《MonoIndoor:Towards Good Practice of Self-Supervised Monocular Depth Estimation...》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《MonoIndoor:Towards Good Practice of Self-Supervised Monocular Depth Estimation...》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:None
1. 概述
介绍:经典的自监督深度估计方法已经在KITTI数据集上取得了较为不错的效果,但是在一些室内或是相机能够自由移动(KITTI场景下相机固定在车上)的场景下,现有的经典自监督深度估计算法就出现了问题。这篇文章研究的便是这些场景下的自监督深度估计,在该文章中指出自监督深度估计在这些场景下性能出现较大幅度下降是因为如下两点原因:
- 在这些场景下深度的范围是变化比较大的,特别是在一些室内场景下,随着视角的变化图像中深度的范围会存在较大范围变化。而在KITTI的场景下最远处是天空其深度的变化范围相对来讲比较小;
- 在KITTI数据场景下摄像头是被固定在车辆上的,犹豫是刚性连接其运动主要体现在摄像头的径向平移运动上,其在旋转分量上的变化相对较小。而上述提到的室内或是相机自由运动的场景,其同时在平移和旋转上存在变化量,这就是得对应Pose估计网络部分难以胜任对应任务,从而导致深度估计性能的下降;
对于上面两点文章专门提出了对应的解决方案,其具体为:
- 1)对于深度范围变化:这里使用一种带attention的网络模块区域预测对应深度范围(scale)的概率分布,对于具体范围的值是通过积分的形式计算得到,文章对此的解释是使得训练更加鲁棒;
- 2)对于Pose网络估计不准确:由于KITTI主要的pose变化量在平移分量上,同时预测旋转和平移会对网络带来较大困难,对此文章引入一种迭代残差优化的形式进行解决,从而估计出较为准确的pose变化量;
这篇文章对于pose估计问题是通过残差级联优化的形式进行解决,在之前的一篇文章:
Unsupervised Depth Learning in Challenging Indoor Video: Weak Rectification to Rescue
在这篇文章中也明确指出影响自监督深度估计网络性能的点在输入数据平移和旋转属性上,其在不同数据集下的对比差异见下图:
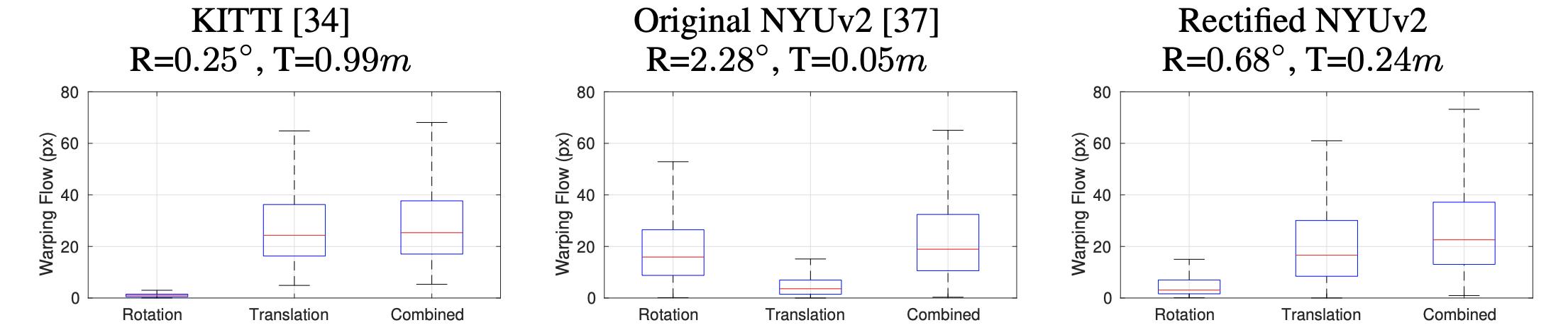
因而在这篇文章中提出了一种数据预处理的方案,也就是通过如下几步实现训练数据筛选:
- 1)Step1:在输入的视频序列中按照一种设定好的采样策略对视频序列进行采样,之后通过SIFT算子提取特征点,并计算特征点之间的匹配关系;
- 2)Step2:根据匹配关系通过随机采样一致性方法(RANSAC) X 1 = H X 2 X_1=HX_2 X1=HX2计算本质矩阵 H H H,并通过矩阵分解得到对应的旋转分量;
- 3)Step3:通过对应旋转分量将pair图像对通过正转和反转操作变换到共有平面上去,实现旋转分量消除或是减少;
2. 方法设计
2.1 整体pipeline
文章的整体方法是参考自MonoDepth2的,其结构见下图所示:
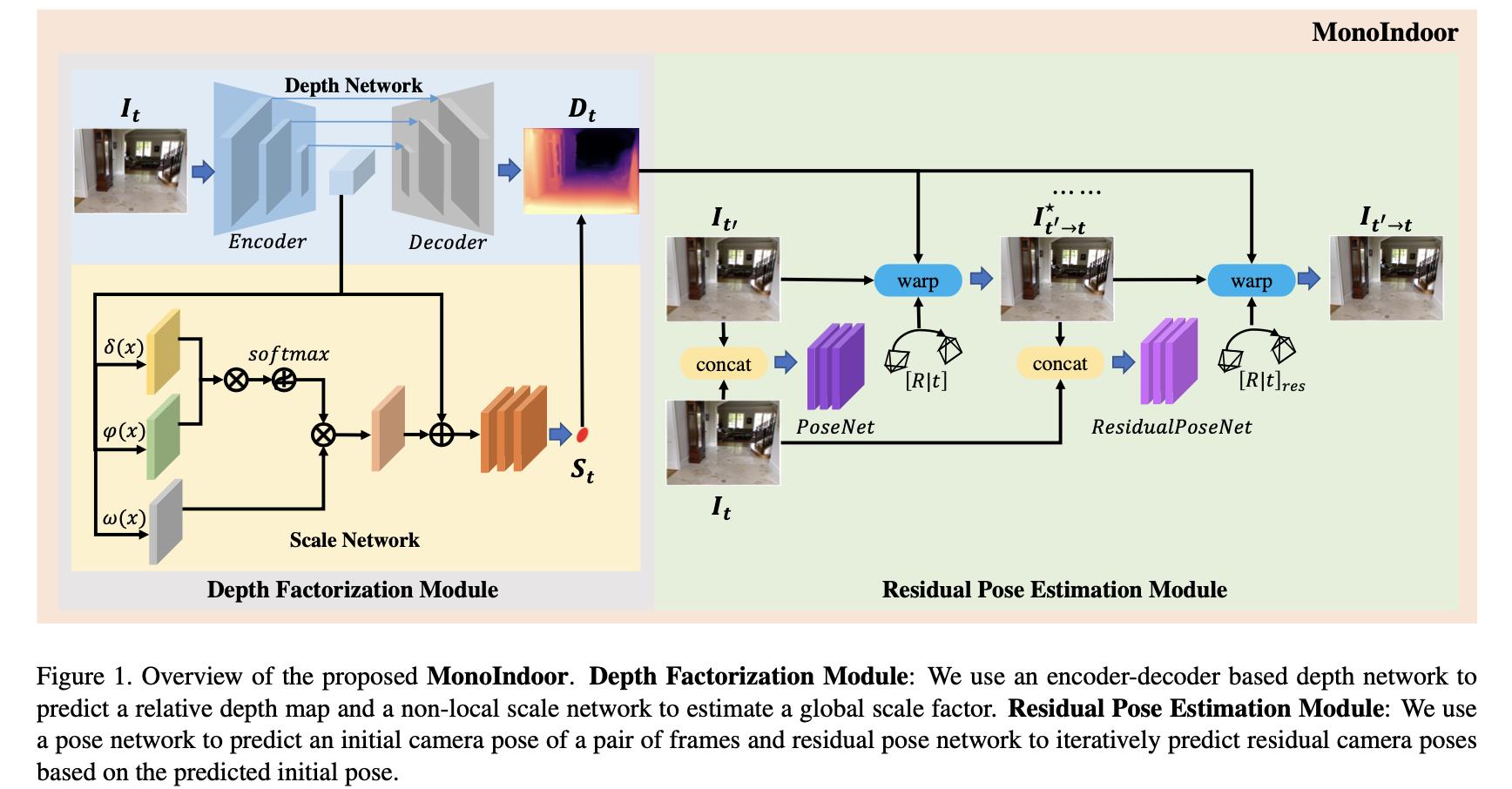
相比MonoDepth2方法文章主要是提出了两个子模块:
- 1)Depth Factorization Module:为变化的输入场景设置一个适配的深度变化scale,从而使得网络不会因为深度范围存在较大变化而导致性能下降;
- 2)Residual Pose Estimation Module:通过级联优化的形式优化pose,减少手持等情况引入的旋转运动分量,提升整体pose估计的质量;
2.2 自监督约束
这里设target图像为
I
t
I_t
It,source图像为
I
t
′
I_t^'
It′,这里是需要估计出target图像对应的深度结果
D
t
D_t
Dt,估计出来的pose变量为
T
t
→
t
′
T_t\\rightarrow t^'
Tt→t′。在已知相机内参数
K
K
K的情况下source到target的映射描述为:
I
t
′
→
t
=
I
t
′
⟨
p
r
o
j
(
D
t
,
T
t
→
t
′
,
K
)
⟩
I_t^'\\rightarrow t=I_t^'\\langle proj(D_t,T_t\\rightarrow t^',K)\\rangle
It′→t=It′⟨proj(Dt,Tt→t′,K)⟩
映射之后的图像会与真正的target图像做光度重构误差度量:
ρ
(
I
t
,
I
t
′
→
t
)
=
α
2
(
1
−
S
S
I
M
(
I
t
,
I
t
′
→
t
)
)
+
(
1
−
α
)
∣
∣
I
t
,
I
t
′
→
t
∣
∣
1
\\rho(I_t,I_t^'\\rightarrow t)=\\frac\\alpha2(1-SSIM(I_t,I_t^'\\rightarrow t))+(1-\\alpha)||I_t,I_t^'\\rightarrow t||_1
ρ(It,It′→t)=2α(1−SSIM(It,It′→t))+(1−α)∣∣It,It′→t∣∣1
对于有多个source图像的情况其光度重构误差描述为:
L
A
=
∑
t
′
ρ
(
I
t
,
I
t
′
→
t
)
L_A=\\sum_t^'\\rho(I_t,I_t^'\\rightarrow t)
LA=t′∑ρ(It,It′→t)
在target图像的引导下会对深度的结果进行平滑约束:
L
s
=
∣
∂
x
d
t
∗
∣
e
−
∂
x
I
t
+
∣
∂
y
d
t
∗
∣
e
−
∂
y
I
t
L_s=|\\partial_xd_t^*|e^-\\partial_xI_t+|\\partial_yd_t^*|e^-\\partial_yI_t
Ls=∣∂xdt∗∣e−∂xIt+∣∂ydt∗∣e−∂yIt
其中 ,
d
∗
=
d
/
d
ˉ
d^*=d/\\bard
d∗=d/dˉ代表的是经过均值归一化之后的深度图。这里也同样采用了MonoDepth2中的auto-mask的机制去排除那些存在运动非静止的目标。对于帧间还做了帧间深度连续约束:
L
c
=
∣
D
t
−
D
ˉ
t
′
→
t
∣
D
t
+
D
ˉ
t
′
→
t
L_c=\\frac|D_t-\\barD_t^'\\rightarrow t|D_t+\\barD_t^'\\rightarrow t
Lc=Dt+Dˉt′→t∣Dt−Dˉt′→t∣
其中,
D
ˉ
t
′
→
t
\\barD_t^'\\rightarrow t
Dˉt′→t代表的是深度按照之前图像映射的流程映射的结果。则整体的损失函数被描述为:
L
=
L
A
+
τ
L
s
+
γ
L
c
L=L_A+\\tau L_s+\\gamma L_c
L=LA+τLs+γL
Towards Deep Learning Models Resistant to Adversarial Attacks
Evolutionary approaches towards AI: past, present, and future
论文阅读 Towards Unified Surgical Skill Assessment
论文阅读CodeTrans: Towards Cracking the Language of Silicon‘s Code......
论文阅读CodeTrans: Towards Cracking the Language of Silicon‘s Code......
每日一读Towards Understanding the Instability of Network Embedding