何恺明时隔2年再发一作论文:为视觉大模型开路,“CVPR 2022最佳论文候选预定”...
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了何恺明时隔2年再发一作论文:为视觉大模型开路,“CVPR 2022最佳论文候选预定”...相关的知识,希望对你有一定的参考价值。
杨净 明敏 雷刚 发自 凹非寺
量子位 报道 | 公众号 QbitAI
大神话不多,但每一次一作论文,必定引发江湖震动。
这不,距离上一篇一作论文2年之后,何恺明再次以一作身份,带来最新研究。
依然是视觉领域的研究,依然是何恺明式的大道至简。
甚至在业内纷纷追求“大力出奇迹”、“暴力美学”的当下,何恺明还带着一种坚持独立思考的反共识气概。
简洁:通篇论文没有一个公式。
有效:大巧不工,用最简单的方法展现精妙之美。
江湖震动:“CVPR 2022最佳论文候选预定”。
所以,何恺明新作:
Masked Autoencoders Are Scalable Vision Learners

究竟有怎样的思想和研究成果?
用于CV的自监督学习方案
本文提出了一种用于计算机视觉的Masked AutoEncoders 掩蔽自编码器,简称MAE。
——一种类似于NLP技术的自我监督方法。
操作很简单:对输入图像的随机区块进行掩蔽,然后重建缺失的像素。

主要有两个核心设计。
一个是非对称的编码-解码架构,一个高比例遮蔽输入图像。
先来看编码-解码架构。
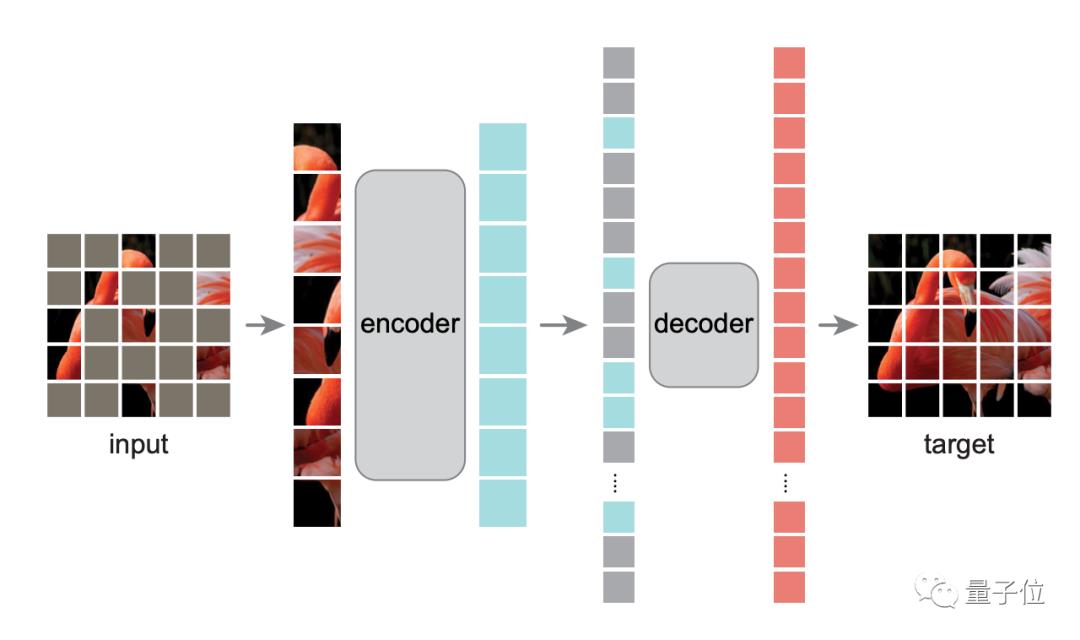
如图所示,编码器是ViT,它仅对可见区块进行操作,然后用一个轻量级编码器——仅在预训练期间负责图像重建任务。
具体而言,作者先将图像均匀划分为非重叠区块,然后随机对区块进行采样。
以遮蔽比例75%为例,它先在输入图像中掩蔽75%的随机区块,编码器只在可见的25%区块子集上运行,这样就可以只用非常少的计算和显存,来训练非常大的编码器。
然后解码器将可见的token和掩码token组合,并向所有token中添加位置嵌入,通过预测每个掩蔽区块的像素值来重建图像信号。
这样一来,在预训练时解码器可以独立于编码器,从而可以用非常轻量级解码器实验,大量减少预训练时间。
另一个特点则是对输入图像的高比例进行遮蔽时,自监督任务效果非常好。
比如,掩蔽掉80%随机patch的效果如下:

其中最左列为输入图像,中间列为MAE方法重建效果,最右侧为原图效果。
不同掩蔽比例在重建图像中的表现对比如下:

将这两种设计结合,结果用来训练大模型:
训练速度提升3倍以上,还提高准确率的那种。
除此之外,基于该方案所得出的大模型具备很好的泛化能力:
比如,在仅使用ImageNet-1K数据时,ViT-Huge模型准确性达87.8%。

在COCO数据集中的表现如下,虽然重建效果不清晰,但是基本语义是正确的。

研究者还对MAE迁移学习的性能进行了评估。
结果在下游任务,比如目标检测、实例分割、语义分割等任务都优于监督预训练。

在对比中可以看到,随机遮蔽75%、整块遮蔽50%和网格遮蔽50%的三种采样方法中,随机遮蔽75%重建图像的质量最好。

基于这些研究成果,何恺明团队在最后也表达了他们的看法。
一方面,扩展性好的简单算法是深度学习的核心。
在计算机视觉中,尽管自监督学习方面取得了进展,但实际预训练仍需受到监督。
这项研究中,作者看到ImageNet和迁移学习任务中,自编码器表现出了非常强的可扩展优势。
为此作者认为,CV中自监督学习现在可能正走上与NLP类似的轨道。
另一方面,作者注意,图像和语言是不同性质的信号,这种差异需要小心处理。
图像仅仅是记录下来的光,并没有语义分解为文字的视觉类似物。
他们不是去试图去除物体,而是去除可能不构成语义段的随机区块。重建的像素,也并不是语义实体。
研究团队
论文的研究团队,来自Facebook AI研究院(FAIR),每个人都屡屡获誉,堪称梦之队。

除了几位老将,我们这次再多说说里面的华人面孔。
Xinlei Chen,本科毕业于浙江大学计算机专业,随后在卡内基梅隆大学攻读博士学位,曾在UCLA、谷歌云、MSR实习。

谢赛宁,本科毕业于上海交通大学ACM班,随后在UC圣迭戈分校攻读计算机博士学位,曾在谷歌、DeepMind实习。

Yanghao Li,本科毕业于北京大学计算机专业,随后留在本校继续攻读硕士学位。

最后,再次隆重介绍下何恺明。
一作何恺明,想必大家都不陌生。作为Mask R-CNN的主要提出者,他已4次斩获顶会最佳论文。

何恺明是2003年广东高考状元,并保送了清华,进入杨振宁发起设立的物理系基础科学班。
硕博阶段,何恺明前往香港中文大学多媒体实验室,导师正是后来的商汤科技创始人汤晓鸥。
此间,何恺明还进入微软亚洲研究院实习,在孙剑指导下,以一作身份发表ResNet研究,一举成名天下知,荣获2016年CVPR最佳论文。
同年何恺明进入由Yann Lecun(获2019年图灵奖)掌舵的Facebook人工智能实验室,与Ross Girshick、Piotr Dollar——本次研究中的其他几位老面孔,组成了FAIR在AI研究领域的梦之队。
更加令人钦佩的是,何恺明年少成名,但这几年来依然不断潜心研究,一直带来新惊喜。
甚至他的新研究,很多都是那种可以开枝散叶的成果。
这一次,MAE同样被视为这样的延续。
你怎么看MAE?
论文链接
https://arxiv.org/abs/2111.06377
以上是关于何恺明时隔2年再发一作论文:为视觉大模型开路,“CVPR 2022最佳论文候选预定”...的主要内容,如果未能解决你的问题,请参考以下文章
时隔两年,CV大神何恺明最新一作:视觉预训练新范式MAE!大道至简!