论文阅读CodeTrans: Towards Cracking the Language of Silicon‘s Code......
Posted 桥本环奈粤港澳分奈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读CodeTrans: Towards Cracking the Language of Silicon‘s Code......相关的知识,希望对你有一定的参考价值。
CodeTrans: Towards Cracking the Language of Silicon’s Code Through Self-Supervised Deep Learning and High Performance Computing
paper地址:https://www.aclweb.org/anthology/P18-1103.pdf
代码地址:https://github.com/baidu/Dialogue
一、简介
CodeTrans是一种用于软件工程领域任务的encoder-decoder transformer 模型,文章展示了模型对6个软件工程任务的有效性。
二、 数据集
有监督的:
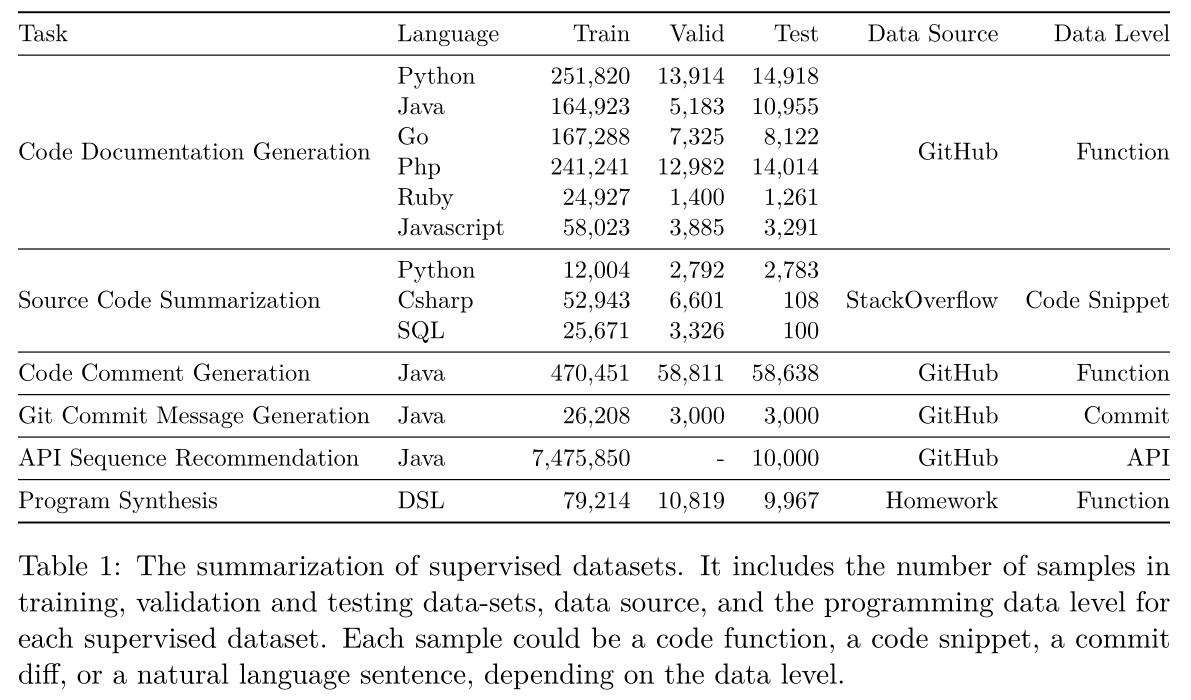
API序列推荐数据集的样本数量最多,代码注释生成数据集第二。
6个任务中有4个是从GitHub中提取的数据集。
6个任务中有三个使用函数级作为输入,而不是完整的程序级输入。
Code Documentation Generation
任务:给定代码函数,生成相关描述文档。
数据集:CodeSearchNet,包含六种编程语言的函数/方法(Python、Java、Go、php、Ruby和javascript)
https://github.com/microsoft/CodeBERT
Source Code Summarization
任务:给定一个简短的代码片段,生成摘要。
数据集:代码片段来自只包含一个代码片段的已接受的答案,摘要是问题的相应标题。
https://github.com/sriniiyer/codenn
Code Comment Generation
任务:与代码文档生成一样,该任务主要关注为Java函数生成JavaDoc。
数据集:来自Github 9714个Java开源项目的Javadoc评论,Javadoc描述中的第一句话被提取为预期的注释。
https://github.com/xing-hu/DeepCom
Git Commit Message Generation
任务:生成一个提交消息来描述Git Commit的变化。
数据集:基于拥有最多Github星星的1000个Java存储库
https://sjiang1.github.io/commitgen/
API Sequence Recommendation
任务:给定自然语言描述,生成API使用序列,包括类和函数名。
数据集:从Github中至少有一颗星的Java项目中提取
https://github.com/guxd/deepAPI
Program Synthesis
任务:给定自然语言描述,合成或生成程序代码。
数据集:AlgoLisp,从计算机科学入门课程的课后作业中提取,每个例子都由一个问题和一个答案组成。针对领域特定语言DSL。
https://github.com/nearai/program_synthesis/tree/master/program_synthesis/algolisp
无监督的:
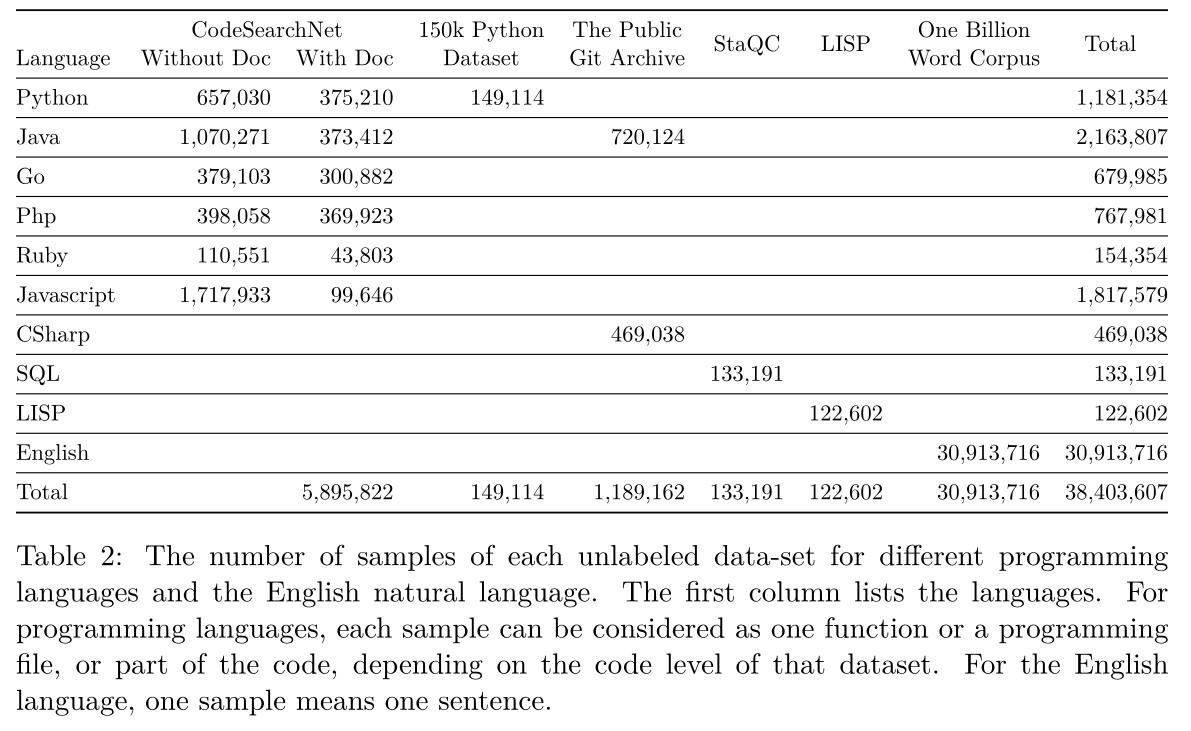
共有大约4000万个样本,其中10亿词语言模型的基准语料库有超过3000万个数据样本,样本数量最多。
编程语言数据集中CodeSearchNet语料库是应用最广泛的语料库。
Java语言拥有最多的自监督示例,有超过200万个输入,其次,Javascript和Python各有超过一百万的样本。Ruby、SQL和LISP具有最少数量的自监督输入,样本约15万或更少。
在迁移学习、训练前阶段和多任务学习中使用未标记的数据集,有助于在软件工程领域为任务构建语言模型,并使最终模型更通用。
CodeSearchNet Corpus Collection
数据集:CodeSearchNet ,数据集分为两部分:带函数文档的函数和不带文档的函数。
在自我监督训练中,将这两个部分一起使用:
- 没有文档的函数直接将每个函数作为单独的句子序列。
- 带文档的函数连接函数及其文档作为合并的句子序列输入。
Public Git Archive
数据集:CSharp 、Public Git Archive
Public Git Archive在文件级有代码,其中包含导入语句、多个函数和注释。这样的文件级数据可以帮助模型理解更多的信息,比如API的使用情况以及不同函数之间的关系。
https://github.com/src-d/datasets/tree/master/PublicGitArchive
150k Python Dataset
数据集中的Python程序从GitHub存储库收集,通过删除重复文件,分叉的项目和模糊的文件。这个语料库中的Python代码也是一个文件级代码,比如Public Git Archive dataset。
https://github.com/src-d/datasets/tree/master/PublicGitArchive
StaQC
SQL未标记数据集,代码段级别的,而不是整个文件级别的代码。
https://github.com/LittleYUYU/StackOverflow-Question-Code-Dataset
LISP
收集来自GitHubLISP主题,为函数级LISP代码。
https://github.com/topics/lisp?o=desc&s=stars
10亿词语言模型基准语料库
英语数据集,源于WMT11网站。对数据进行归一化和标记化,删除重复的句子。筛除所有计数低于3的单词来构建词汇表,句子顺序随机。包含了近10亿个单词的训练数据。
http://statmt.org/wmt11/training-monolingual.tgz
三、方法
模型
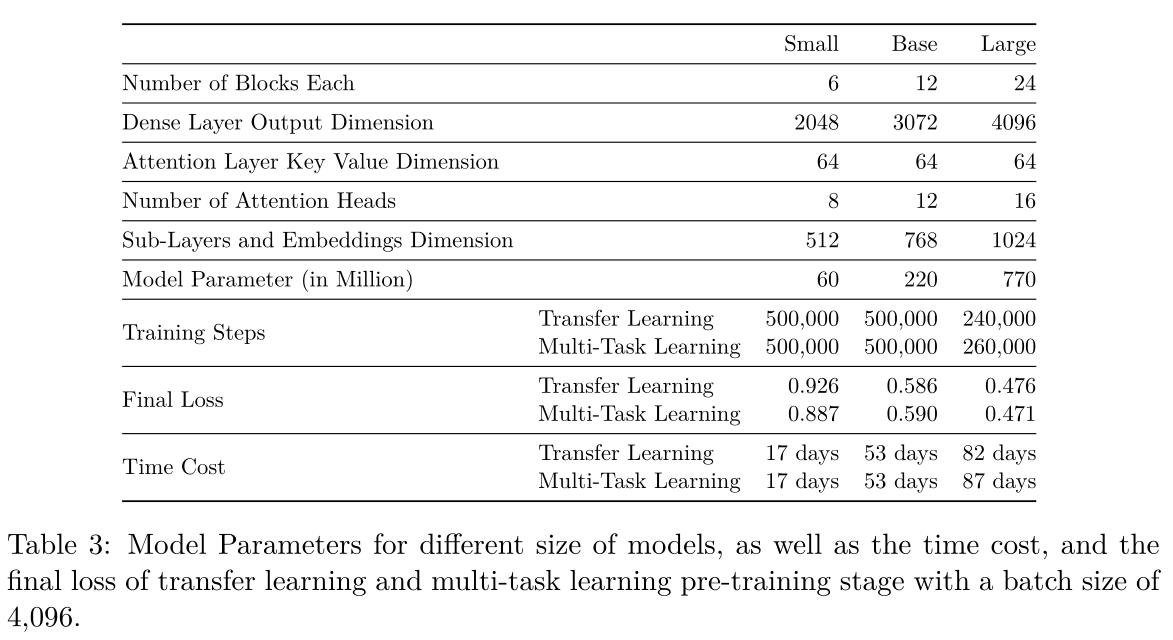
采用了encoder-decoder模型和T5框架,输入和输出长度设置为512,自我监督的目标采用了span-corruption,corruption rate为15%。
将平均有三个corrupted的token的span视为一个整体,并使用一个唯一的mask token来替换掉。
注:
1、这里提到的T5是指文本到文本的迁移transformer, T5在Masked语言模型的“span-corruption”目标上进行了预训练,其中输入token的连续跨度被mask token替换,并且训练了模型以重建被mask的token。
2、俺理解的corruption rate为15%是指像SpanBERT一样,mask掉15%,平均长度为3的span
输入
原始输入经过用mask token 替换一些3-gram单词作为输入,和T5不同的是每个样本为一个单独的训练样例,而不是将不同的训练样例连接到最大的训练序列长度。
词汇表
用SentencePiece模型构建词汇表,并对输入输出进行解码和编码
填充token id为0,语句结束(EOS)token为1,未知token为2,语句开始(BOS)token为3
四、实验
1. 单任务学习
使用T5框架分别训练了6个任务(共13个子任务),训练了小size 模型和基础size模型,每个任务生成两个模型,总共26个模型
使用grid search,在 2 5 2^5 25和 2 10 2^{10} 210的范围内调整了batch大小
评价指标:BLEU 、ROUGE
训练中发现:
-
样本数量对模型大小和训练步骤有重要影响。API序列推荐和代码注释生成的数据集最大,用于这两项任务的小模型需要的训练步骤几乎是基本模型的7倍
-
源代码摘要的语料库收敛速度非常快,其中SQL和CSharp数据集,即使batch大小只有32,基本模型也能收敛500个训练步骤,且模型还没有遍历完完整的数据集。如果用更多的步骤训练模型,这个任务的验证集的分数就会变差,很容易对源代码摘要任务过度拟合(因为它的数据集规模小)
-
一半的模型在batch大小为256时达到最佳性能,但在不同的任务之间略有不同,例如源代码摘要任务需要小批量。还发现不管数据集中有多少样本,大的batch size不会带来更好的性能。
2. 迁移学习
预训练阶段使用未标记的数据,微调阶段使用标记了的数据。用T5模型来mask 输入中span,使得模型能够预测mask的内容。
每次训练的batch size为4096,小规模和基础规模模型训练20万步,大规模模型训练24万步。
小规模模型和基础规模模型训练50万步、大模型模型训练24万步后获得预训练模型后,针对13个监督子任务对模型进行了微调。
一半的模型在batch size为256时性能最佳,所以选择256作为批处理大小,以便对下游任务进行微调。
使用T5内置的BLEU和ROUGE分数,根据模型在验证集上的性能,应用早期停止来确定微调步骤。
3. 多任务学习
多任务学习是在混合任务上训练单一模型,不同任务之间共享所有模型参数。允许单个模型使用相同的权重执行多个任务。
使用 examples-proportional 混合,根据每个任务的数据集大小选择样本并连接,确保模型将看到来自小数据集的样本,就像它在每次批处理中看到来自大数据集的样本一样。
每20,000个训练步骤记录模型checkpoint,batch size 4096。通常,所有任务都应该共享同一个最佳性能checkpoint,本文是在验证集上评估模型,并为每个任务选择最佳的checkpoint。因此,每个任务可能有来自同一模型的不同检查点。
4. 带有微调的多任务学习
对多任务学习的checkpoint进行微调,小规模模型和基础规模模型训练50万步、大模型模型训练26万步,batch size 256。
五、实验结果
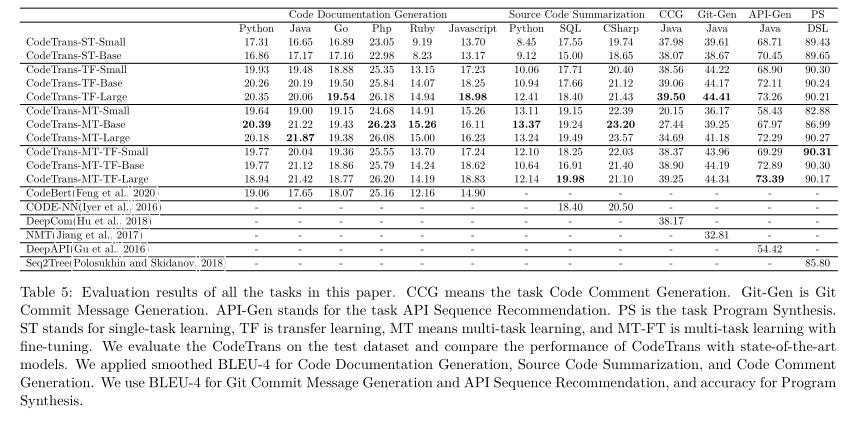
代码文档生成
评价标准:BLEU-4
基准模型:CodeBert
数据集:CodeSearchNet
结果:在所有编程语言上的表现都优于CodeBert。在三种编程语言中,多任务学习总体性能最好,取得了最好的结果。
源代码摘要
评价标准:BLEU-4
基准模型:Code-NN
通过评估SQL和CSharp代码,Code-NN选择了100个带有两个额外人工注释的样本,并在这些样本上计算平滑的BLEU-4
结果:CodeTrans优于Code-NN,且在不同的CodeTrans模型中,多任务学习在用于本任务的两种编程语言上的性能最好。
代码评论生成
评价标准:BLEU-4
基准模型:DeepCom
结果:CodeTrans迁移学习的大模型的性能最好,BLEU得分比DeepCom高出1%以上。多任务学习的CodeTrans模型性能最差。然而,随着模型规模的增加,得分也随之增加。原因是代码注释生成数据集有第二大样本大小(470,451个样本),所以需要更大的模型来开发它们。
Git提交信息生成
评价标准:BLEU-4
基准模型:NMT
结果:CodeTrans迁移学习大模型的BLEU-4得分最高。CodeTrans多任务学习大模型的性能非常接近迁移学习的大模型。
API序列推荐
评价标准:BLEU-4
基准模型:DeepAPI
结果:所有的CodeTrans模型,包括单任务训练,都优于DeepAPI模型。在CodeTrans模型中,只使用多任务学习训练的模型表现最差,这主要是因为该任务的数据集很大。然而,随着多任务学习模型规模的增加,它开始达到接近/优于单任务学习和迁移学习的效果。具有多任务学习微调的CodeTrans大型模型在所有模型中得分最高。CodeTrans迁移学习大型模型也具有类似的良好性能。
程序合成
评价标准:准确度(模型输出是否为最优答案)
数据集:AlgoLisp
基准模型:Seq2Tree
结果:所有的CodeTrans模型,包括单任务训练,都优于DeepAPI模型。在CodeTrans模型中,只使用多任务学习训练的模型表现最差,这主要是因为该任务的数据集很大。然而,随着多任务学习模型规模的增加,它开始达到接近/优于单任务学习和迁移学习的效果。具有多任务学习微调的CodeTrans大型模型在所有模型中得分最高。CodeTrans迁移学习大型模型也具有类似的良好性能。
参考:解读T5: Text-To-Text Transfer Transformer
有帮助的话可以点个赞喔~

以上是关于论文阅读CodeTrans: Towards Cracking the Language of Silicon‘s Code......的主要内容,如果未能解决你的问题,请参考以下文章