论文解读丨无参数的注意力模块SimAm
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读丨无参数的注意力模块SimAm相关的知识,希望对你有一定的参考价值。
摘要:本文提出了一个概念简单但对卷积神经网络非常有效的注意力模块。
本文分享自华为云社区《论文解读系列三十:无参数的注意力模块SimAm论文解读》,作者:谷雨润一麦。

摘要
本文提出了一个概念简单但对卷积神经网络非常有效的注意力模块。相比于现有的通道注意力和空间注意力机制,本文直接在网络层中推理出三维的注意力权重而且不增加任何参数量。确切地来说,本文基于著名的神经科学理论提出了通过优化能量函数来查找每个神经元的重要性。本文通过求解能量函数解析解的方式,进一步将代码实现控制在十行以内。SimAm模的另一个优势是大多数操作都是基于定义的能量函数的解决方案,因此不需要花太多的精力做结构调整。在各个视觉任务上的定量实验都表明本文提出的模块在改善卷积网络的表征能力上具有灵活性和有效性。
动机
现有的注意力基础模块存在两个问题。一个是他们只能在通道或者空间维度中的一个维度对特征进行精炼,但在空间和通道同时变化的空间缺乏灵活性。第二是他们的结构往往需要基于一系列的复杂操作,例如池化。文本基于完善的神经科学理论提出的模块很好的解决了上述两个问题。具体来说,为了让网络学习到更具区分性的神经元,本文提出直接从当前的神经元推理出三维的权重,然后反过来去优化这些神经元。为了有效的推理出三维的权重,本文基于神经科学的知识定义了一个能量函数,然后获得了该函数的解析解。
方法
在神经科学中,信息丰富的神经元通常表现出与周围神经元不同的放电模式。而且,激活神经元通常会抑制周围神经元,即空域抑制。换句话说,展现出空域抑制效应的神经元在视觉处理任务中应该被赋予更高的重要性。最简单的寻找重要神经元的方法就是度量神经元之间的线性可分性。基于这些神经科学的发现,本文针对每个神经元定义了如下的能量函数:

其中,$\\hat t=w_t t+b_t, \\hat x_i=w_t x_i + b_t$是$t$和$x_i$的线性变换,$t$和$x_i$是输入特征$\\textbfX\\in \\mathbbR^C\\times H\\times W$的单通道中的目标神经元和其他神经元。$i$是在空间维度上的索引,$M=H\\times M$是一个通道上的神经元的数量。$w_t$和$b_t$是线性变换的权重和偏置。式(1)中的所有值都是标量。当$\\hat t=y_t$并且对其他说有神经元都有$\\hat x_i =y_o$时,式(1)得到最小值,其中$y_t$和$y_o$是两个不同的值。最小化公式(1)等价于找到同一通道内目标神经元$t$和其他神经元的线性可分性。为简单起见,本文采用二值标签并添加正则项。最终的能量函数如下式:

理论上,每个通道都会有$M$个这样能量函数,如果用像SGD这样的梯度下降算法去求解这些等式的话,计算开销将会非常大。幸运地是,等式(2)中$w_t$和$b_t$都可以快速求得解析解,如下式所示:
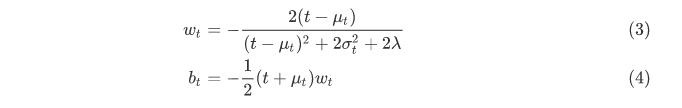
其中$u_t=\\frac1M-1\\sumi=1^M-1x_i$和$\\sigma_t^2=\\frac1M-1\\sumi^M-1(s_i-\\mu_t)^2$是对应通道中出去神经元$t$后所有神经元的均值和方差。从公式(3)和公式(4)可以看出解析解都是在单通道上得到的,因此可以合理的推测同一个通道的其他神经元也满足相同的分布。基于这个假设,就可以在所有神经元上计算均值和方差,在同一通道上的所有神经元都可以复用这个均值和方差。因此可以大大减少每个位置重复计算$\\mu$和$\\sigma$的开销,最终每个位置的最小能量可以通过下式得到:

其中$\\mu=\\frac1M\\sumi=1^Mx_i$和$\\hat\\sigma^2=\\frac1M\\sumi=1^M(x_i-\\hat\\mu)^2$。等式(5)说明,能量$e_t^$越低,神经元$t$和周围神经元的区别越大,在视觉处理中也越重要。因此,本文通过$1/e_t^$来表示每个神经元的重要性。根据Hillard等人<sup>1</sup>的研究,哺乳动物大脑中的注意力调节通常表现为对神经元反应的增益效应。因此本文直接用了缩放而不是相加的操作来做特征提炼,整个模块的提炼过程如下:

其中$\\Epsilon$是$e_t^*$在所有通道和空间维度的汇总,$sigmoid$是用来约束过大的值,它不会影响每个神经元的相对大小,因为它是一个单调函数。
实际上除了计算每个通道的均值和方差外,其他所有的操作都是元素级别点对点的操作 。因此利用Pytorch可以几行代码实现公式(6)的功能,如图一所示。

图一 SimAM的pytorch风格实现
实验
CIFAR 分类实验
在CIFAR 10类数据和100类数据上分别做了实验,并和其他四中注意力机制进行了对比,本文提出的模块在不增加任何参数的情况下在多个模型上都表现出了优越性,实验结果如图二所示。
图二 五种不同的注意力模块在不同模型上CIFAR图像分类任务上的top-1准确率
[1]: Hillyard, S. A., Vogel, E. K., and Luck, S. J. Sensory Gain Control (Amplification) as a Mechanism of Selective Attention: Electrophysiological and Neuroimaging evidence. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, 353(1373): 1257–1270, 1998.
以上是关于论文解读丨无参数的注意力模块SimAm的主要内容,如果未能解决你的问题,请参考以下文章
bert系列一:《Attention is all you need》论文解读
论文解读:Attention Is All You Need
论文解读 用于弱监督表面缺陷分割的缺陷注意模板循环对抗网络 (Defect attention template generation cycleGAN for weakly supervised)