论文解读丨无监督视觉表征学习的动量对比
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读丨无监督视觉表征学习的动量对比相关的知识,希望对你有一定的参考价值。
摘要:本文提出了一个用于无监督视觉表征学习的动量对比方法(MoCo)。从将对比学习作为字典查询过程的角度来看,本文构建了一个由队列和移动平均编码器组成的动态字典。
本文分享自华为云社区《论文解读系列二十九:无监督视觉表征学习的动量对比》,作者:谷雨润一麦。

摘要
本文提出了一个用于无监督视觉表征学习的动量对比方法(MoCo)。从将对比学习作为字典查询过程的角度来看,本文构建了一个由队列和移动平均编码器组成的动态字典。这使得可以实时地构建一个巨大的并且具有一致性的字典,因此可以促进对比无监督学习。通过MoCo学习到的特征可以很好地在下游任务完成迁移。MoCo在七个检测和分割任务上都超越了对应的有监督预训练模型,这告诉我们在许多视觉任务上有监督和无监督模型之间的差距已经大大地缩小。
背景
GPT和BERT这些模型充分展示了无监督表征学习在自然语言处理领域的成功。但在计算机视觉领域,有监督的预训练依然占据着主导地位,无监督方法则远远落后。这其中的原因可能是他们各自信号空间的差异性。语言任务拥有离散的视觉信号,这有助于构建令牌化的字典,无监督学习正是基于这种字典。相比之下,视觉任务更加关注字典的构建,因为原始的信号位于连续的高维空间,它不像单词一样对人类的交流来说是结构化的。
动机
从视觉信号空间角度出发,本文猜想需要构建一个具有以下两个特征的字典:(1)大容量的(2)在训练过程中的演变需要具有一致性。直觉上,一个更大的字典可以更好的采样底层的连续高维视觉空间。与此同时,字典中的键应由相同的或者相似的编码器表示,以便他们与查询的比较具有一致性。
本文提出了Momentum Contrast (MoCo),将其作为为无监督学习构建大型一致性字典的方法(如图一)。本文将字典作为一个数据样本的队列来进行维护:当当前的小批量数据的编码表示入队的时候,时间最久的批次就会出队。通过这种队列的方式,将字典大小和小批量大小解耦,让字典的规模可以变得更大。更重要的是,

图一 动量对比
方法
作为字典查询的对比学习
对比学习以及它最近的发展,都可以看做是训练一个用来做字典查询的编码器。我们考虑一个待编码的查询q和一系列待编码的样本k~0~,k~1~,k~2~,$\\ldots$,他们构成了字典的键。假设字典中有一个键(标记为k~+~)正好是查询q需要匹配的,当q和正样本键k~+~非常相似,和其他所有的负样本键都不相似时,损失函数的值应该是非常低的,而对比损失函数正是这样一个函数。当用点积来度量两个键的相似性时,这就是InfoNCE 这个对比损失函数,也正是本文所采用的对比损失函数:
其中$\\tau$是一个温度超参数,分母是同时计算了一个正样本和K个负样本之和。实际上这个函数的本质是一个基于softmax的(K+1)类分类器的对数损失函数。这个表达式中,分类器试图将q分类为k~+~。
对比损失函数作为无监督学习方法的目标函数,被用来训练表征查询和键的编码网络。一般情况下,查询可以被表示为$q=f_q(x^q)$,其中$f_q$是一个编码器网络,$x^q$是一个查询样本(键的表示是类似的,$k=f_k(x^k)$)。他们的初始化取决于特定的代理任务,输入$x^q$和$x^k$可以是图像,图像切片或者由一系列切片构成的上下文。编码网络$f_q$和$f_k$可以是相同的,部分共享的或者完全不同的。
动量对比
从上面的描述可以看出,对比学习是一种在高维连续输入(例如图像)上建立离散字典的方法。因为输入键是随机采样的,因此字典也是动态的,并且在推理过程中键编码器会不断演变。本文假设好的特征表达可以通过一个包含丰富负样本的大字典学习到,与此同时,尽管键编码器会不断演变,但对字典的键的编码应最大可能保持一致。基于上述假设,本文提出了动量对比。
字典作为一个队列。文本方法的核心在于用数据样本的队列来维持字典,这样可以对来自
前面小批次的编码键进行重用。通过引入队列,本文将字典的大小与数据批次的大小解耦开来,因此本文的字典大小可以远大于常用的批次的大小。
字典中的样本是循序渐进逐步被替代的。当前批次的数据入队,最先进入的批次就出队。这样字典总是表征了全体数据的一个采样子集,与此同时维持这个字典的额外开销也是可管理的。更重要的是,移除掉最先进入队列的样本批次也是非常合理和有利的,因为它编码的键是最过时的和当前最新的数据的一致性是最小的。
动量更新。使用队列可以让字典更大,但同时也让更新键编码器的反向传播变得困难,梯度需要传播到队列中的所有样本。一个简单的解决办法是直接从查询编码器$f_q$直接复制键编码器$f_k$,不考虑键编码器的梯度。但是这个方法在实验中表现非常差,本文猜想导致这个问题的原因是,快速地改变键编码器降低了键表征的一致性。因此本文提出了动量更新的策略来解决这个问题。
具体来说,用$\\theta_k$和$\\theta_q$分别表示编码器$f_k$和$f_q$的参数,然后通过下面的式子对参数$\\theta_k$进行更新:
其中$m \\in \\left[ 0, 1 \\right)$是动量系数,只有参数$\\theta_q$通过反向传播进行更新。通过公式(2)的更新方式,$\\theta_k$要比$\\theta_q$更新的更加平滑。最终,虽然队列中的键是被不同的编码器进行编码的,但是这些编码器之间的差异非常小。从实验结果来看就是,一个相对更大的动量系数(例如:$m=0.999$)效果要好于更小的值(例如:$m=0.9$),从中我们也可以看出一个变化缓慢的键编码器是利用队列的核心。
和以往方法的关系。MoCo是一个通用的利用对比损失函数进行学习的机制。本文将它和现有的另外两种通用机制(如图二)进行了对比,他们的不同特性主要体现在字典大小和一致性这两个方面上。
图二 三种不同对比损失的机制的比较
图二a展示的通过方向传播进行梯度更新的端到端的方式是一个非常自然的机制,他利用当前批次的样本作为字典,因此这些键的编码具有表征具有一致性。但对应的字典大小就和批量大小发生了耦合,而批量大小又被GPU的显存大小限制住了。与此同时大批量数据的优化问题也是一个挑战。
另一个机制就是内存池的方法,如图二b所示。内存池由数据中的所有样本的表征组成,每一个批次的字典都可以不用通过反向传播直接从内存池中随机采样,因此他可以支持足够大的字典规模。但内存池中的样本表征在它上次别看见之后就会更新,因此在一个轮次中的不同迭代步数中他们是不具备一致性的。动量更新的方法从内存池方法改进而来,不同的是本文提出的方法是在编码器上更新而不是直接对样本的表征进行更新。因此MoCo不需要记录每一个样本,更重要的是,MocCo在内存利用上更加的有效,而且可以在亿级别上的数据进行训练,这对基于内存池的方法来说是不切实际的。
代理任务
对比学习可以驱动各种代理任务,本文关注的交点不是设计一个新的代理任务,因此采用了一个简单的实例区分任务作为代理任务。具体来说,如果一个查询和一个键他们来自同一张图片,那么我们就认为他们是一对正样本对,反之则是一对负样本对。和之前的方法一样,本文对同一张图片进行随机的数据增强形成两张不同视角的图片作为正样本对。然后编码器$f_q$和$f_k$分别对查询和键进行编码,编码器$f_q$和$f_k$可以是任意的卷积神经网络。
实验
线性分类方案
首先利用MoCo在ImageNet-1K数据集上进行无监督训练,然后固定编码器的参数,再通过有监督的方式训练一个线性分类器。分类器的输入为编码器的输出特征的平均池化,分类器由线性层和softmax层组成,最后在ImageNet验证集上进行测试。
本文对比了三种不同对比损失的机制的表现如图三所示。
图三 三种对比损失机制的结果对比
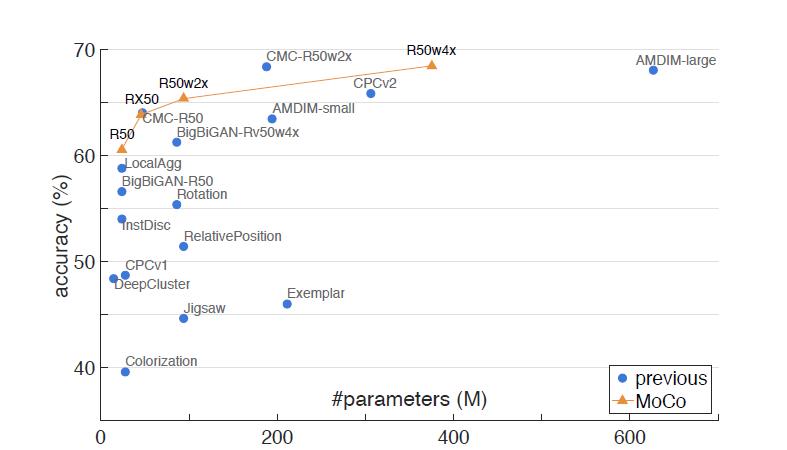
同时和已有的方法做了对比,在相同参数的情况下准确率都超过了现有方法。
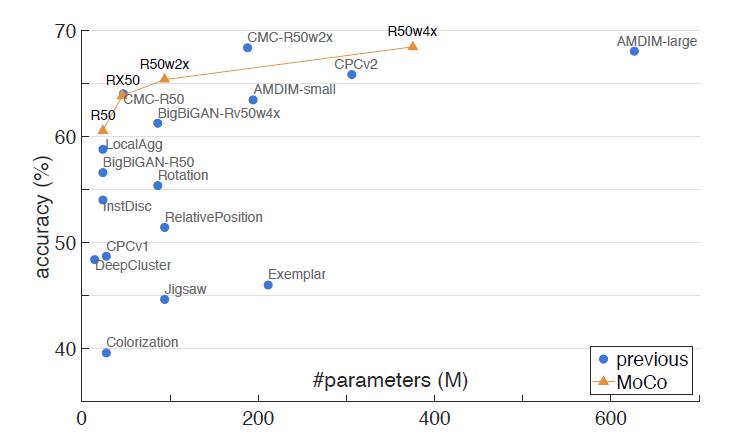
图四 在ImageNet上的线性分类器结果对比
特征迁移方案
无监督学习的主要目标就是学习具有可迁移性的特征,ImageNet监督预训练在作为下游任务微调的初始化中的影响是最大的。本文对比了MoCo和ImageNet监督训练得到的模型,在迁移到不同数据集上不同任务的表现。在大部分情况下,MoCo都得到了优于ImageNet监督训练的表现。
图五 PASCAL VOC 数据集上微调目标检测任务和现有方法对比结果
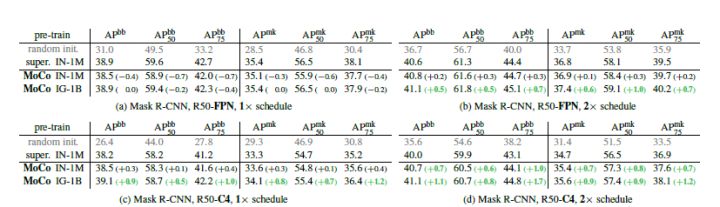
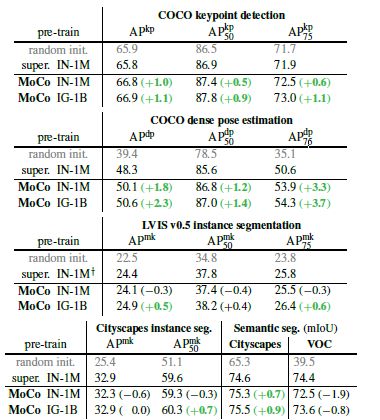
图六 目标检测和实例分割任务在COCO上的微调与ImageNet监督训练对比
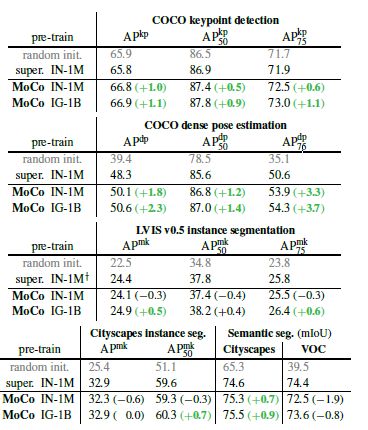
图七 MoCo和ImageNet有监督预训练在其他任务上的对比
点击关注,第一时间了解华为云新鲜技术~
以上是关于论文解读丨无监督视觉表征学习的动量对比的主要内容,如果未能解决你的问题,请参考以下文章
论文解读NAACL 2021 对比自监督学习的上下文和一般句子表征:以篇章关系分析为例
论文解读-SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS
论文解读-SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS
论文解读-SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS