Spark学习笔记--环境搭建
Posted 幼儿园园草
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark学习笔记--环境搭建相关的知识,希望对你有一定的参考价值。
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器),甚至还可以在学习阶段使用Windows模式。
spark下载地址:http://spark.apache.org/downloads.html
1 Local模式
Spark的Local模式就是单机模式,没有进行任务的集群环境配置。仅仅将软件包进行解压就可以使用了,通常用于学习阶段。
解压 -> 切换目录 -> 重命名
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-local
进入到spark-local目录,并打开local模式
cd spark-local/
bin/spark-shel
执行成功会出现spark的Logo标志
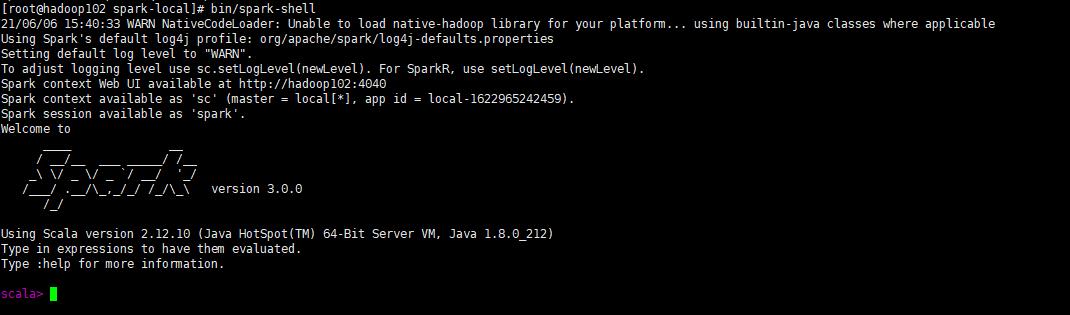
在/opt/module/spark-local/data目录下创建一个data.txt文件,里面随便写几行单词,每个单词用空格分开。在命令行中执行如下命令:
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

能够正确输出结果,表示单机模式可以正常使用。
这种模式很少使用,一般就是作为hello world使用的
2 Standalone模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。
2.1 上传软件
解压 -> 切换目录 -> 重命名
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
2.2 修改配置文件
复制配置文件slaves.template,并添加work节点,以你的集群环境的hostname为准
cp slaves.template slaves
hadoop102
hadoop103
hadoop104
复制配置文件 spark-env.sh.template,并添加JDK信息和设置master节点的位置
mv spark-env.sh.template spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
把spark-standalone整个文件夹分发到集群其他节点
xsync spark-standalone
2.3 启动集群
当看到主节点有Master和Worker两个进程,并且从节点有Worker进程表示启动成功
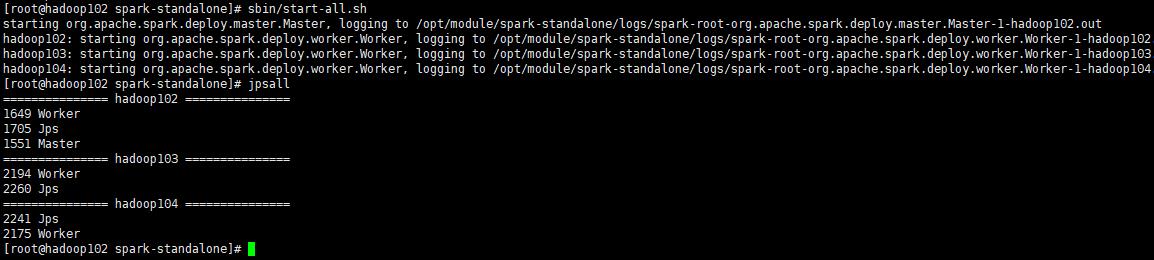
3 Yarn模式
3.1 上传软件
解压 -> 切换目录 -> 重命名
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn
2.2 修改配置文件
修改 hadoop 配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
2.3 启动集群
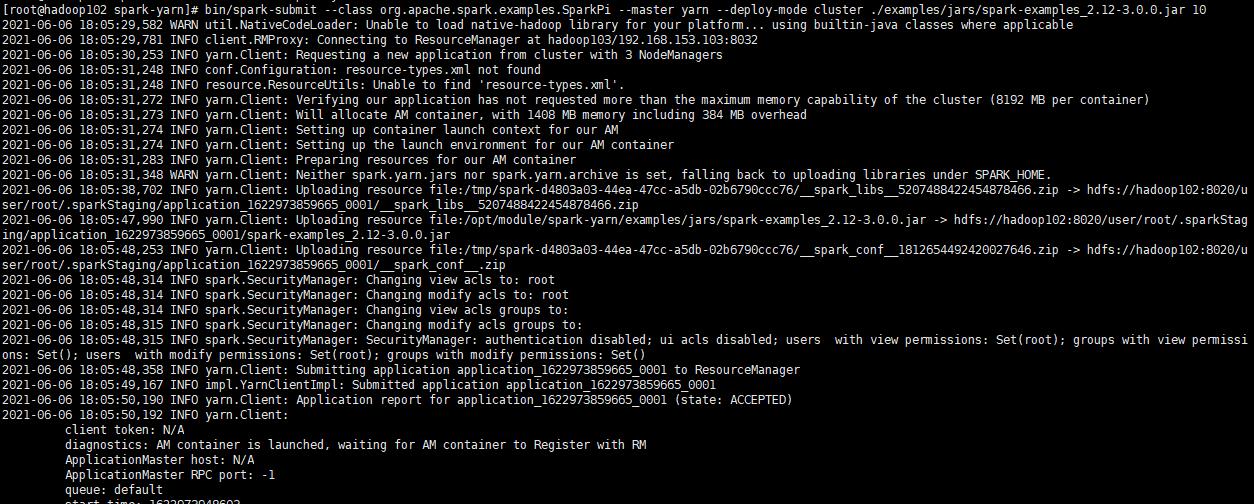
首先需要启动HDFS和YARN集群,然后在spark-yarn目录下执行命令
bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
./examples/jars/spark-examples_2.12-3.0.0.jar \\
10
可以正确输出以下内容表示环境搭建正确
打开hadoop的资源管理器可以看到任务的输出结果
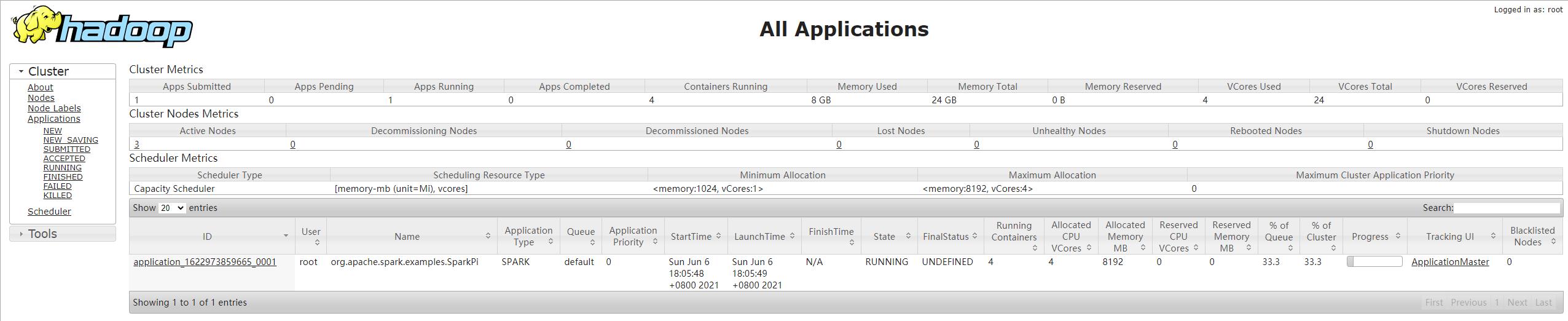
4 对比
Standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。当采用 Standalone 模式时,在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(Slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。
Spark on YARN模式
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,其架构如图3-15所示,资源管理和调度依赖YARN,分布式存储则依赖HDFS。
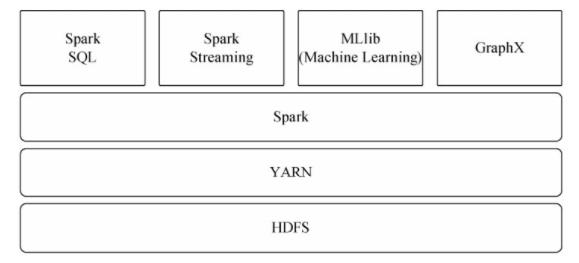
三种模式最常用的就是Yarn模式,依托于Hadoop的Yarn做任务调度,可以完美地兼容其它框架。此模式下不要在每台服务器安装spark,仅需要在其中一台服务器安装spark,在执行任务时,Yarn集群会将任务分发到所有集群的服务器上。

以上是关于Spark学习笔记--环境搭建的主要内容,如果未能解决你的问题,请参考以下文章