simCSE:论文解读
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了simCSE:论文解读相关的知识,希望对你有一定的参考价值。
参考技术A本文介绍了一个简单的对比学习框架SimCSE,它极大地促进了最先进的句子嵌入。首先描述了一种无监督的方法,它接受一个输入句子,然后在对比目标中预测自己,并 只有标准的dropout用作噪声 。
这个简单的方法令人惊讶。发现,dropout充当了最小的数据扩充,移除它会导致数据表示不好。然后,我们提出了一种有监督的方法,它将自然语言推理数据集中的注释对纳入我们的对比学习框架中,使用“蕴涵”对作为正例,使用“矛盾”对作为硬负例。
在标准语义文本相似性(STS)任务中评估SimCSE,以及使用BERT-base的无监督和监督模型分别实现了76.3%和81.6%的斯皮尔曼相关性,与之前的最佳结果相比,分别提高了4.2%和2.2%。我们也展示了两者从理论和经验上来看, 对比学习目标将预先训练好的嵌入的各向异性空间规整得更加均匀,并且在有监督信号的情况下更好地对齐正对 。
学习通用句子嵌入是自然语言处理中的一个基本问题,在文献中得到了广泛的研究。在这项工作中,我们提出了最先进的句子嵌入方法,并证明了对比目标在以下情况下是非常有效的:再加上预先训练过的语言模型,如BERT或RoBERTa
。我们介绍了 SimCSE,一种简单的对比语言句子嵌入框架,可以从未标记或标记的数据中生成更好的句子嵌入 。
○ 1、无监督SimCSE:
○ 2、有监督SimCSE:
我们对七项标准语义文本相似性(STS)任务和七项转移任务中对SimCSE进行了综合评估。在STS任务中,我们的无监督模型和监督模型分别达到76.3%和81.6%的平均斯皮尔曼相关,与之前的最佳结果相比,分别提高了4.2%和2.2%。在转移任务上也取得了有竞争力的表现。
最后,我们在文献和研究中发现了一个不连贯的评估问题整合不同设置的结果,以便将来评估句子嵌入。
其中xi 和x+i是语义相关的。我们遵循对比框架,采用一个具有批量负例的叉熵目标:让 hi 和 hi+ 表示 xi 和 xi + 的表示,即训练目标。对于(xi,xi+)和小批量的N对是:
where xi and x+i are semantically related. We follow the contrastive framework
in Chen et al. (2020) and take a cross-entropy objective with in-batch negatives (Chen et al., 2017;Henderson et al., 2017): let hi and h + i denote the representations of xi and x + i, the training objective
for (xi, x+i) with a mini-batch of N pairs is:
其中 τ是一个温度超参数sim(h1,h2)是余弦相似性
在这项工作中,我们使用预训练的语言模型,如BERT或RoBERTa:h=fθ(x),然后微调所有参数使用对比学习目标(等式1)。
对比学习中的一个关键问题是如何构建 (xi, xi+)对。在视觉表现中,一个有效的解决方案是对同一幅图像进行两次随机变换(例如,裁剪、翻转、变形和旋转)如xi 和 xi+。最近,在语言表达中也采用了类似的方法,方法是应用增广技术,如单词删除、重新排序和替换。然而,由于NLP的离散性,NLP中的数据扩充本质上是困难的。我们将在§3中看到。简单地在中间表示上使用标准Dropout比这些离散操作符表现得更好。
在NLP中,类似的对比学习目标在不同的背景下进行了探索。 在这些情况下, (xi, xi+)收集自有监督的数据集,如问题-段落对。由于xi和xi+的明显性质,这些方法总是使用双编码器框架, 例如,对于xi和xi+使用两个独立的编码器fθ1和fθ2。
对于句子嵌入,Logeswaran和Lee(2018)也使用了对比学习和双编码器方法,将当前句子和下一个句子组成为(xi,xi+)。
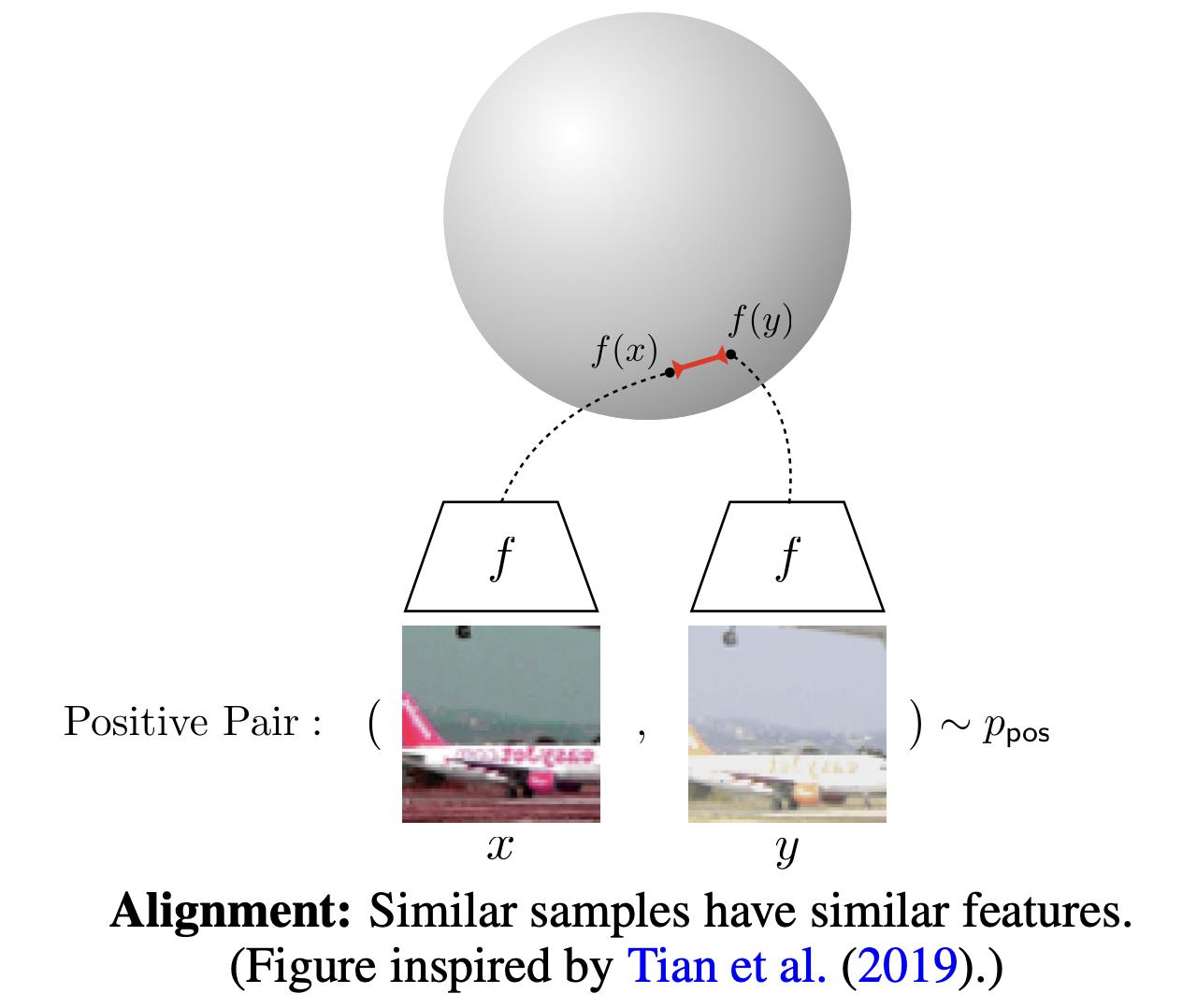
最近,Wang和Isola(2020)确定了与对比学习的对齐性alignment和一致性uniformity——并建议使用它们来衡量表达的质量。给出了一个正例对分布ppos,alignment计算成对实例的嵌入之间的预期距离(假设表示已经规范化):
另一方面,一致性uniformity衡量的是嵌入物均匀分布效果:
其中pdata表示数据分布。 这两个指标与对比学习的目标非常一致 :正例之间应该保持紧密,而随机实例的嵌入应该分散在超球体上。在接下来的部分中,我们还将使用这两个指标来证明我们的方法的内部工作原理。
使用 xi+=xi。关键的成分是让这个通过使用独立取样的dropout masks 对 xi 和 xi+进行相同的正例对操作。
其中z是dropout的随机掩码。我们只是将相同的输入进行编码器两次,并获得两个具有不同dropout masksz、z0的嵌入, SimCSE的训练目标是:
我们将其视为数据扩充的一种最小形式:正例对的句子完全相同它们的嵌入只在Dropout mask上有所不同。我们将这种方法与STS-B开发集上的其他训练目标进行比较。
表1将我们的数据增强技术方法与普通方法进行了比较:如crop、word删除和替换,可以看作是 h = fθ(g(x),z),而g是x上的(随机)离散算子。注意到,即使删除一个单词会影响性能,但没有任何影响到增强效果优于dropout噪声。
我们还将self-prediction训练目标与使用的next-sentence目标进行了比较,选择其中一个或者两个独立的编码器。如表2所示,发现SimCSE比next-sentence目标的表现要好得多,并且使用一个编码器而不是两个编码器在我们的方法中有显著差异。
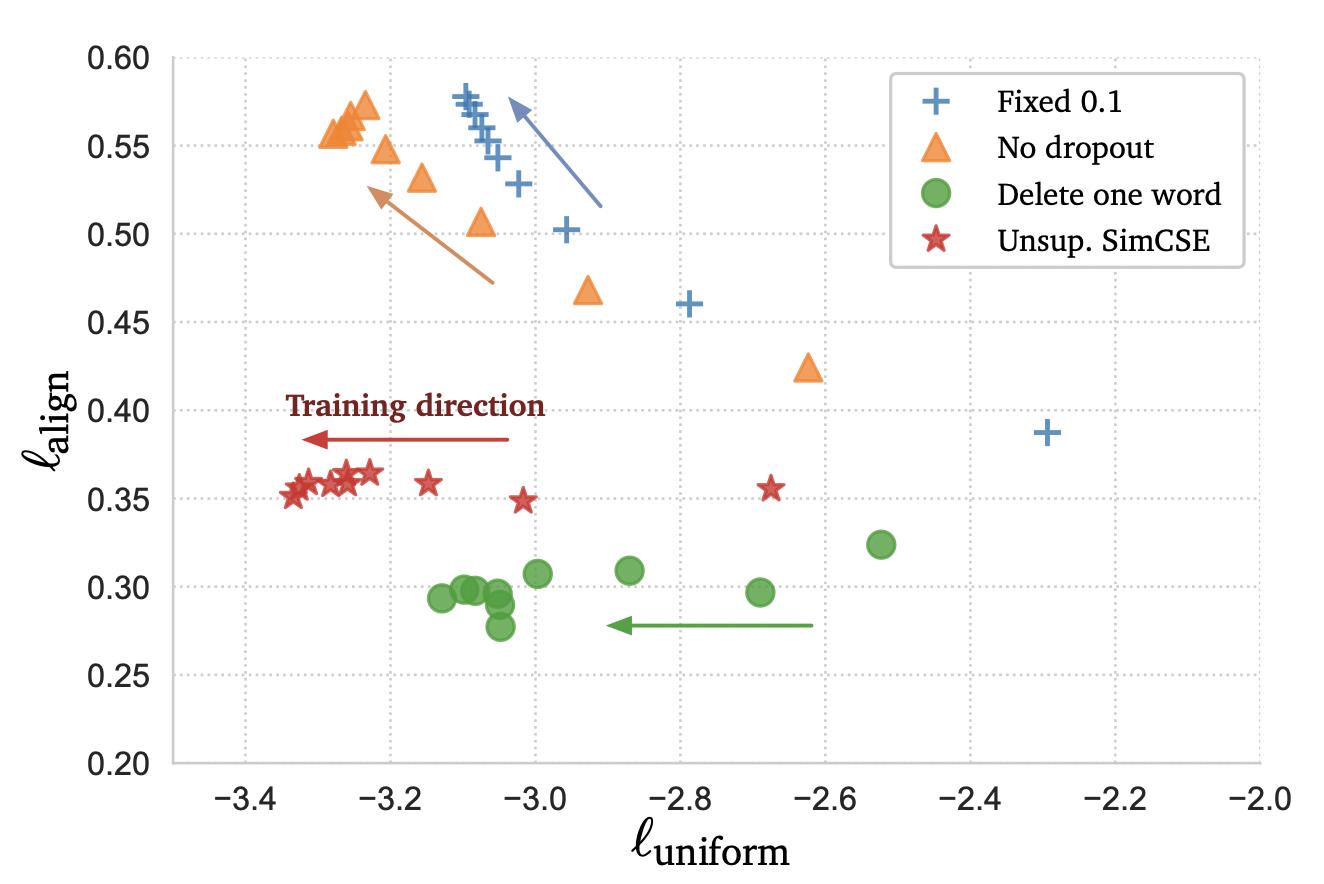
为了进一步了解dropout noise在无监督SimCSE中的作用,我们在表3中尝试了不同的 dropout rates,并观察到所有变体都低于Transformers的默认dropout概率p=0.1。
我们发现两个极端情况特别有趣:
在测试过程中,我们每10步对这些模型进行一次检查训练并可视化对齐alignment和一致性uniformity度量在Figure 2中,还有一个简单的数据扩充模型“删除一个单词”。如图所示,从预先训练好的检查点开始,所有模型都大大提高了一致性uniformity。
然而,这两种特殊变体的排列也会退化由于使用了dropout噪声,我们的无监督SimCSE保持了稳定的对齐alignment。它还表明,从预训练的检查点开始是至关重要的,因为它提供了良好的初始对齐alignment。最后,“删除一个单词”改善了对齐,但在一致性度量上获得了较小的增益,最终表现不如无监督SimCSE。
我们已经证明,添加dropout 噪声能够保持正例对的良好对齐(x,x+)~Ppos。
在本节中,将研究是否可以利用有监督的数据集来提供更好的训练信号,以改进方法的一致性。
之前的研究表明,有监督的自然语言推理(NLI)数据集通过预测两个句子之间的关系是包含关系、中性关系还是矛盾关系,有效地学习句子嵌入。在我们的对比学习框架中,直接从监督数据集中提取(xi,xi+)对,并使用它们优化等式1。
我们首先探索哪些监督数据集特别适合于构造正例对(xi,xi+)。我们用大量数据集和句子对样例进行了实验,包括:
最后,我们进一步利用NLI数据集,将其矛盾对作为负例对。
在NLI数据集中,给定一个前提,注释者需要手动编写一个绝对正确(蕴涵)、一个可能正确(中立)和一个绝对错误(矛盾)的句子。因此,对于每个前提及其蕴涵假设,都有一个伴随的矛盾假设(示例见图1)。
形式上我们扩展(xi,xi+)为(xi,xi+,xi-),其中xi是前提,xi+ 和 xi−是蕴涵假设和矛盾假设。然后,通过(N是最小批量)定义训练目标Li。
如表4所示,添加负例对可以进一步提高性能(84.9→ 86.2)这是最终有监督SimCSE。也试过了添加ANLI数据集或将其与无监督SimCSE方法相结合,但没有发现有意义的改进。我们也在有监督的SimCSE中考虑了双编码器框架,它损害了性能(86.2→ 84.2)。
最近的研究发现了一个 各向异性 问题语言表达,即学习到的嵌入占据了向量空间中的窄锥限制了他们的表达能力。
证明语言模型经过了捆绑训练输入/输出嵌入导致单词各向异性嵌入,在预先训练的上下文表示中进一步观察到了这一点。证明奇异值语言模型中单词嵌入矩阵的构造急剧衰减:除了少数占主导地位的奇异值,所有其他值都接近于零。
(1)缓解问题的一个简单方法是后处理,要么消除主要主成分,要么将嵌入映射到各向同性分布 。
(2)另一个常见的解决方案是在训练期间增加正则化。在这项工作中,我们从理论和经验上证明,对比目标也可以缓解各向异性问题。
各向异性问题自然与均匀性有关,两者都强调了 嵌入应均匀分布在空间中 。直观地说,随着目标的推进,优化对比学习目标可以提高一致性(或缓解各向异性问题)把负例分开。在这里,我们采用单一光谱的观点,这是一种常见的做法。在这里,我们从单数光谱的角度来分析单词嵌入,以及 表明对比目标可以“压平”目标句子嵌入的奇异值分布并使表示更加各向同性 。
继Wang和Isola,对比学习目标(等式1)的渐近性可以用以下等式表示:负例的数量接近无穷大(假设 f(x) 被归一化):
与后处理方法相比 。其目的仅在于鼓励各向同性表征,对比学习还优化了通过方程式6中的第一个term,这是SimCSE成功的关键。第7节给出了定量分析。
我们在7个语义文本上进行了实验相似性(STS)任务。请注意,所有的STS实验都是完全无监督的,没有使用STS训练集。
即使对于有监督的SimCSE,也只是说,在之前的工作之后,需要额外的标记数据集进行训练。还评估了7项迁移学习任务,并在附录E中提供了详细结果。我们与Reimers和Gurevych(2019)持有类似的观点, 即句子嵌入的主要目标是对语义相似的句子进行聚类 ,因此将STS作为主要结果。
我们评估了7项STS任务:2012-2016年STS,STS基准(Cer等人,2017年)和疾病相关性(Marelli等人,2014年)。当与之前的工作进行比较时,我们在评估设置中确定了已发表论文中的无效比较模式,包括(a)是否使用额外的回归系数,(b)斯皮尔曼与皮尔逊的相关性,以及(c)如何汇总结果(表B.1)。
我们比较了无监督和有监督的SimCSE与以前SOTA的STS任务句子嵌入方法。无监督基线包括平均GloVe嵌入、平均BERT或RoBERTa嵌入,以及后处理方法,如BERT - flow和BERT-whitening。
我们还比较了最近使用 对比目标的几种方法,包括:
(1)IS-BERT),它最大限度地实现了global和local features 之间的一致性;
(2) DeCLUTR,将同一文档中的不同spans作为正例对;
(3) CT,它将来自两个不同的编码器的同一句子进行嵌入对齐。
表5显示了7项STS任务的评估结果。无论是否有额外的NLI监督,SimCSE都能显著改善所有数据集的结果,大大优于之前最先进的模型。具体而言,我们的无监督SimCSE-BERT-base将之前的SOTA平均Spearman相关性从72.05%提高到76.25%,甚至与有监督baselines相当。
在使用NLI数据集时,SimCSE-BERTbase进一步将SOTA结果提高到81.57%。RoBERTa编码器的收获更为明显,我们的有监督SimCSE通过RoBERT-alarge实现了83.76%
在附录E中,我们展示了SimCSE与现有工作相比达到PAR或更好的传输任务性能,还有一个辅助MLM目标可以进一步提高性能。
我们调查了不同的pooling方法和硬负例的影响。本节中所有报告的结果均基于STS-B开发集。我们在附录D中提供了更多的消融研究(标准化、温度和MLM目标)。
Reimers和Gurevych等人表明,采用预训练模型的平均嵌入(尤其是从第一层和最后一层)比 [CLS]具有更好的性能 。
表6显示了无监督和有监督SimCSE中不同池化方法之间的比较。对于[CLS]表示,原始的BERT实现需要在其上附加一个MLP层。
(1)保持MLP层;
(2) 无MLP层;
(3) 在训练期间保留MLP,但在测试时移除。
硬负例。直觉上,这可能是有益的区分硬负例(矛盾示例)和其他批量负例。因此,我们扩展等式5中定义的训练目标,以纳入不同负例的权重:
我们用不同的α值对SimCSE进行训练,并对训练后的模型进行评估STS-B的开发集,也考虑中性假设作为硬负例。如表7所示,α=1表现最好,且中性假设不会带来进一步的收益。
在本节中,我们将进一步分析,以了解SimCSE的内部工作原理。
图3显示了不同句子嵌入模型的一致性uniformity和对齐性alignment,以及它们的平均STS结果。 总的来说,具有更好的对齐和一致性的模型可以获得更好的性能 。
○ 在附录F中,进一步证明了SimCSE可以有效地均匀预训练嵌入的奇异值分布。
○ 在附录G中,我们展示了SimCSE在不同的句子对之间提供了更可区分的余弦相似性。
我们使用SBERTbase和SimCSE-BERTbase进行了小规模检索实验。使用来自Flickr30k数据集,并将任意随机句子作为检索类似句子的查询(基于余弦)相似性)。如表8所示的几个例子,SimCSE检索到的句子与SBERT检索到的质量进行比较具有较高的识别率。
句子嵌入早期建立在分布假设的基础上,通过预测给定句子的周围句子。表明,简单地用n-gram嵌入来增强word2vec的概念会产生很好的结果。最近的几种方法从数据扩充或同一句话的不同版本或文件采用了对比目标。与这些工作相比,
我们感谢Tao Lei, Jason Lee, Zhengyan Zhang, Jinhyuk Lee, Alexander Wettig, Zexuan Zhong,普林斯顿NLP小组的成员有益的讨论和宝贵的反馈。这项研究得到了哈佛大学研究生奖学金的支持普林斯顿大学和苹果公司的礼物奖。
恒源云_[SimCSE]:对比学习,只需要 Dropout?
文章来源 | 恒源云社区(恒源云,专注 AI 行业的共享算力平台)
原文地址 | Dropout
原文作者 | Mathor
要说2021年上半年NLP最火的论文,想必非《SimCSE: Simple Contrastive Learning of Sentence Embeddings》莫属。SimCSE的全称是Simple Contrastive Sentence Embedding
Sentence Embedding
Sentence Embedding一直是NLP领域的一个热门问题,主要是因为其应用范围比较广泛,而且作为很多任务的基石。获取句向量的方法有很多,常见的有直接将[CLS]位置的输出当做句向量,或者是对所有单词的输出求和、求平均等。但以上方法均被证明存在各向异性(Anisotropy)问题。通俗来讲就是模型训练过程中会产生Word Embedding各维度表征不一致的问题,从而使得获得的句向量也无法直接比较
目前比较流行解决这一问题的方法有:
- 线性变换:BERT-flow、BERT-Whitening。这两者更像是后处理,通过对BERT提取的句向量进行某些变换,从而缓解各向异性问题
- 对比学习:SimCSE。 对比学习的思想是拉近相似的样本,推开不相似的样本,从而提升模型的句子表示能力
Unsupervised SimCSE

SimCSE利用自监督学习来提升句子的表示能力。由于SimCSE没有标签数据(无监督),所以把每个句子本身视为相似句子。说白了,本质上就是
(
自
己
,
自
己
)
(自己,自己)
(自己,自己)作为正例、
(
自
己
,
别
人
)
(自己,别人)
(自己,别人)作为负例来训练对比学习模型。当然,其实远没有这么简单,如果仅仅只是完全相同的两个样本作正例,那么泛化能力会大打折扣。一般来说,我们会使用一些数据扩增手段,让正例的两个样本有所差异,但是在NLP中如何做数据扩增本身也是一个问题,SimCSE提出了一个极为简单优雅的方案:直接把Dropout当做数据扩增!
具体来说,
N
N
N个句子经过带Dropout的Encoder得到向量
h
1
(
0
)
,
h
2
(
0
)
,
…
,
h
N
(
0
)
\\boldsymbolh_1^(0),\\boldsymbolh_2^(0),…,\\boldsymbolh_N^(0)
h1(0),h2(0),…,hN(0),然后让这批句子再重新过一遍Encoder(这时候是另一个随机Dropout)得到向量
h
1
(
1
)
,
h
2
(
1
)
,
…
,
h
N
(
1
)
\\boldsymbolh_1^(1),\\boldsymbolh_2^(1),…,\\boldsymbolh_N^(1)
h1(1),h2(1),…,hN(1) ,我们可以
(
h
i
(
0
)
,
h
i
(
1
)
)
(\\boldsymbolh_i^(0),\\boldsymbolh_i^(1))
(hi(0),hi(1))视为一对(略有不同的)正例,那么训练目标为

其中,
sim
(
h
1
,
h
2
)
=
h
1
T
h
2
∥
h
1
∥
⋅
∥
h
2
∥
\\textsim(\\boldsymbolh_1, \\boldsymbolh_2)=\\frac\\boldsymbolh_1^T\\boldsymbolh_2\\Vert \\boldsymbolh_1\\Vert \\cdot \\Vert \\boldsymbolh_2\\Vert
sim(h1,h2)=∥h1∥⋅∥h2∥h1Th2。实际上式(1)如果不看
−
log
-\\log
−log和
τ
\\tau
τ的部分,剩下的部分非常像是
Softmax
\\textSoftmax
Softmax。论文中设定
τ
=
0.05
\\tau = 0.05
τ=0.05,至于这个
τ
\\tau
τ有什么作用,我在网上看到一些解释:
- 如果直接使用余弦相似度作为logits输入到 Softmax \\textSoftmax Softmax,由于余弦相似度的值域是 [ − 1 , 1 ] [-1,1] [−1,1],范围太小导致 Softmax \\textSoftmax Softmax无法对正负样本给出足够大的差距,最终结果就是模型训练不充分,因此需要进行修正,除以一个足够小的参数 τ \\tau τ将值进行放大
- 超参数 τ \\tau τ会将模型更新的重点,聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与 h i ( 0 ) h_i^(0) hi(0)距离越近,则分配到的惩罚越多。其实这也比较好理解,我们将 sim ( h i ( 0 ) , h j ( 1 ) ) \\textsim(\\boldsymbolh_i^(0),\\boldsymbolh_j^(1)) sim(hi(0),hj(1))除以 τ \\tau τ相当于同比放大了负样本的logits值,如果 τ \\tau τ足够小,那么那些 sim ( h i ( 0 ) , h j ( 1 ) ) \\textsim(\\boldsymbolh_i^(0),\\boldsymbolh_j^(1)) sim(hi(0),hj(1))越靠近1的负样本,经过 τ \\tau τ的放大后会占主导
个人觉得没有严格的数学证明,单从感性的角度去思考一个式子或者一个符号的意义是不够的,因此在查阅了一些资料后我将 τ \\tau τ这个超参数的作用整理成了另一篇文章:Contrastive Loss中参数 τ \\tau τ的理解
总结一下SimCSE的方法,个人感觉实在是太巧妙了,因为给两个句子让人类来判断是否相似,这其实非常主观,例如:“我喜欢北京”跟“我不喜欢北京”,请问这两句话到底相不相似?模型就像是一个刚出生的孩子,你教它这两个句子相似,那它就认为相似,你教它不相似,于是它以后见到类似的句子就认为不相似。此时,模型的性能或者准确度与训练过程、模型结构等都没有太大关系,真正影响模型预测结果的是人,或者说是人标注的数据
但是如果你问任何一个人“我喜欢北京”跟“我喜欢北京”这两句话相不相似,我想正常人没有说不相似的。SimCSE通过Dropout生成正样本的方法可以看作是数据扩增的最小形式,因为原句子和生成的句子语义是完全一致的,只是生成的Embedding不同而已。这样做避免了人为标注数据,或者说此时的样本非常客观
Alignment and Uniformity
对比学习的目标是从数据中学习到一个优质的语义表示空间,那么如何评价这个表示空间的质量呢?Wang and Isola(2020)提出了衡量对比学习质量的两个指标:alignment和uniformity,其中alignment计算
x
i
x_i
xi和
x
i
+
x_i^+
xi+的平均距离:
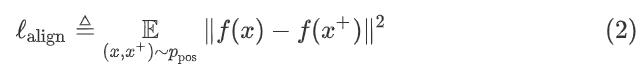
而uniformity计算向量整体分布的均匀程度:
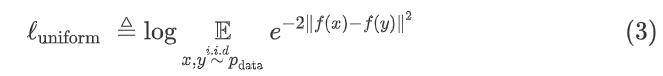

我们希望这两个指标都尽可能低,也就是一方面希望正样本要挨得足够近,另一方面语义向量要尽可能地均匀分布在超球面上,因为均匀分布的信息熵最高,分布越均匀则信息保留的越多。作者从维基百科中随机抽取十万条句子来微调BERT,并在STS-B dev上进行测试,实验结果如下表所示:
其中None是作者提出的随机Dropout方法,其余方法均是在None的基础上对
x
i
+
x_i^+
xi+进行改变,可以看到,追加显式数据扩增方法均会不同程度降低模型性能,效果最接近Dropout的是删除一个单词,但是删除一个单词并不能对uniformity带来很大的提升,作者也专门做了个实验来证明,如下图所示:
Connection to Anisotropy
近几年不少研究都提到了语言模型生成的语义向量分布存在各向异性的问题,在探讨为什么Contrastive Learning可以解决词向量各向异性问题前,我们先来了解一下,什么叫各向异性。具体来说,假设我们的词向量设置为2维,如果各个维度上的基向量单位长度不一样,就是各向异性(Anisotropy)
例如下图中,基向量是非正交的,且各向异性(单位长度不相等),计算
x
1
x
x_1x
x1x与
x
2
x_2
x2的cos相似度为0,
x
1
x_1
x1与
x
3
x_3
x3的余弦相似度也为0。但是我们从几何角度上看,
x
1
x_1
x1与
x
3
x_3
x3其实是更相似的,可是从计算结果上看,
x
1
x_1
x1与
x
2
x_2
x2和
x
3
x_3
x3的相似度是相同的,这种不正常的原因即是各向异性造成的

SimCSE的作者证明了当负样本数量趋于无穷大时,对比学习的训练目标可以渐近表示为:

稍微解释一下这个式子,为了方便起见,接下来将 1 τ E ( x , x + ) ∼ p pos [ f ( x ) T f ( x + ) ] \\frac1\\tau\\mathop\\mathbbE\\limits_(x,x^+)\\sim p_\\textpos\\left[f(x)^Tf(x^+)\\right] τ1(x,x+)∼pposE[f(x)Tf(x+)]称为第一项, E x ∼ p data [ log E x − ∼ p data [ e f ( x ) T f ( x − ) / τ ] ] \\mathop\\mathbbE\\limits_x\\sim p_\\textdata\\left[\\log \\mathop\\mathbbE\\limits_x^-\\sim p_\\textdata\\left[e^f(x)^Tf(x^-)/\\tau\\right]\\right] x∼pdataE[log以上是关于simCSE:论文解读的主要内容,如果未能解决你的问题,请参考以下文章