大道至简,何恺明最新一作火了:让计算机觉视觉通向大模型!
Posted Wang_AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大道至简,何恺明最新一作火了:让计算机觉视觉通向大模型!相关的知识,希望对你有一定的参考价值。
何恺明,清华大学本科,港中文博士
kaggle竞赛宝典
作者:何恺明,文章摘自Datawhale
让计算机觉视觉通向大模型!
来源 | 知乎,MLNLP编辑
https://www.zhihu.com/question/498364155
原问题:如何看待何恺明最新一作论文Masked Autoencoders?
论文链接:https://arxiv.org/pdf/2111.06377.pdf
01
回答一:作者-田永龙
我一般判断看一篇方法类文章将来是否有影响力从下面三个角度(重要程度依次递减)
(1) 惊人程度,Surprise
研究的目的就是探索前人不知道的知识,挖掘新的信息。我认为MAE在这点上很棒,它告诉了我直接reconstruct image原图也可以做到很work,这改变了我们绝大多数人的认知(之前iGPT没有很work; 其他答案提的BEIT也并不是reconstruct原图,而是reconstruct feature)。
在NLP reconstruct效果很好是因为文字本身就是highly semantic,所以模型预测的目标信息量大,而噪音小; 图片相比而言语意信息密度低,如果模型要完全预测对目标的话就要浪费capacity去model那些不重要的玩意儿。因此我一直觉得reconstruction这个学习目标不太对。
但这篇文章似乎是换了种方式来解决这个问题(个人偏见),就是压根就没想让模型完全恢复原图,MAE只输入很少的patch,那无论如何也恢复不了原图。同时我们都知道,相比高频信号而言,神经网络更擅长抓住低频的信号。高频是局部细节,低频更多是high level semantics。所以netwok最后可能以fit低频信号为主学到了high-level feature? 论文里面的visualization看起来也比较契合。
以前CovNets时代做不了,如果把mask的图丢给convnet,artifacts太大了,预训练时候模型时既得费劲入管mask out掉的region,预训练完了后还造成了跟后面完整图片的domain gap,吃力不讨好,我之前用convnet试过这种mask patch的相关的东西,结果乱七八糟的不work。但MAE里Transformer可以很好避开这个坑,太妙了。我的导师也评价说我们AI的ecosystem一直在变,所以方法的有效性和相对优越性也在evolve,不是一层不变的。
(2) 简单性 simplicity
这篇文章非常idea非常简单,实现起来也快捷,有趣的是文章里面一个公式都没放哈哈。我受导师Phillip的影响,认为在保持核心idea不变的情况下,或者说surpriseness不变的情况下,我们应该最小化系统的复杂度。因为越简单,也会愈发凸显惊讶程度。害,说起来我最开始接触科研老想着瞎加玩意儿,即使现在也经常做加法而不是减法,确实比较菜…
(3) 通用性 generality
其实(2)和(3)我也不确信哪个更重要,有时候(2)和(3)也相辅相成,越简单越通用。无疑MAE在(3)也做的很棒,几乎影响所有vision里面的recognition类别的任务,不过这也是做representation learning这方向的好处…死磕基础问题。
所以,综合这几点我觉得无疑是visual representation learning今年最有影响力的文章…
P.S. 看到有个答案说KM的研究品味不高,我完全不敢同意,每个人喜好做不同类型的工作罢了,在做方法算法这块,KM的的品味绝对是最top的,传闻就有做graphics的很solid的教授评价他: whatever this guy touches become gold。当然如果不是方法类的研究,而是要做一件从0到1的事,或者挖坑带领大家前进,那影响力就不能从这三个标准来看了,得看vision了。
02
回答二:作者-胡瀚
趁着写论文的间歇来写个回答,讲几个感想:
1. 除了idea和实验方面的天赋,还想说恺明对于技术趋势的敏锐性和革命前夕的神准把握方面实在太牛了。一直觉得创新本身不是最重要的,更重要的是带来改变领域走向的理解或者技术,恺明这篇论文无疑是会达到这一成就的,MoCo和Mask R-CNN也是如此,大巧无工,但真的改变了领域。
2. 过去我们过于看重linear probe这个指标,MAE无疑会改变这一现状,以及让我们重新去看待contrastive learning和mask image modeling的未来。很巧的是,一年前,我们NLC组的同事Hangbo Gao、 @董力 以及韦福如和我们提到要做和MAE类似路线的方法:BEIT,那时还觉得这个路线的方法学到的特征会太low-level,没想到半年后他们居然搞出来了,结果非常惊艳,事实上也改变了我的认知。MAE这个工作无疑也会让BEIT也大火起来, 尽管过去4、5个月BEIT其实在小范围内已经很受关注,但它受到的关注显然小于它实际的贡献。恺明大神这次的论文,让这个方向工作的重要性得到了应有的证明。
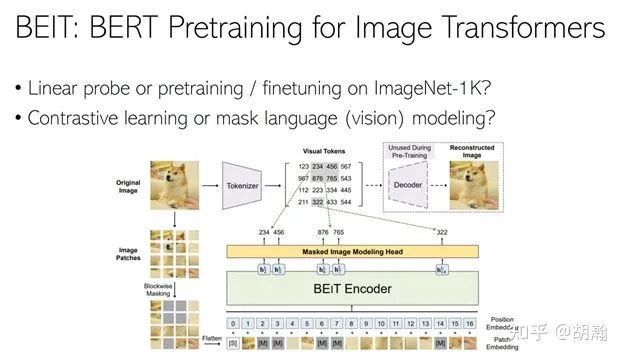
3. 看到恺明Intro里的一句话:”The idea of masked autoencoders, a form of more general denoising autoencoders [48], is natural and applicable in computer vision as well. Indeed, closely related research in vision [49, 39] preceded BERT.” 要特别赞一下这句话,其实也是有共鸣的,今年在RACV上讲了一个态度比较鲜明(或者极端吧。。)的talk,说要“重建CV人的文化自信”,就拿它作为其中一个例子:Mask Image Modeling或者视觉里叫Inpainting的方法在CV里做的蛮早的,在BERT之前就已经有一些。
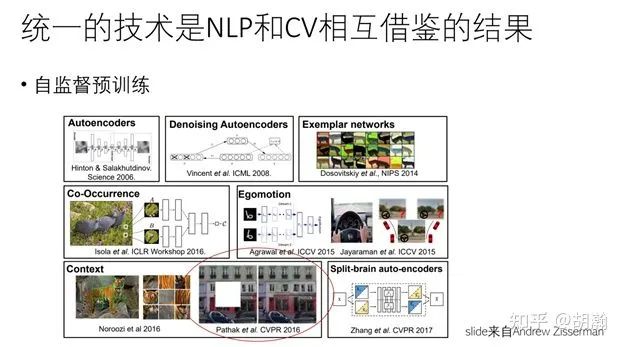
4. 想再次感叹一下,CV和NLP以及更多领域的融合看来真的是大势所驱了,希望不同领域的人多多合作,一起来搞事情。前几天见到董力和福如,他们提到有个多模态的工作因为挂了Arxiv不能投ACL了,我提议他们投CVPR,不晓得他们最后是什么决定。无论如何,CV的会议是很开放和包容的,理论的、偏工程的、交叉的、基于toy data做的,只要有点意思都有机会被接收,相信这也是CV领域能够长期这么繁荣的重要原因之一。在AI各个子领域技术趋同的背景下,它们之间的联系和跨界也会越来越紧密,这正是CV这个社区体现开放和包容心态的时候,吸引更多NLP的同仁们加入CV或者交叉研究中,以及我们自己去尝试给其他AI子领域进行贡献的时候,最终的目标就是和各个领域一起共舞,共同推进AI的进展。
03
回答三:作者-田柯宇
MAE 简单来说是把 pixel-level inpainting 在 ssl 上又做成功了(超过 contrastive learning) 这件事情:1)反常识. BEiT验证了 pixel reconstruction 相比 token prediction 更难学习,iGPT的性能也体现了这一点。2)大势所趋. 最近爆火的 contrastive learning 存在过度依赖 augmentation 的固有问题,而比较优雅的、在 nlp 领域全面开花的 generative ssl 在 vision 上却一直处于“低估/未被充分挖掘”的状态。
先摆明立场:
非常期待非 contrastive learning 的 ssl 方式在视觉领域的突破性进展(也算是轮回了)。下文会有一些关于这个点的讨论。
理智看待。“造神”或者“best paper 预订”的一些言论确实有些过度了,但个人也不赞同“认为 BEiT/MAE 是 BERT 的机械搬运”的观点。能把一个大胆的想法/一个无现成解法的问题做work(远超 iGPT,linear prob和finetune都很高),其实本身也是solid work的体现,其中肯定也包含了有价值的insight和细节处理可以挖。实际BERT在nlp中也不是第一个做biLM的工作,但的确是方案最成熟,也是时间见证了最有impact的那一支工作。
具体 comments:
一直觉得近期的 augmentation-based contrastive learning 并不是 ssl for vision 最优雅的方式:
虽然这波方法用上了图像数据上有很好先验的 data augmentation 这个文本数据没有的超大优势,但存在一个很大的固有问题:本质是学了一堆 transformation-invariant 的 representation. 而要判断用哪些 augmentation 是好的,i.e. 要判断让模型学到什么样的 transformation invariance 是好的,本身就依赖于要知道下游任务具体要干什么(比如下游任务如果认为颜色语义很重要,那么 color-based augmentation 就不应该用在 pretrain 中),导致“要想上游 pretrain 得好,就得先知道下游任务需要哪些语义信息”的奇怪尴尬局面。
这个问题在[3]中也有指出。另外最近一些工作似乎也在尝试让 contrastive learning 不仅仅只学一堆 invariance(例如同时保持对各种 transformation 的 variant 和 invariant,从而让下游自己去挑选),以期望得到一个更 general 的 ssl algorithm.
早些阵子的 vision ssl,pretext-task 更五花八门一些,主要是一些 discriminative(rotation degree prediction,location prediction,jigsaw,etc.)和 generative(inpainting)的方法。个人认为 inpainting 还是更优雅一些,也更接近 self-supervised 的本质(参考 LeCun's talk)。
但图像数据相比文本数据天然有更弱的语义性/语义密度、更强的连续性和不确定性,导致 pixel-level inpainting 天然很难做到像 BERT 那样的惊艳效果。再加上在 vision 大家都很关注的 linear probing 实验,又天然不利于 generative ssl 施展拳脚,就导致了现在 contrastive learning 大行其道、非 contrastive learning 被冷落的局面。
也许有人会 argue 说是因为早期 inpainting ssl 使用的模型太弱。但最近的 ViT,SiT,iGPT,甚至是 BEiT的 ablation,也说明了即便用上了先进的 ViT,探索一条不是 contrastive learning 的 ssl 道路仍然是艰难的。
所以,现在看到 BEiT、MAE 这样的工作,真的很欣慰。期待后续更多追溯原因和更深层解读的 paper。也希望 vision pretraining 能走的更好,感觉一组很强的 pretrained vision model 带来的社会价值真的很高。后续也会 post 上一些详细解读的笔记(有一些点真的很有意思,例如 BEiT 似乎体现了 用 dVAE 去 tokenizate 可以一定程度上缓解 pixel-level 带来的高连续性和不确定性的问题 但是 MAE 发现 tokenize 是没有必要的),简单梳理一下 vision ssl 然后重点理解下 BEiT 和 MAE,包括 coding 细节,希望能和大家多多交流~
觉得还不错就给我一个小小的鼓励吧!以上是关于大道至简,何恺明最新一作火了:让计算机觉视觉通向大模型!的主要内容,如果未能解决你的问题,请参考以下文章
时隔两年,CV大神何恺明最新一作:视觉预训练新范式MAE!大道至简!
何恺明时隔2年再发一作论文:为视觉大模型开路,“CVPR 2022最佳论文候选预定”...