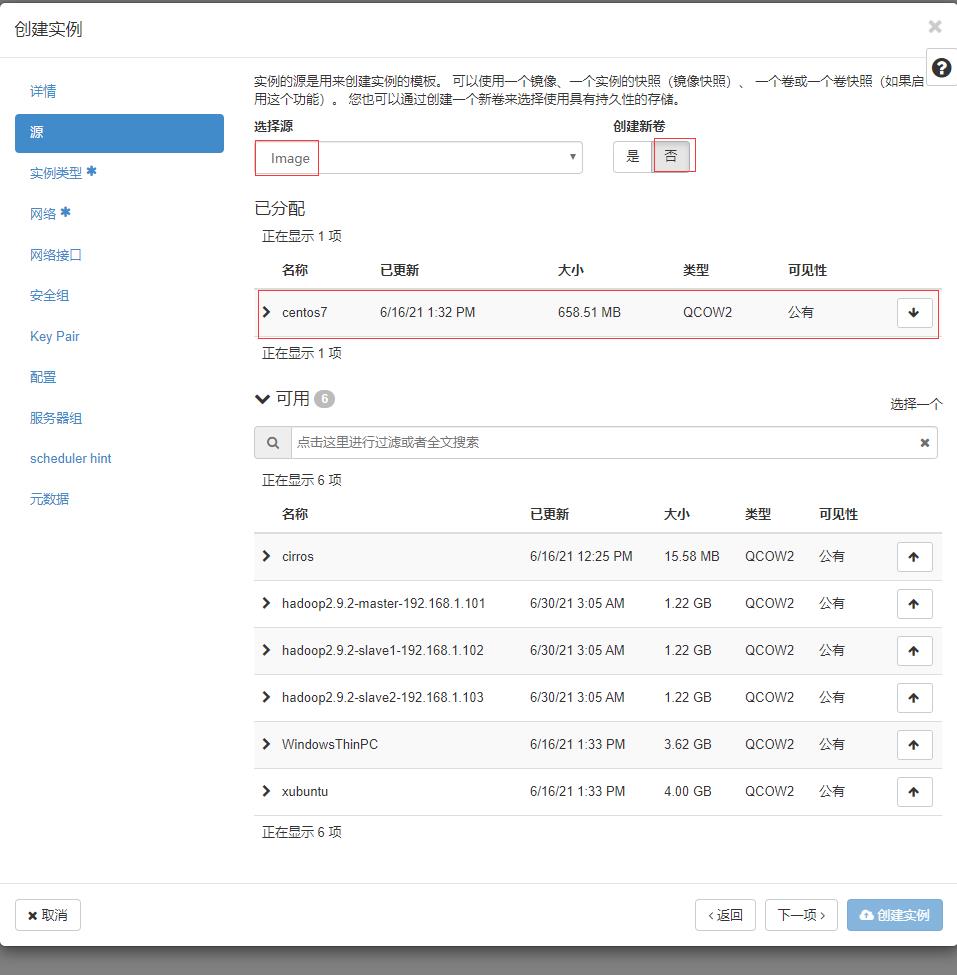
- 单击【下一项】按钮
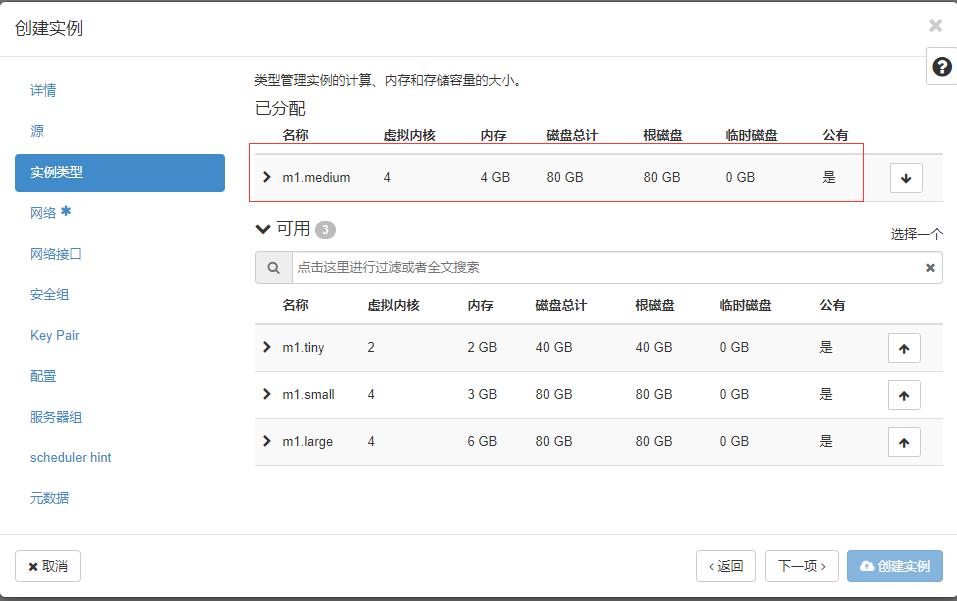
- 单击【下一项】按钮
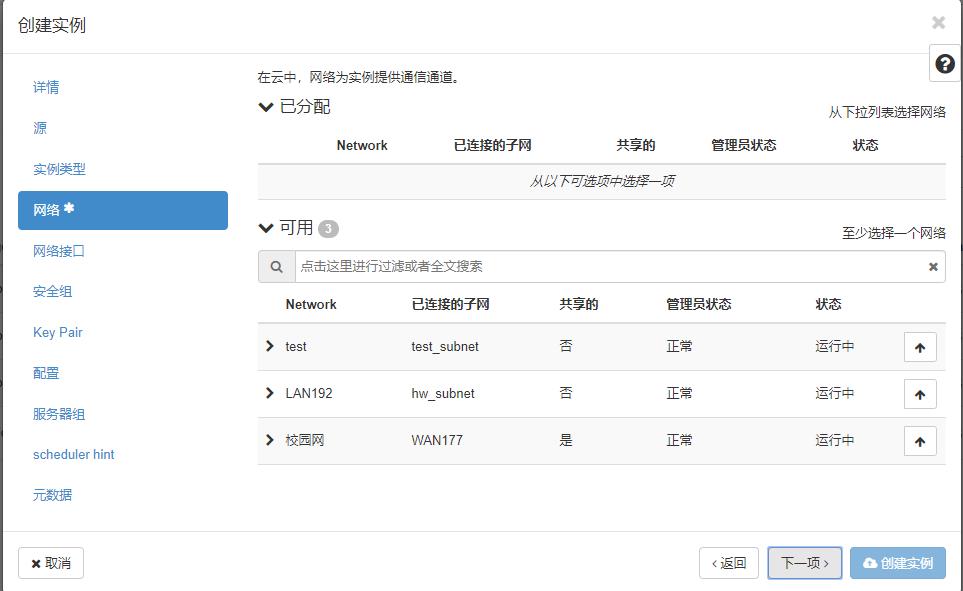
- 单击【下一项】按钮
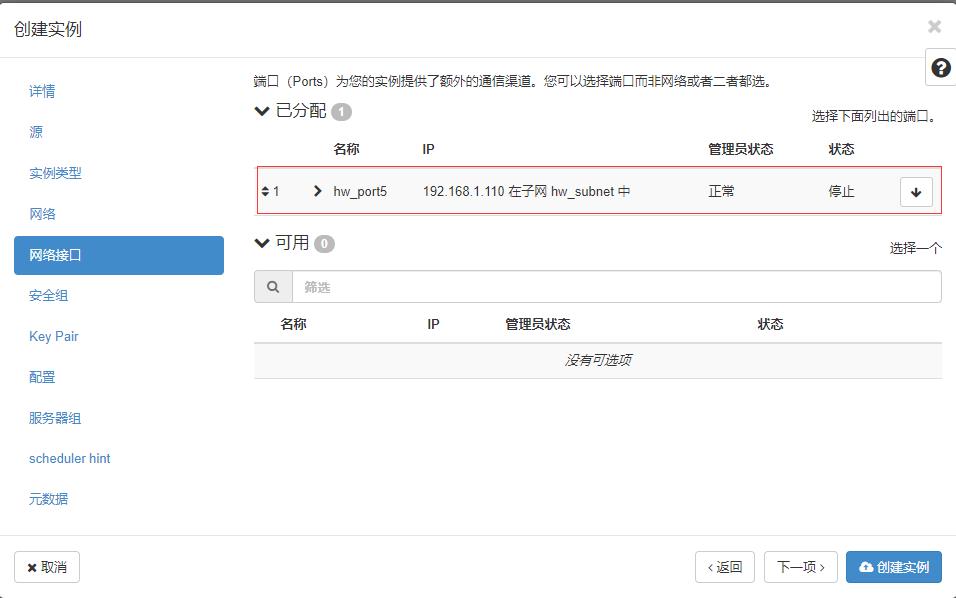
- 单击【创建实例】按钮
(二)修改ied实例的主机名
- 登录ied实例
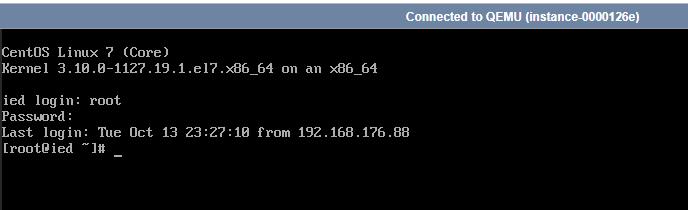
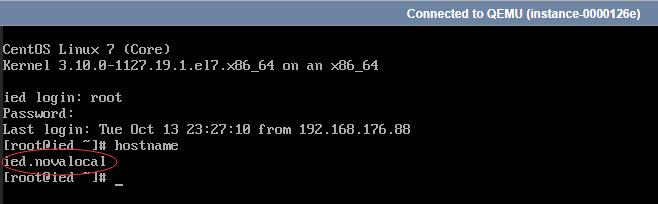
- 查看主机名
- 修改主机名
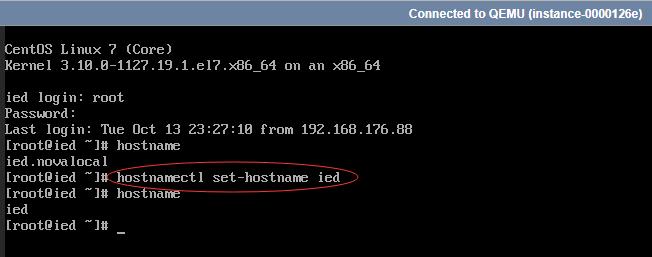
- 执行
reboot命令,重启ied虚拟机
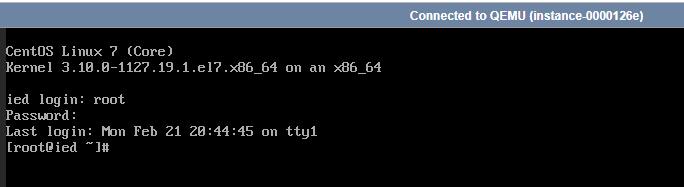
(三)设置IP地址与主机名的映射
- 执行命令:
vi /etc/hosts

- 存盘退出,这样
ping ied就相当于ping 192.168.1.110
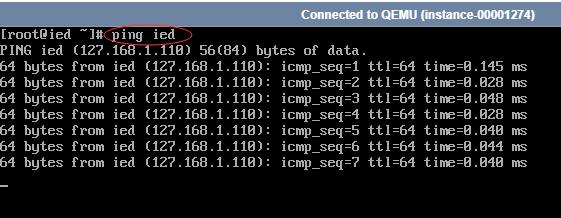
(四)通过SecureCRT访问ied虚拟机
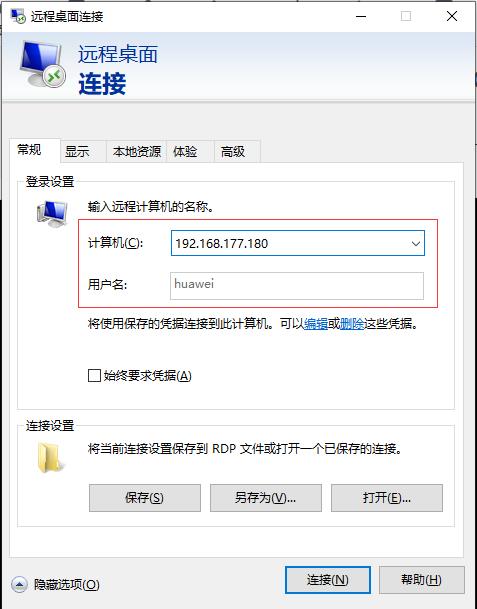
- 本机远程桌面连接hw_win7虚拟机
- 启动hw_win7虚拟机上的SecureCRT

- 新建一个连接,访问ied虚拟机
- 单击【Connect】按钮
- 单击【Accept & Save】按钮
- 单击【OK】按钮
- 关闭连接,修改连接名为ied
- 单击【Connect】按钮
- 设置选项
- 单击【OK】按钮
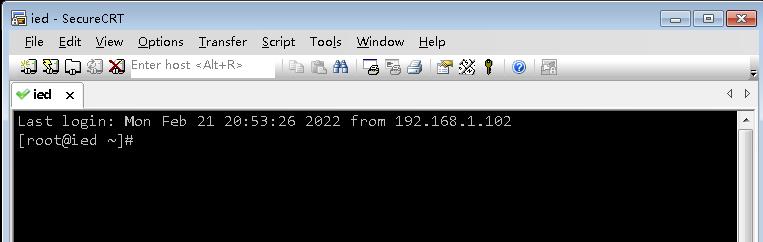
- 查看一下是否安装了Java
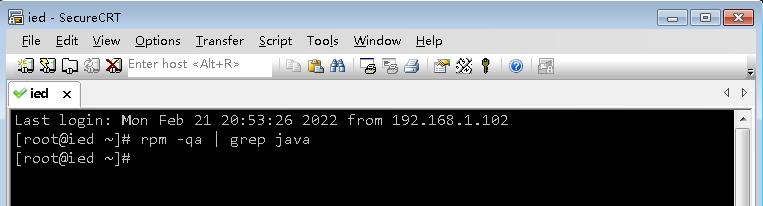
- 说明ied虚拟机上没有安装Java
(五)下载、安装和配置JDK
- 下载链接:https://pan.baidu.com/s/1RcqHInNZjcV-TnxAMEtjzA 提取码:jivr
- 将Java安装包上传到虚拟机/opt目录,但是rz命令不能用
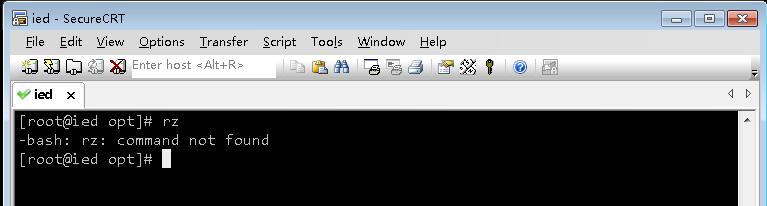
- rz命令无法使用,需要安装lrzsz。lrzsz是一个unix通信套件提供的X,Y,和ZModem文件传输协议。Windows 需要向CentOS服务器上传文件,可直接在CentOS上执行命令
yum -y install lrzsz,程序会自动安装好。要下载,则sz[找到你要下载的文件];要上传,则rz浏览找到你本机要上传的文件。

- 利用rz命令上传Java安装包到/opt目录
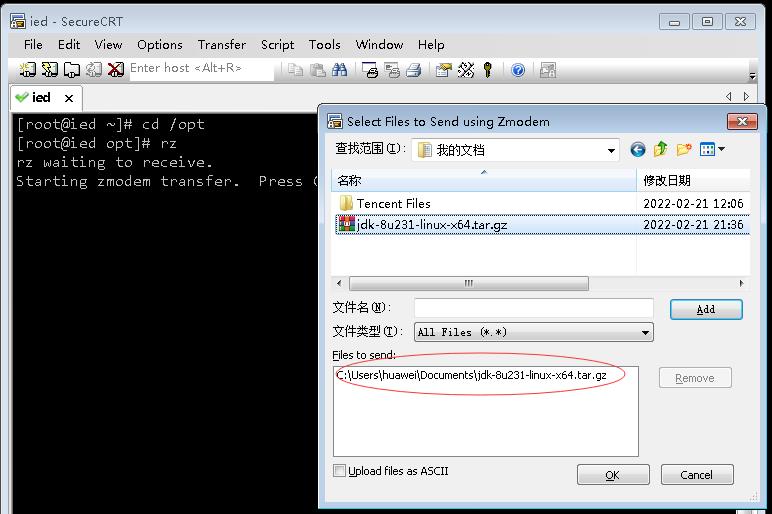
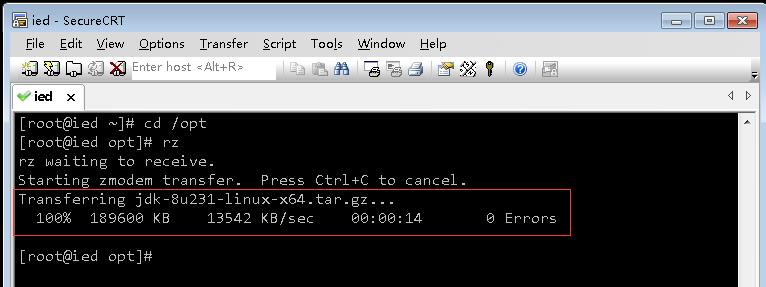
- 将Java安装包解压到/usr/local
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local

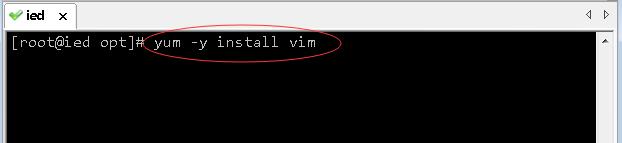
- 执行
yum -y install vim,安装vim编辑器
- 配置Java环境变量
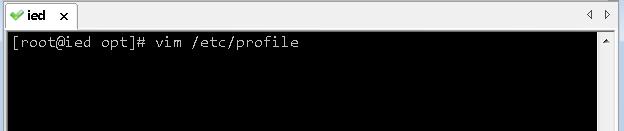
JAVA_HOME=/usr/local/jdk1.8.0_231
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH CLASSPATH
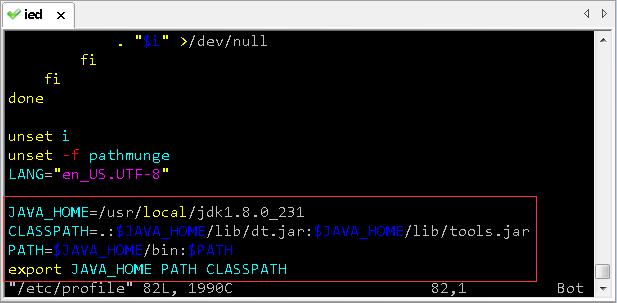
-
存盘退出,让环境配置生效

-
在任意目录下都可以查看JDK版本

(六)下载Spark安装包到Windows本地
- 下载链接:https://pan.baidu.com/s/1dLKt5UJgpqehRNNDcoY2DQ 提取码:zh0x

(七)将Spark安装包上传到Linux的/opt目录下
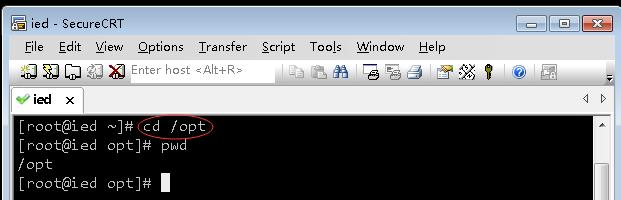
-
执行
cd /opt,进入/opt目录
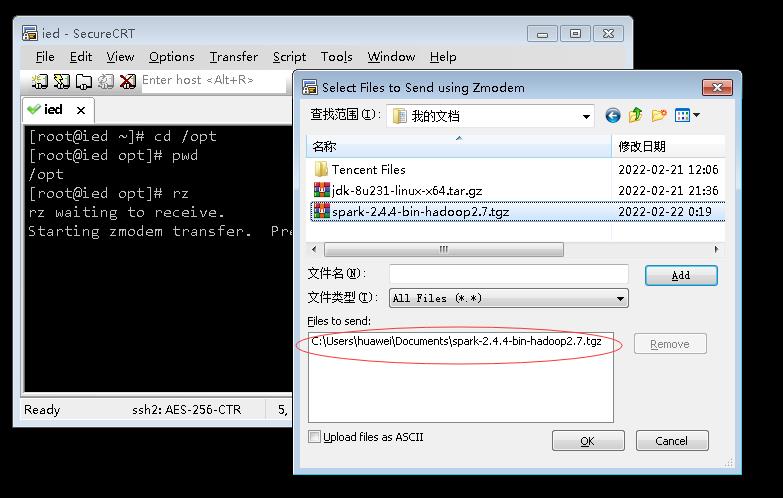
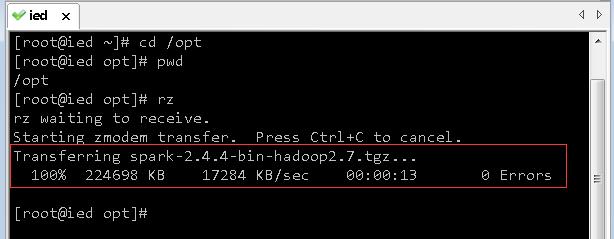
-
利用rz命令上传Spark安装包
(八)将Spark安装包解压到/usr/local目录下
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz -C /usr/local

- 查看解压之后的spark目录

(九)配置Spark环境变量
- 执行
vim /etc/profile

JAVA_HOME=/usr/local/jdk1.8.0_231
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7
PATH=$JAVA_HOME/bin:$SPARK_HOME/bin:$PATH
export JAVA_HOME SPARK_HOME PATH CLASSPATH
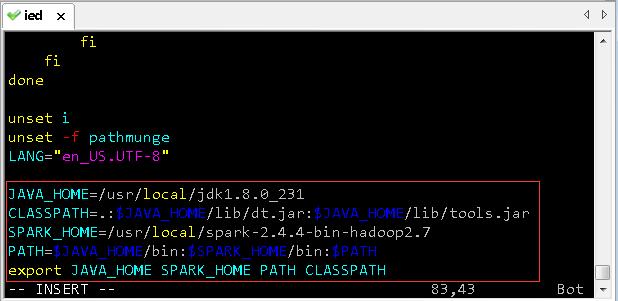
- 存盘退出,让环境配置生效

(十)使用SparkPi来计算Pi的值
run-example SparkPi 2 # 其中参数2是指两个并行度
[root@ied opt]# run-example SparkPi 2
22/02/20 04:24:32 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/02/20 04:24:34 INFO SparkContext: Running Spark version 2.4.4
22/02/20 04:24:34 INFO SparkContext: Submitted application: Spark Pi
22/02/20 04:24:34 INFO SecurityManager: Changing view acls to: root
22/02/20 04:24:34 INFO SecurityManager: Changing modify acls to: root
22/02/20 04:24:34 INFO SecurityManager: Changing view acls groups to:
22/02/20 04:24:34 INFO SecurityManager: Changing modify acls groups to:
22/02/20 04:24:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/02/20 04:24:35 INFO Utils: Successfully started service 'sparkDriver' on port 41942.
22/02/20 04:24:35 INFO SparkEnv: Registering MapOutputTracker
22/02/20 04:24:36 INFO SparkEnv: Registering BlockManagerMaster
22/02/20 04:24:36 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
22/02/20 04:24:36 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
22/02/20 04:24:36 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-8de32b0e-530a-47ba-ad2d-efcfaa2af498
22/02/20 04:24:36 INFO MemoryStore: MemoryStore started with capacity 413.9 MB
22/02/20 04:24:36 INFO SparkEnv: Registering OutputCommitCoordinator
22/02/20 04:24:36 INFO Utils: Successfully started service 'SparkUI' on port 4040.
22/02/20 04:24:36 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://ied:4040
22/02/20 04:24:36 INFO SparkContext: Added JAR file:///usr/local/spark-2.4.4-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.4.jar at spark://ied:41942/jars/spark-examples_2.11-2.4.4.jar with timestamp 1645302276946
22/02/20 04:24:36 INFO SparkContext: Added JAR file:///usr/local/spark-2.4.4-bin-hadoop2.7/examples/jars/scopt_2.11-3.7.0.jar at spark://ied:41942/jars/scopt_2.11-3.7.0.jar with timestamp 1645302276946
22/02/20 04:24:37 INFO Executor: Starting executor ID driver on host localhost
22/02/20 04:24:37 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 33814.
22/02/20 04:24:37 INFO NettyBlockTransferService: Server created on ied:33814
22/02/20 04:24:37 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
22/02/20 04:24:37 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManagerMasterEndpoint: Registering block manager ied:33814 with 413.9 MB RAM, BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:39 INFO SparkContext: Starting job: reduce at SparkPi.scala:38
22/02/20 04:24:39 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
22/02/20 04:24:39 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
22/02/20 04:24:39 INFO DAGScheduler: Parents of final stage: List()
22/02/20 04:24:39 INFO DAGScheduler: Missing parents: List()
22/02/20 04:24:39 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
22/02/20 04:24:40 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1936.0 B, free 413.9 MB)
22/02/20 04:24:40 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1256.0 B, free 413.9 MB)
22/02/20 04:24:40 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on ied:33814 (size: 1256.0 B, free: 413.9 MB)
22/02/20 04:24:40 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1161
22/02/20 04:24:40 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
22/02/20 04:24:40 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
22/02/20 04:24:40 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7866 bytes)
22/02/20 04:24:40 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
22/02/20 04:24:40 INFO Executor: Fetching spark://ied:41942/jars/scopt_2.11-3.7.0.jar with timestamp 1645302276946
22/02/20 04:24:41 INFO TransportClientFactory: Successfully created connection to ied/192.168.225.100:41942 after 185 ms (0 ms spent in bootstraps)
22/02/20 04:24:41 INFO Utils: Fetching spark://ied:41942/jars/scopt_2.11-3.7.0.jar to /tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/fetchFileTemp2787747616090799670.tmp
22/02/20 04:24:42 INFO Executor: Adding file:/tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/scopt_2.11-3.7.0以上是关于Spark基础学习笔记02:搭建Spark环境的主要内容,如果未能解决你的问题,请参考以下文章