论文解读NAACL 2021 对比自监督学习的上下文和一般句子表征:以篇章关系分析为例
Posted 刘炫320
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读NAACL 2021 对比自监督学习的上下文和一般句子表征:以篇章关系分析为例相关的知识,希望对你有一定的参考价值。
前言
本文是NAACL 2021的论文《Contextualized and Generalized Sentence Representations by Contrastive Self-Supervised Learning: A Case Study on Discourse Relation Analysis》的解读。
总体说来整篇文章的结构还是比较清晰。利用RoBERTa作为基底模型,附带一个对比学习目标和一个生成目标。在普通的掩码语言任务中增加了句子级别的自监督对比损失,使得掩码的表示在同一上下文中尽可能的与目标句一致且尽可能与与随机句不一致。然后,生成器再自回归生成掩码句。最后实验结果在篇章关系分析任务上取得不错的效果。
摘要
我们提出一个通过对比自监督学习的方法学习一种上下文和一般化的句子表示方法。在提出的方法中,模型的输入是由多个句子组成的文本。一个句子被随机的选中作为目标句。模型被通过训练最大化目标句与掩码句在相同上下文下的相似性。同时,模型也会被最小化掩码句与随机替换句在相同语境下的相似性。我们应用我们的模型在英语和日语的篇章关系分析中并且实验结果显示我们的模型战胜了强基准系统BERT,XLNET和RoBERTa.
1. 引言
理解句子语义是自然语言处理的主要研究点之一。最近几年,分布式向量表示被认为是促进了灵活捕获句子语义。
一个获取分布式句子表示的典型方法是学习一个与句子语义相关的任务。例如,通过自然语言推理来训练句子表示,这种方法被认为是有助于许多自然语言理解任务,如情感分析,语义相似度计算等。
然而,用于训练的任务都比较随意。而且,受限于人工标注数据的大小,很难学习到一个语言的普遍表示。
一种解决方法是自监督学习,其取得了巨大的成功。例如,受到Skip-grams的启发,Kiros等人提出通过生成句子之前和之后的句子来计算句子的表示。受到掩码语言模型的启发,Zhang等人和Huang等人提出学习上下文化的句子表示通过从上下文中回复被掩盖的句子。
在自监督的句子表示学习中,句子的生成通常是被认为是其学习目标。这样一个学习目标能够足够的去还原其句子,包括微小的细节。另一方面,我们想要表示更大的文本快的语义如段落或者文章并且将句子看做是一个基本单元,更加抽象和一般化的句子表示可能更加有用。
我们提出一种通过对比自监督学习的方法学习上下文化和一般化的句子表示的方法。在提出的方法中,模型的蔬菜如被认为是给定一个包含多个句子的文本,计算它们的上下文的句子表示。通过训练,一个句子被随机的选取为目标句。模型被训练为最大化目标句和掩码句的相似性,在同一个上下文下。同时,模型也被训练为最小化随机句和掩码句的相似性,在同一个上下文下。
从优化 s a n c s_{anc} sanc的角度,这可以被看做是一个通过上下文捕获一般化句子表示的任务,以 s p o s s_{pos} spos和 s n e g s_{neg} sneg为线索。从优化 s p o s s_{pos} spos的角度看,这可以被看做是在一般化一个句子的表示在 s a n c s_{anc} sanc层面。
我们展示我们提出模型的有效性利用上下文分析中的典型任务,篇章关系分析任务。我们在英语和日语上的数据集显示我们的模型优于BERT,XLNet和RoBERTa等强基准模型。
2. 学习上下文句子表示
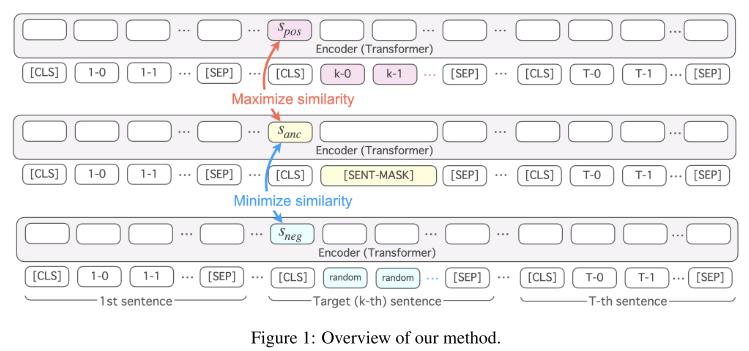
图1 是我们模型的整体框架示意图。
2.1 编码器
在编码器我们只使用了和BERT一样的模型,在输入的时候对于每个句子都使用和包裹起来,并且使用作为句子的表示。
2.2 对比学习目标
我们提出对比学习目标来学习句子的表示用于捕获句子一般化语义。我们首先随机选择一个句子作为目标句。然后我们创建一个目标句的掩码句。最后我们使用随机句子替换目标句。
我们的对比学习目标是最大化正例句与掩码句之间的语义相似度同时最小化负例与掩码句之间的语义相似度。
其损失函数如下:

2.3 生成目标
生成目标就是生成mask掩码。和常规的encoder-decoder差不多。并且使用teacher forcing方式来增强学习效果。
2.4 实现细节
英语上采用Wikipedia和Bookcorpus。每个句子保证最长128,输入平均4.91个句子,负采样3个。
使用robertabase作为参数权重初始化。
日遇上采用日语的Wikipedia,平均每个输入有6.42个句子。
3. 篇章关系分析
我们展示了我们的模型在篇章关系分析上的有效性。篇章关系分析是一个上下文分析很好的例子。篇章关系分析是用来预测两个论元之间的逻辑关系。一个论元可以大致的认为是一个句子或者短语。我们在英语和日语数据集上都进行了实验。
3.1 数据集
3.1.1 宾州篇章树库(PDTB 3.0)
该论文使用了最新版本的PDTB 3.0的语料作为篇章关系识别的语料。而且参考的是Kim 2020的实验设置。
3.1.2 京都大学网络文档摘要语料库(KWDLC)
KWDLC是一个日语语料库,每个文档都有3句导语以及其间的篇章关系标签。由于KWDLC没有区分显式篇章关系和隐式篇章关系,因此所有关系都被选取。该语料库共包含包括没有关系的7个类型的篇章关系。同样采用5被交叉验证的方法。
3.2 模型
我们训练了两种类型模型,一种包含了论元的上下文的,一种没有包含论元的上下文。
当一个模型使用了上下文时,我们的模型会把包含论元的段落作为上下文。并且把论元看做是一个句子,其他的部分也是根据句子划分。然后编码完这些句子后,选取论元的CLS表示拼接起来,用于篇章关系分类。篇章关系分类模型是一个多层感知机,有一层隐藏层和一个ReLU激活函数。
当模型没有使用上下文时,就是普通的关系分类模型。就像BERT一样。我们提出的模型使用了不同的参数初始化,因此存在性能差异。
3.3 实现细节
最长512输入,训练了20轮。每一轮都在验证集上挑选出最好的模型。如果模型在5回合内没有性能提升,我们就会停止训练。使用了2e-5的学习率的Adam,也更新了所有的模型参数。
3.4 实验结果
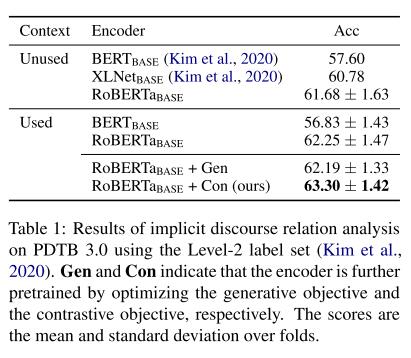
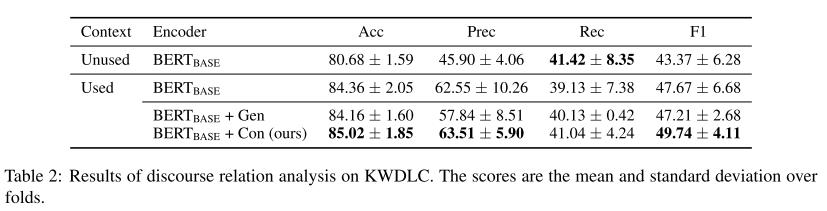
实验结果如表所示。
3.5 样例分析
此处省略。
4.句子抽取
为了探寻我们的对比学习目标学习到了什么,我们做了基于句子相似度抽取的实验。从Wiki上的查询语句查询到的排名靠前的结果的话题、语义和上下文都是和查询句比较相似的,而排名靠后的则意义相反。

5.总结
本文提出一个通过对比自监督训练学习上下文和一般句子表示。实验结果显示提出的方法能够改善在英语和日语上的篇章关系分析的性能。我们也为未来工作对提出的模型进行了深入的分析。
个人小结
个人评价,本文是将上下文和对比学习两者结合用于篇章关系识别上的一个尝试。有一定的创新点,在性能和分析上也证明了其有效性。唯一的缺陷就是方法是常用的对比学习方法,在RoBERTa等上面也用过类似的,而且也不是真正意义上的对比学习,最后性能提升确实有限。更多的提升来源于上下文带来更多的信息。不过作为NAACL的短文,已经可以被接收。
以上是关于论文解读NAACL 2021 对比自监督学习的上下文和一般句子表征:以篇章关系分析为例的主要内容,如果未能解决你的问题,请参考以下文章