论文总结Damage-Map Estimation Using UAV Images and Deep Learning Algorithms for DMS
Posted 御己昊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文总结Damage-Map Estimation Using UAV Images and Deep Learning Algorithms for DMS相关的知识,希望对你有一定的参考价值。
文章目录
前言
最近精读了一篇关于使用语义分割的方法对灾害管理系统中无人机采集图像的受灾损伤区域进行估计的论文,对此做个总结
一、论文简介
论文主要介绍了一种语义分割的方法,用于对无人机拍摄的火灾后的现场图片进行处理,估计森林火灾后的受损区域;文章使用了2020年韩国一场火灾后搜集的图片作为数据集,使用two-patch-level的分割方法,patch-level 1 采用UNet++并使用FL损失,patch-level 2采用UNet并使用BCE损失,最高可以达到0.7639的dicecoefficients。
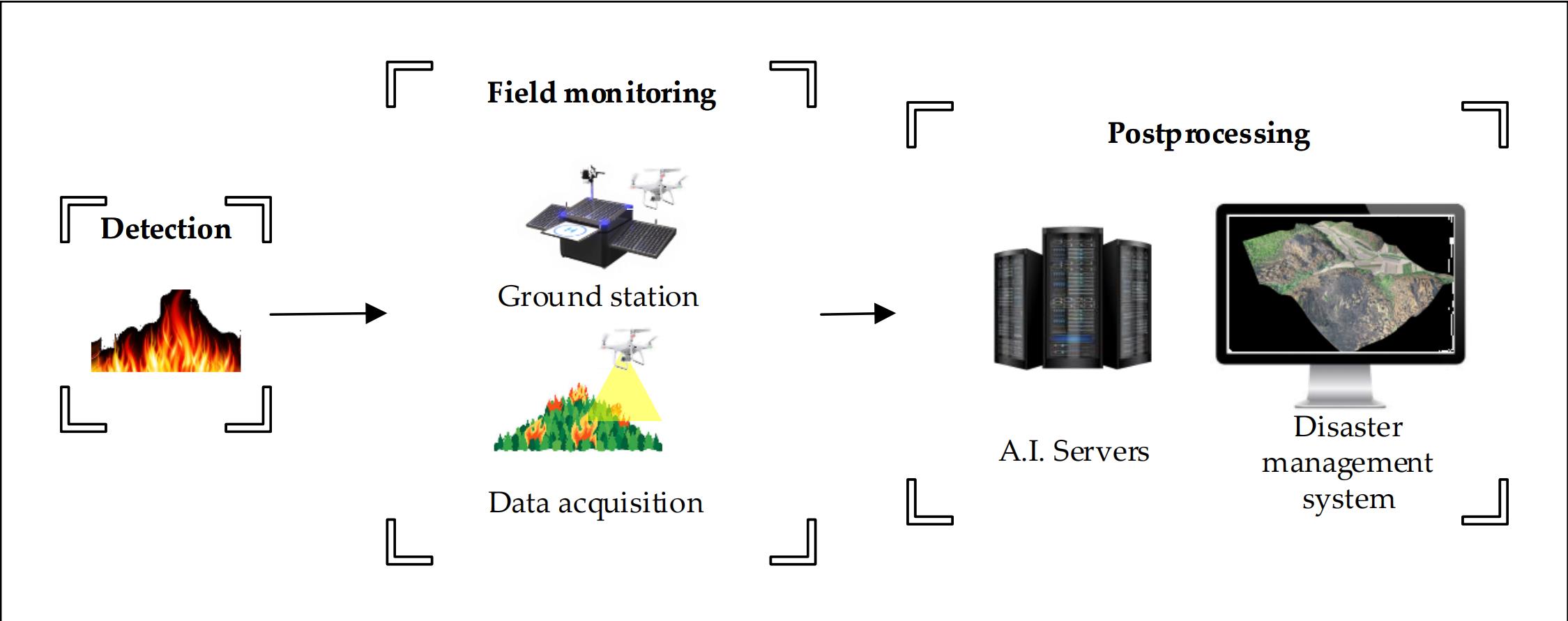
图1:基于无人机(UAV)的森林火灾监测系统的概念框架
二、研究的数据集及其处理
1.文章研究使用的原始数据
数据采集时间地点:2020年5月6日,在一场森林火灾两周后,从朝鲜庆尚北部的安东收集
无人机型号:Phantom 4 Pro V2.0 UAV
无人机拍摄高度:150m
原始图像分辨率大小:5473 x 3648 x 3
数据集数量:采集了火灾地区两个区域的图像,区域一43张,区域二44张
采用的数据增强(对第一次剪裁后的图像):归一化、旋转、缩放、移位
2.对数据进行的预处理
因为高分辨率的图像训练起来较为困难,文章研究者先对它进行了裁剪,将区域一的43张5473 x 3648 x 3的图片被裁剪成了1032张912 x 912 x 3的图片,区域二的44张5473 x 3648 x 3的图片裁剪成了1056张912 x 912 x 3的图片,并对裁剪后的图片进行标注。

图二:裁剪前的图像

图三:裁剪后的图像

图四:对裁剪后的图像标注
三.文章提出的网络模型
1.文章提出的模型方法
(1)将被剪裁好的912 x 912 x 3图像输入UNet++网络,得到912 x 912 x 1的预测结果;
(2)依据petch-level 1预测的结果,选取要用于petch-level 2 的128 x 128 x 3 图像和128 x 128 x 1的标注(如果笔者没理解错,那么原论文里的图片即下图是不严谨的,并不是把level 1的结果直接剪裁输入)
Q:这里面128 x 128 x 3的图像是直接从912 x 912 x 3图像上裁剪而来,文章里说的不清楚,看了源代码后发现他是类似使用一个228 x 228的滑动窗口来遍历level 1的预测结果,只要这个窗口内只要存在被判断为烧焦区域的像素就把从912 x 912图片剪裁后的图片(128 x 128)编号加入,源代码里是直接用了两个用绝对路径表示的文件夹,文件里存放着图片合lebel,笔者猜测是不是文章作者提前分割好了图片和标注并按照分割顺序编号,然后再来选取level 2需要的图片,但是原码里面每次筛选像素的窗口大小是228 x 228,为什么要用228大小的窗口而不是128的窗口,笔者这里还比较疑惑。
(3)将选取好的128 x 128 x 3的图像输入UNet,输出为128 x 128 x 1的预测结果,依据预测结果将输入图像合并调整成5472 x 3648 x 3的RGB图像,即与无人机拍摄的图像shape一样。
(4)将得到的图像上传到DroneDeploy 平台上进行正光生成和进一步处理,得到灾害管理系统(DMS)需要的图像。
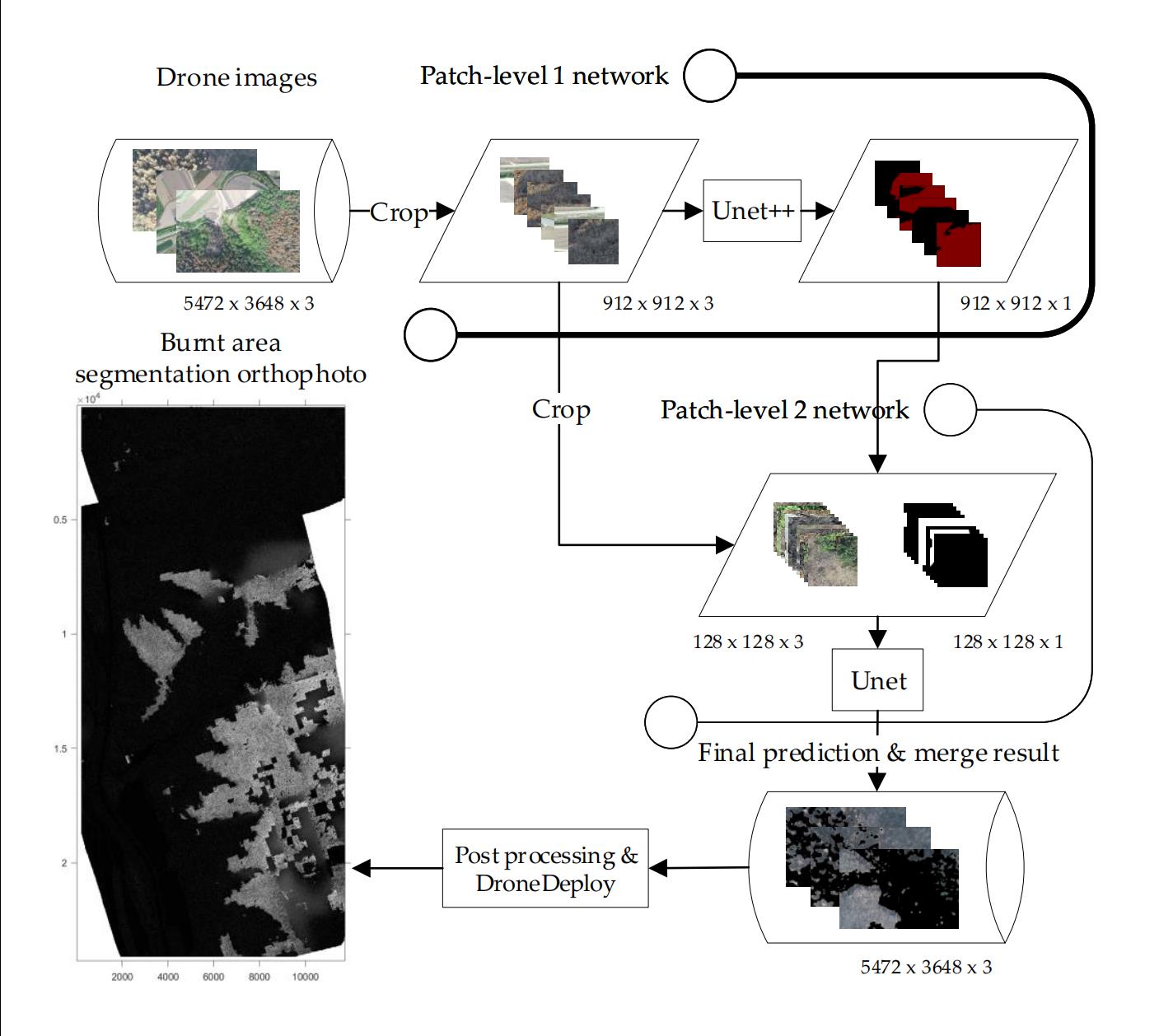
图五:文章提出的模型结构
2.UNet与UNet++
本部分参考:【Unet系列】Unet & Unet++_OneCoder的博客-CSDN博客
UNet
- 使用的方法?
- 继承FCN的思想,继续进行改进。但是相对于FCN,有几个改变的地方,U-Net是完全对称的,且对解码器(应该自Hinton提出编码器、解码器的概念来,即将图像->高语义feature map的过程看成编码器,高语义->像素级别的分类score map的过程看作解码器)进行了加卷积加深处理,FCN只是单纯的进行了上采样。
- Skip connection:两者都用了这样的结构,虽然在现在看来这样的做法比较常见,但是对于当时,这样的结构所带来的明显好处是有目共睹的,因为可以联合高层语义和低层的细粒度表层信息,就很好的符合了分割对这两方面信息的需求。
- 联合:在FCN中,Skip connection的联合是通过对应像素的求和,而U-Net则是对其的channel的concat过程。
- Innovation:
- overlap-tile策略
- 随机弹性变形进行数据增强
- 使用了加权loss
- result
- 相对于当年的,在EM segmentation challenge at ISBI 2012上做到比当时的best更好。而且速度也非常的快。其有一个很好的优点,就是在小数据集上也是能做得比较好的。
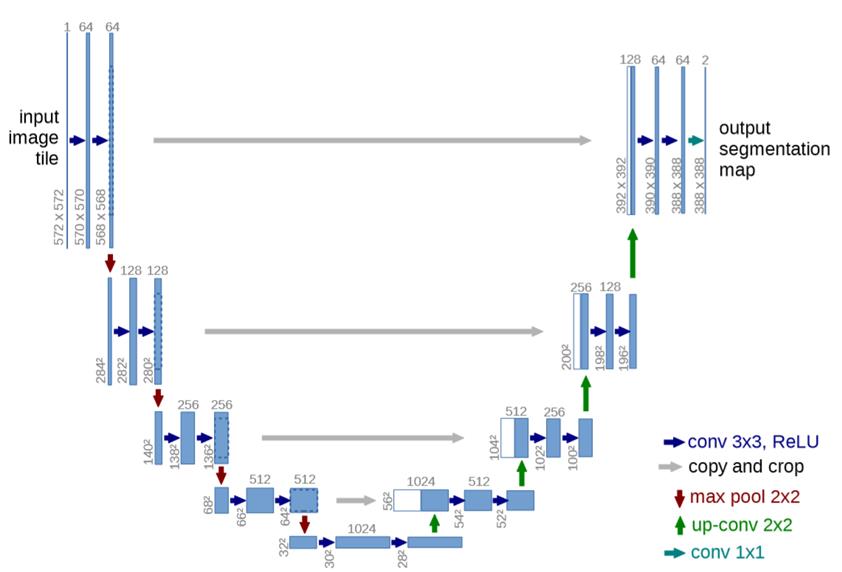
图六:UNet结构示意图
- 相对于当年的,在EM segmentation challenge at ISBI 2012上做到比当时的best更好。而且速度也非常的快。其有一个很好的优点,就是在小数据集上也是能做得比较好的。
UNet++
- 解决的问题?
- 对以前的论文做了一个简短的总结:对于分割任务,都会有一个共识,就是skip connection。目前对自然图像的分割效果蛮好,对生物医学图像的分割一般。
- 主要的原因可能还是(1)数据集的量(2)生物医学图像相较于自然图像来说,本身分割难度大,体现在生物图像中分割目标边界模糊、变形一类的复杂情况。
- 使用的方法?
- Unet的增强版,灵感来源于DenseNet。但实际上,在此之前有一个思想是一样的工作,可以说是Unet的工作与其如出一辙,根据任务进行了调整而已。
- 深度监督
- result
- 想对于UNet和wide UNet(wide IOU是相对与UNet的参数增加,使其与Unet++在参数上相差无几,减少相互对比中的不一样的条件)各自有3.9和3.4的平均IOU的提升。
- More
- 文中提到可以将Unet++作为Mask rcnn的backbone architecture。但是文中没有给出具体做法
- 加中间的Dense block所基于的一个假设:让received encoder feature maps和the corresponding decoder feature maps are semantically similar,这样会使优化器更好的优化。
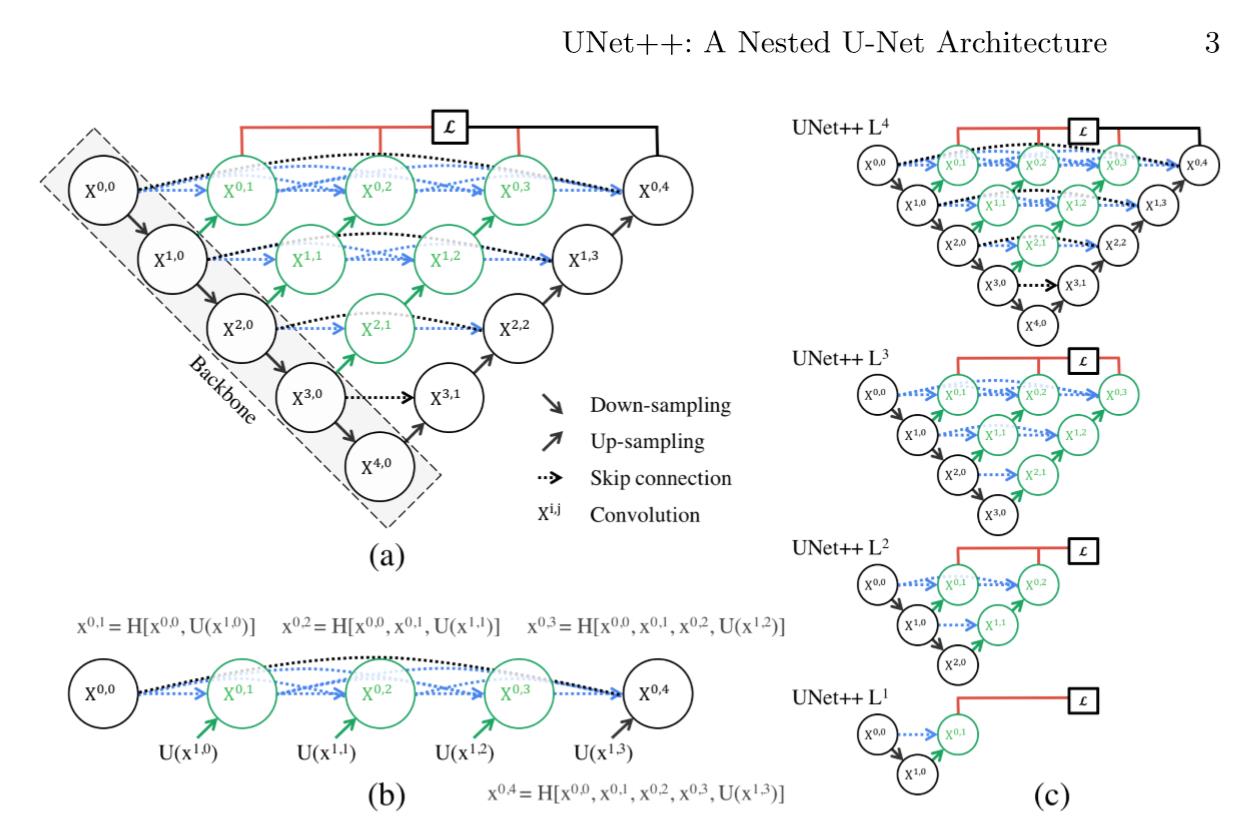
图七:UNet++结构示意图
3.损失函数与评估指标
损失函数
文章在petch-level 1使用了Focal Loss损失(1),petch-level 使用了Binary Cross Entropy损失(2)

文章里比较了两个level都使用FL损失、都使用BCE损失、两个level分别使用其中一种损失这四种情况,发现上面提出的损失函数使用方式效果是最好的,笔者觉得可能是因为level 1的输入因为是原始图像,存在较多数据不平衡问题,所以使用FL损失更好,而level 2的图像是经过level 1的结果筛选的,而筛选方式是预测结果存在烧焦的部分,那么level 2输入的数据,其数据不平衡问题就不会那么突出,主要需要区分预测像素是否是被烧焦区域,那么使用二值交叉熵损失就更为合适了。
表1:损失函数有效性-在区域1上进行训练,并在区域2上进行测试。

表2:损失函数有效性-在区域2进行训练,并在区域1进行测试。

评估指标
经典的图像分割评价指标。DiceCoefficient(3)测量了真实值和预测值之间的重叠部分;Sensitivity(4)测量了在正样本中被正确分割的像素的百分比;Specifificity(5)值测量了被预测为负样本的准确性。
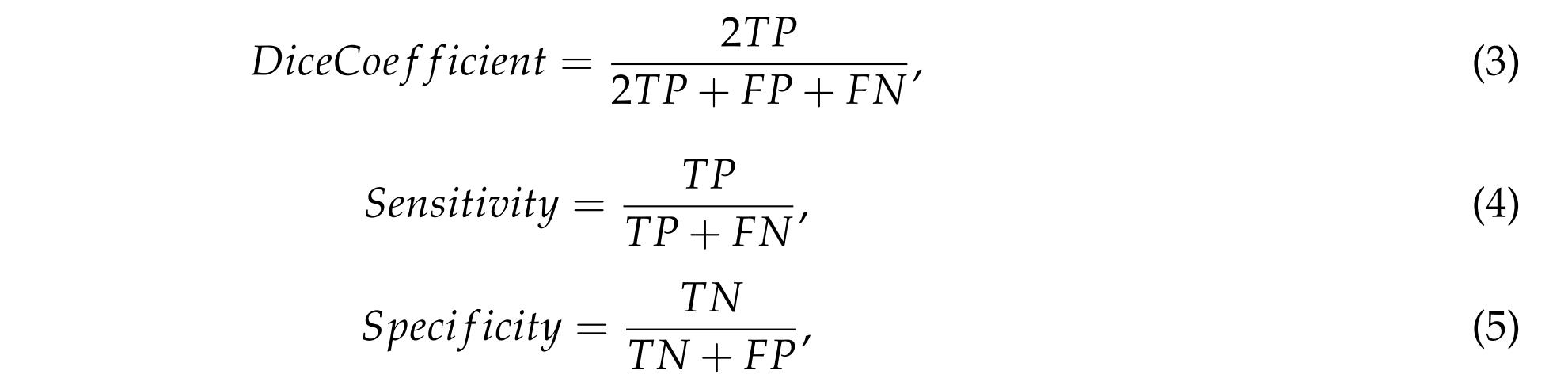
四.文章提出模型的性能
论文作者对比了只使用Patch-Level 1 Network、只使用Patch-Level 2 Network者和Patch-Level 2 Network Proposed Method,证明其性能。
使用的共同参数
优化器:Adam
学习率:0.0001
epoch:30
batch size:1
输入的图片大小及数量(对同一数据集使用了不同的裁剪和输入方式)
表3:来自两个区域的训练图像的数量

表4:该模型在区域1上进行训练,并在区域2上进行测试的表现

表5:该模型在区域2上进行训练,并在区域1上进行测试的表现

图八:在合并后的原始图像上得到不同模型的分割结果
本文得出的结论
1.双补丁级模型比单图像分割模型效果更好,同时对于农场道路这种易混淆难分割的目标分割效果更好;(作者认为petch-level 2网络可以细化第一个模型的结果,使得预测可以有更好的性能)
2.证明FL作为损失函数在优化模型和提高模型在测试集上的性能方面的有效性;
3.介绍了一种无人机图像预处理和后处理方法,并公开。(似乎就是利用DroneDeploy平台来处理)
本文提出存在的限制
1.双补丁级模型需要在不同天气条件下的不同地点进行训练,以提高其性能;
2.该方法现在已在本地进行处理。需要将其转换为一个在线平台,以提高其实用性,减少其时间消耗。
总结与思考
1.从数据来看,本文使用的是火灾发生后,天气良好情况下从150m高空无人机拍摄的照片,考虑到拍摄角度位置问题,作者使用了旋转、缩放、位移的数据增强,同时文章提出该模型需要在不同天气下进行训练,但如果在数据集有限的情况下,应对这种情况,还可以尝试采用ColorJitter,对图像颜色的对比度、饱和度、亮度、色相等进行变换;
2.文章只对比了UNet,UNet++,和他们组合使用的效果,但是使用数据的分辨率和数量都不一样,这种比对的合理性有待考察(相同数据集不同处理方式,如果使用了相同的处理方式又是什么样呢);另外作者没有解释为什么petch-level 1用UNet++,但是level 2就用了UNet,如果使用UNet++效果会不会更好呢,还有文章对比的UNet++只输入了一千张左右的高分辨率照片,如果把裁剪成128 x 128 x 3后的一万多张小照片再放进去对比又是什么样的呢;
3.作者对于level 1到 level 2过度这一块讲的比较模糊,只说是依据level 1的结果选出存在烧焦预测值小区域输入到level 2,但是这里面如何再次分割和编号没有说明,同时level 使用的lebel是直接使用原始lebel分割,还是结合了第一次的预测结果进行了处理呢,源代码里面使用了两个突然出现的绝对路径的文件夹,这里面的文件是否是提前分割好的还无从查证;
4.感觉本篇文章的作者对算法的描述都不算很详细(或者说本文的创新点不在于算法而是在于对数据的使用?),像如何进一步分割和合并预测结果这些细节都是一笔带过,同时也没有公开它的数据集,也没有说明它采用的预训练权重是什么,文章里没有提到,源代码里是直接调用绝对路径里的文件,如果要想把本篇论文的代码放入实际应用之中,还有很多细节要解决。
PS:这是笔者写的第一篇博客,对于计算机视觉方向笔者也只是个新手,如果有不对的地方,还请大家批评指正,也欢迎各位一起讨论。
以上是关于论文总结Damage-Map Estimation Using UAV Images and Deep Learning Algorithms for DMS的主要内容,如果未能解决你的问题,请参考以下文章
论文学习-sparse methods for direction of arrival estimation1.
A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 论文解读(SIGMOD 2
论文翻译ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
[论文笔记]Depth-Aware Multi-Grid Deep Homography Estimation with Contextual Correlation
《Boosting Monocular Depth Estimation Models to High-Resolution ...》论文笔记
《MonoIndoor:Towards Good Practice of Self-Supervised Monocular Depth Estimation...》论文笔记