Python爬虫框架Scrapy学习笔记
Posted 梦子mengy7762
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫框架Scrapy学习笔记相关的知识,希望对你有一定的参考价值。
scrapy.png
本文主要内容针对Scrapy有初步了解的同学。结合作者的实际项目中遇到的一些问题,汇成本文。
之后会写一些具体的爬虫demo, 放到 https://github.com/hanguangchao/scrapy_awesome
鉴于作者接触爬虫不久,水平有限,文章难免出现纰漏,还请各位达人留言指导。
内容提要
Scrapy问题记录
Scrapy问题示例代码
Scrapy常用代码片段
Scrapy常用设置
Scrapy参考资料
安装

使用
- 创建一个爬虫项目
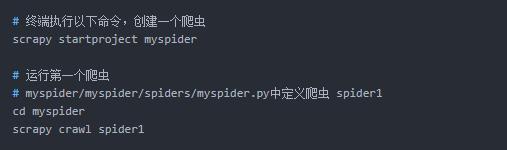
- scrapy shell 工具
可以利用scrapy shell 分析网页
通过sel.xpath() 返回一个Selector, 可以判断页面结构是否存在。

使用中遇到的一些问题
- 一个爬虫项目中,是否支持多个Item?
- 在一个页面抓取多个Item?不同的Item如何存储?
- 爬虫进入下一级网页?
- 在爬虫中携带自定义数据?
- 重复抓取一个页面的方法?
- 分别指定每个爬虫的设置?
- 防止爬虫被ban?
针对以上问题,下面给出具体的代码示例
- 定义可以定义多个Item

- 具体的爬虫脚本
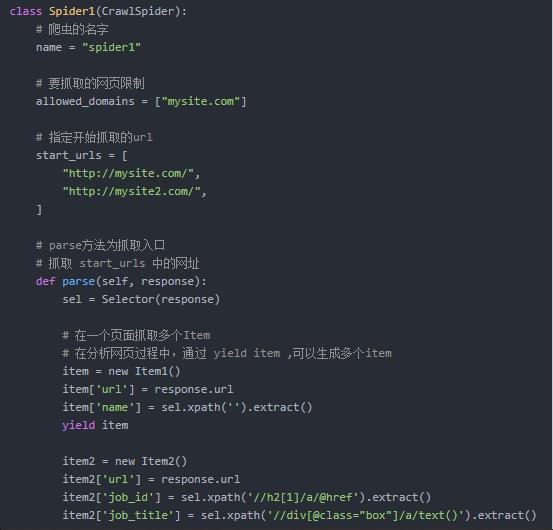

- 接第一个问题,多个Item,如何存储?
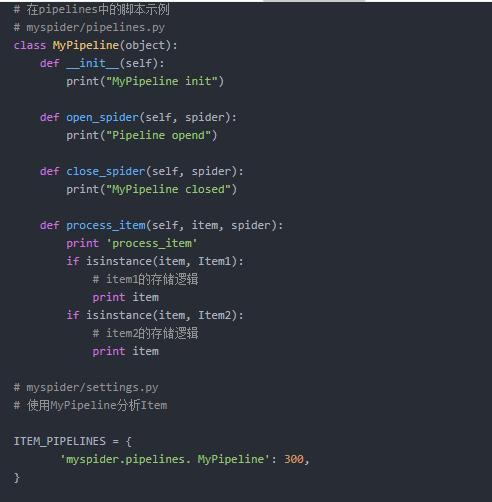
- Spider 自定义设置
使用custom_settings 该设置是一个dict.当启动spider时,该设置将会覆盖项目级的设置. 由于设置必须在初始化(instantiation)前被更新,所以该属性 必须定义为class属性
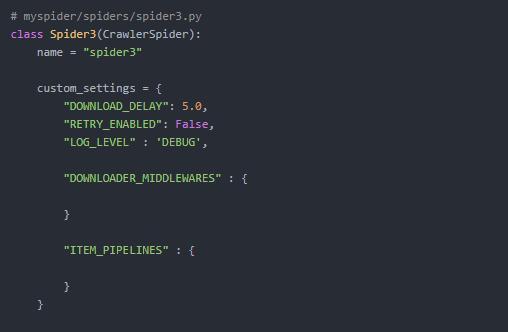
防止爬虫被ban
- 使用user agent池
- 使用IP池
- 禁止Cookie
- 增加下载延迟
- 分布式爬虫
- 一些常见设置
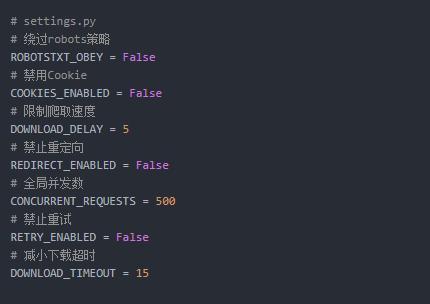
常用的Middleware
- 使用代理IP
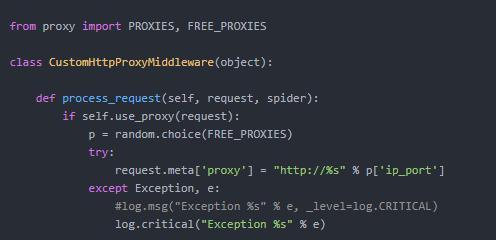
- 随机Agent
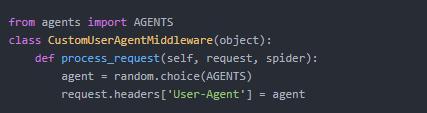
- 使用PhantomJS 抓取JS网页
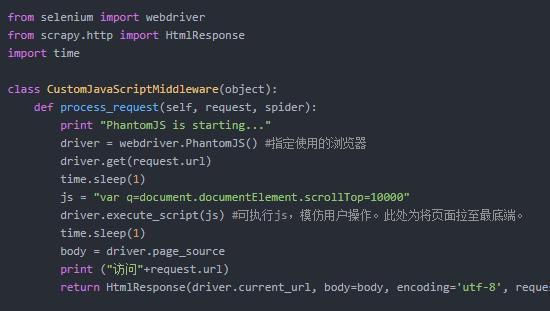
常用的Pipeline
过滤重复的Item
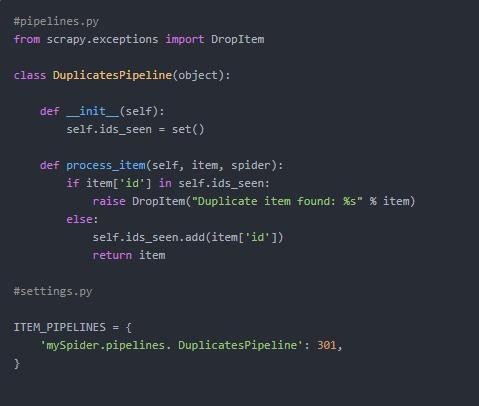
把Item存储到mysql的Pipeline
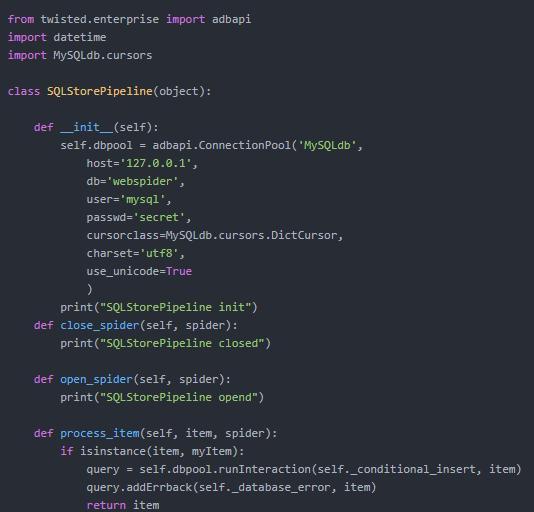
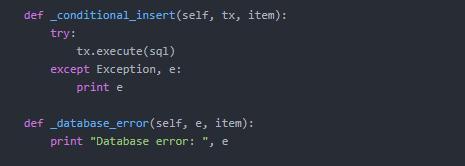
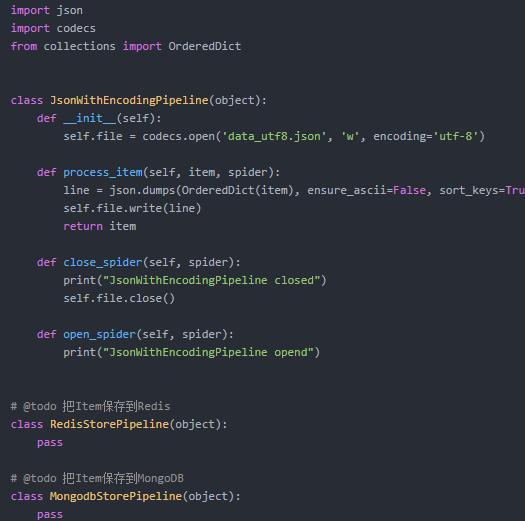
把Item保存到JSON文件

以上是关于Python爬虫框架Scrapy学习笔记的主要内容,如果未能解决你的问题,请参考以下文章