爬虫学习笔记—— Scrapy框架
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习笔记—— Scrapy框架相关的知识,希望对你有一定的参考价值。
一、Request
Scrapy.http.Request类是scrapy框架中request的基类。它的参数如下:
-
url(字符串) - 此请求的URL
-
callback(callable)- 回调函数
-
method(string) - 此请求的HTTP方法。默认为’GET’。
-
meta(dict) - Request.meta属性的初始值。
-
body(str 或unicode) - 请求体。如果没有传参,默认为空字符串。
-
headers(dict) - 此请求的请求头。
-
cookies - 请求cookie。
-
encoding(字符串) - 此请求的编码(默认为’utf-8’)此编码将用于对URL进行百分比编码并将body抓换str(如果给定unicode)。
-
priority(int) - 此请求的优先级(默认为0),数字越大优先级越高。
-
dont_filter(boolean) - 表示调度程序不应过滤此请求。
-
errback(callable) - 在处理请求时引发任何异常时将调用的函数。
-
flags(list) - 发送给请求的标志,可用于日志记录或类似目的
from scrapy.http import Request,FormRequest
req=Request("http://www.baidu.com",headers={"spider":666},meta={"name":"爬虫"})
#功能构造请求
#参数
#请求对象
print(req.url) #http://www.baidu.com
print(req.method) #GET
print(req.headers) #{b'Spider': [b'666']}
print(req.meta) #{'name': '爬虫'}
rer=req.replace(url="https://www.baidu.com")
print(rer.url) #https://www.baidu.com
二、FormRequest
get请求和post请求是最常见的请求。scrapy框架内置了一个FormRequest类
它扩展了基类Request,具有处理html表单的功能。
在使用scrapy发动POST请求的时候,常使用此方法,能较方便的发送请求.具体的使用,见登录github案例;
三、Response
url(字符串) - 此响应的URL
status(整数) - 响应的HTTP状态。默认为200。
headers(dict) - 此响应的响应头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。
body(字节) - 响应主体。要将解码后的文本作为str(Python 2中的unicode)访问,您可以使用response.text 来自编码感知的 Response子类,例如TextResponse。
flags(列表) - 是包含Response.flags属性初始值的列表 。如果给定,列表将被浅层复制。
request(Requestobject) - Response.request属性的初始值。这表示Request生成此响应的内容。
属性和方法
url 包含此请求的URL的字符串。该属性是只读的。更改请求使用的URL replace()。
method 表示请求中的HTTP方法的字符串。
headers 类似字典的对象,包含请求头。
body 包含请求正文的str。该属性是只读的。更改请求使用的URL replace()。
meta 包含此请求的任意元数据的字典。
copy() 返回一个新的请求,改请求是此请求的副本。
replace([ URL,method,headers,body,cookies,meta,encoding,dont_filter,callback,errback] ) 返回一个更新对的request
四、日志使用
logger
Scrapy logger 在每个Spider实例中提供了一个可以访问和使用的实例
例如:
self.logger.warning("可能会有错误")
日志文件配置
LOG_FILE 日志输出文件,如果为None,就打印在控制台
LOG_ENABLED 是否启用日志,默认True
LOG_ENCODING 日期编码,默认utf-8
LOG_LEVEL 日志等级,默认debug
LOG_FORMAT 日志格式
LOG_DATEFORMAT 日志日期格式
LOG_STDOUT 日志标准输出,默认False,如果True所有标准输出都将写入日志中
LOG_SHORT_NAMES 短日志名,默认为False,如果True将不输出组件名
示例(直接添加在settings里):
项目中一般设置:
LOG_FILE = 'logfile_name'
LOG_LEVEL = 'INFO'
日志格式输出:
LOG_FORMAT='%(asctime)s [%(name)s] %(levelname)s: %(message)s'
LOG_DATEFORMAT ='%Y'
日志等级:
DEBUG(调试信息)< INFO(一般信息) < WARNING(警告) < ERROR(错误) < CRITICAL(严重错误)
五、案例:实现Github登录
5.1、登录参数
登录需要向 https://github.com/session 网址提交用户名和密码,
除此之外,还有其他的参数(这里列举的仅供参考,具体还是要看网页的):
data={
'commit': 'Sign in',
'authenticity_token': authenticity_token,
'login': 'xxxxxxxxx@qq.com',
'password': 'xxxxxx',
'trusted_device': '',
'webauthn-support': 'supported',
'webauthn-iuvpaa-support': 'unsupported',
'return_to': 'https://github.com/login',
'allow_signup': '',
'client_id': '',
'integration': '',
required_field: '',
'timestamp': timestamp,
'timestamp_secret': timestamp_secret
}
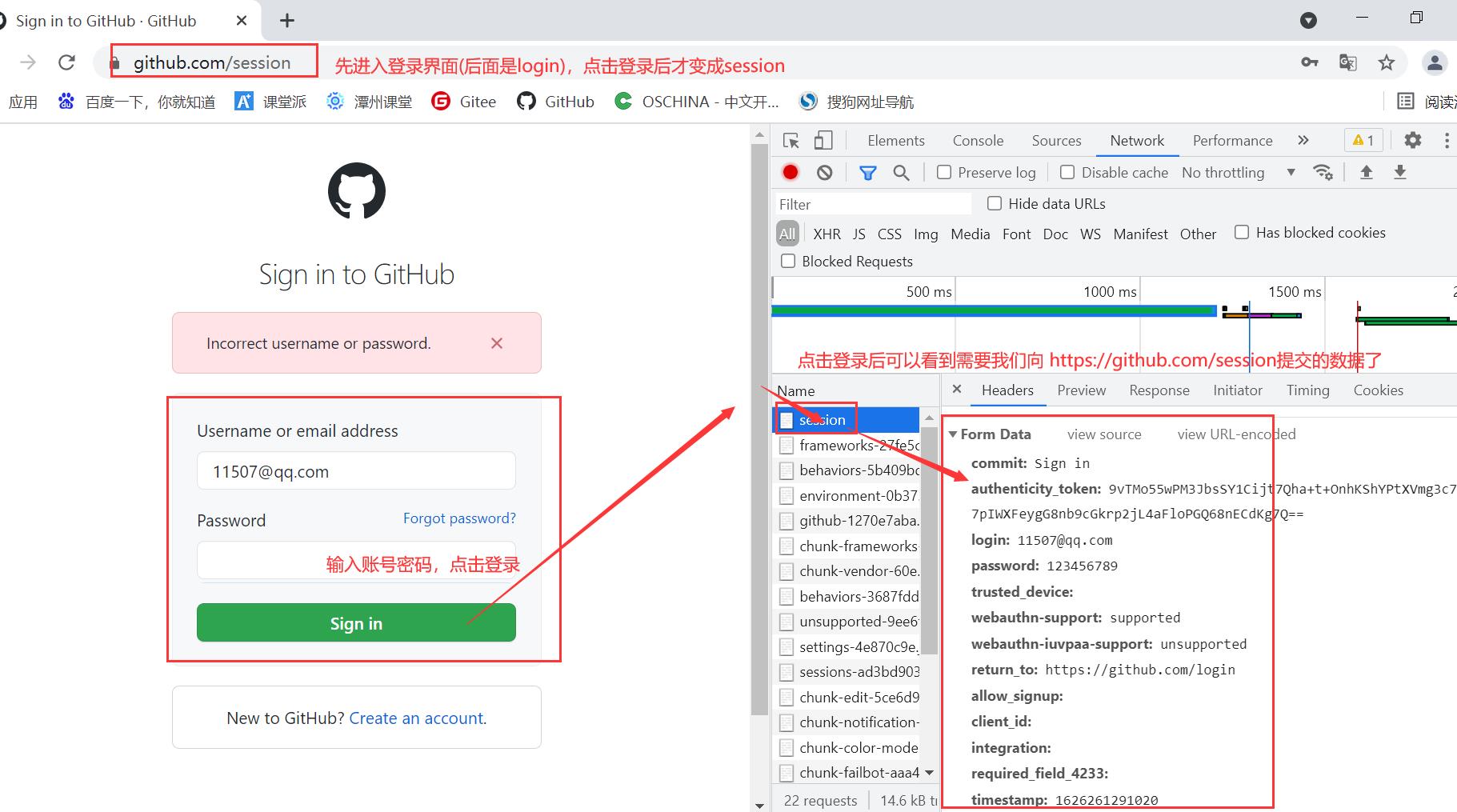
注意:需要提交的数据可能来源:
1.之前访问的页面中
2.JS动态生成
这需要经过分析检验,有些数据需要我们来构造,有些是默认的。
5.2、请求流程
- 访问 https://github.com/login 获取 https://github.com/session 需要的参数
- 向 https://github.com/session 提交 post 用户名 密码等数据 获取登录页面
5.3、代码:
spider文件
import scrapy
class LoginSpider(scrapy.Spider):
name = 'login'
# allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
#通过对比分析,以下需要我们来自己构建
authenticity_token = response.xpath('//input[@name="authenticity_token"]/@value').extract()[0]
required_field = response.xpath('//input[@hidden="hidden"]/@name').extract()[0]
timestamp = response.xpath('//input[@name="timestamp"]/@value').extract()[0]
timestamp_secret = response.xpath('//input[@name="timestamp_secret"]/@value').extract()[0]
data={
'commit': 'Sign in',
'authenticity_token': authenticity_token,
'login': 'xxxxxxxxx@qq.com', #记得写账号
'password': 'xxxxxx', #记得写密码
'trusted_device': '',
'webauthn-support': 'supported',
'webauthn-iuvpaa-support': 'unsupported',
'return_to': 'https://github.com/login',
'allow_signup': '',
'client_id': '',
'integration': '',
required_field: '',
'timestamp': timestamp,
'timestamp_secret': timestamp_secret
}
#使用FormRequest来请求
yield scrapy.FormRequest(url='https://github.com/session',formdata=data,callback=self.verify_login)
def verify_login(self,response):
if 'Q-bird1' in response.text: #Q-bird1是我登录成功后,网页源码里的特有的一个字符串
print('登录成功!!!')
else:
print('登录失败!!!')
settings文件
设置robots协议,添加全局请求头
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',
}
#设置日志的输出格式
LOG_FORMAT='%(asctime)s [%(name)s] %(levelname)s: %(message)s'
LOG_DATEFORMAT ='%Y'
结果(表示我们已经成功了):

以上是关于爬虫学习笔记—— Scrapy框架的主要内容,如果未能解决你的问题,请参考以下文章