生存分析——快手的基于深度学习框架的集成⽣存分析软件KwaiSurvival
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生存分析——快手的基于深度学习框架的集成⽣存分析软件KwaiSurvival相关的知识,希望对你有一定的参考价值。

看到快手这篇文章,还开源了他们的KwaiSurvival,上手试了试:
KwaiSurvival 是快⼿DA⾃主开发的基于深度学习框架的集成⽣存分析软件,帮助使⽤者在
Python编程环境下⾼效地使⽤⽣存分析模型实现⼤规模的数据分析
地址:https://github.com/kwaiDA/KwaiSurvival
本篇主要是今天简单测试了之后的一些笔记记录,
不知道他们组内的小伙伴看到这篇,会不会打我。。
我是觉得他们给的代码应该是实验版,有点粗糙啊。。
笔者自己测试成功的代码以及数据集可见:
本系列学习笔记:
- 生存分析——快手的基于深度学习框架的集成⽣存分析软件KwaiSurvival(一)
- 生存分析——KM生存曲线、hazard比例、PH假定检验、非比例风险模型(分层/时变/参数模型)(二)
- 生存分析——跟着lifelines学生存分析建模(三)
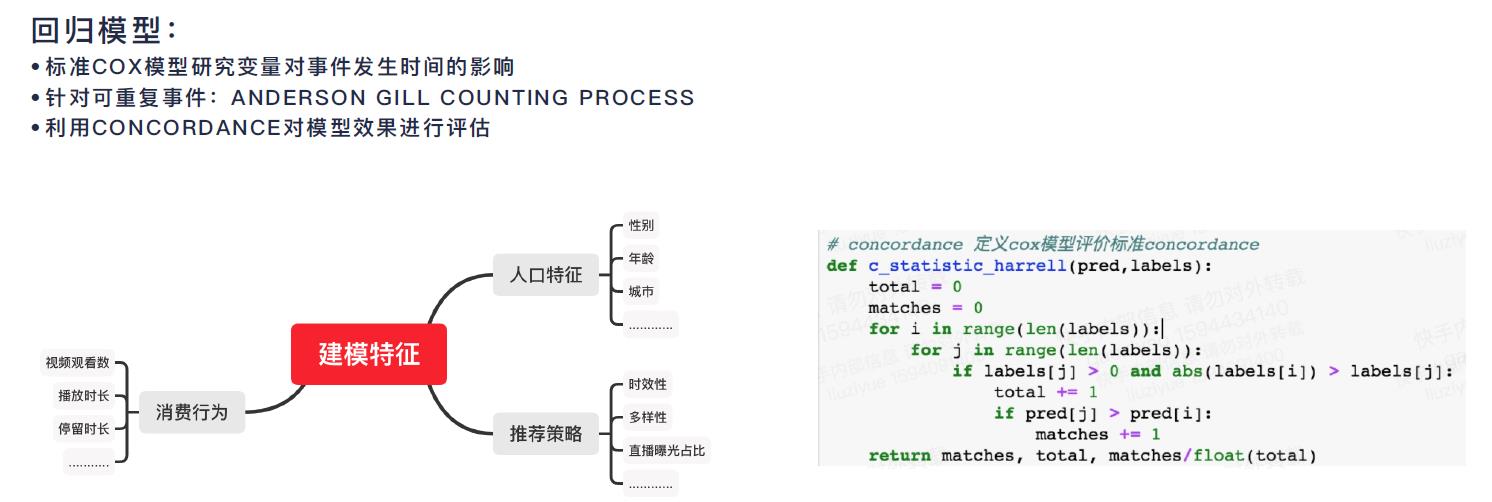
1 报告中的亮点
1.1 活跃度的概念
⽤户的⾏为随时间推移陆续发⽣,发⽣时间的快慢能为分析决策提供重要的信息,但DAU只体现了⼀定时间窗⼝内⽤户留存的结果,并未描述重要的时间信息
举例: A和B均有100万DAU,但A⽤户每隔4⼩时使⽤⼀次(每天6个sessions),B⽤户每隔6⼩时使⽤⼀次(每天4个sessions),谁的⽤户活跃度更⾼?
1.2 生存分析优势
⼀般回归模型处理的是截⾯数据,只关注事件的结果(⽤户是否使⽤APP)
⽣存分析既关注事件结果(⽤户使⽤APP与否),⼜将事件发⽣的时间纳入了分析框架,能
够有效刻画事件随时间变化的规律
1.3 ⽣存函数的刻画 - KM曲线


将生命周期理论应用在以下多个方面:

定义活跃的两条核心曲线:留存曲线 + 风险曲线:

1.4 ⽤户活跃度影响因⼦建模
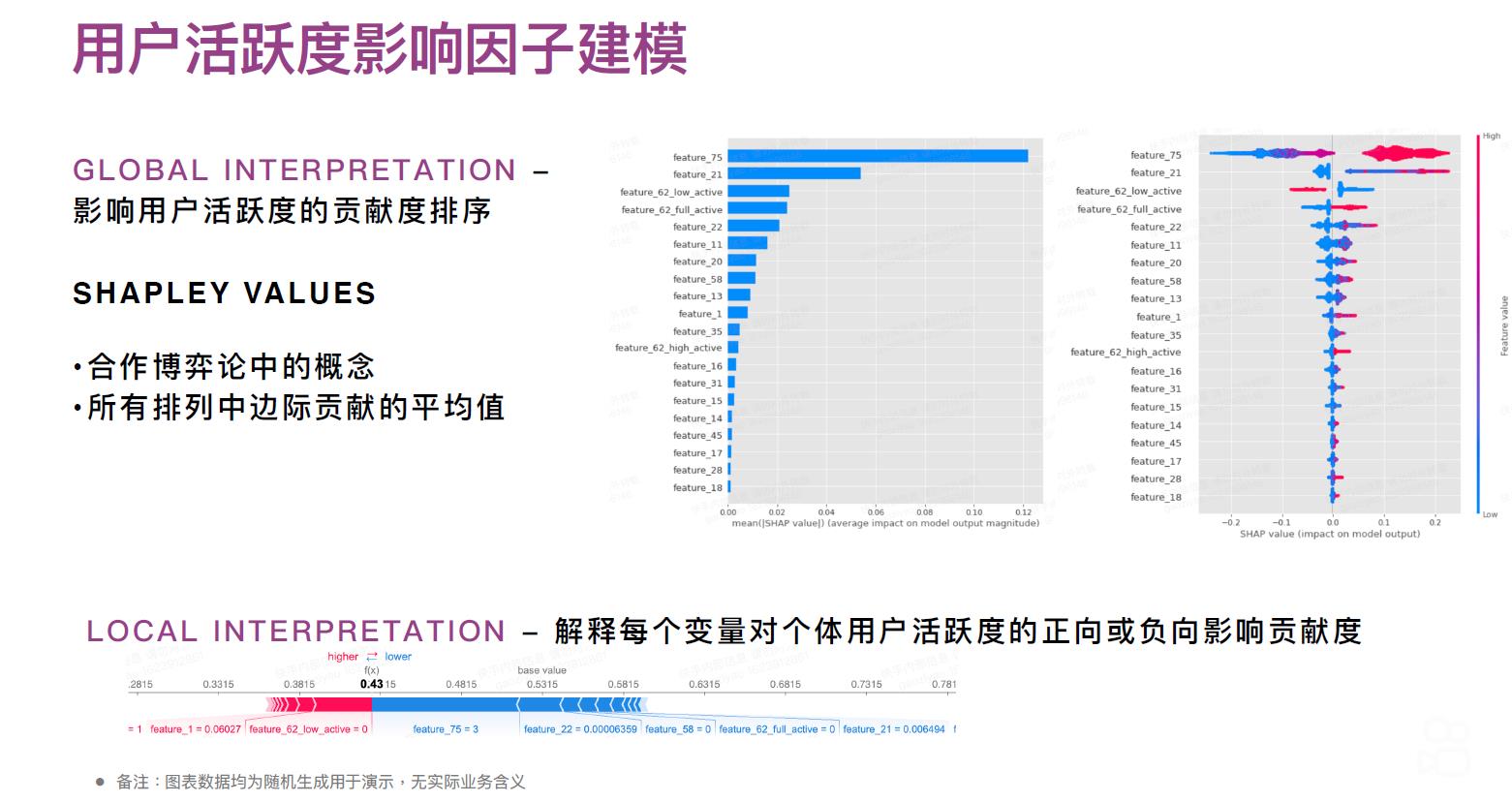
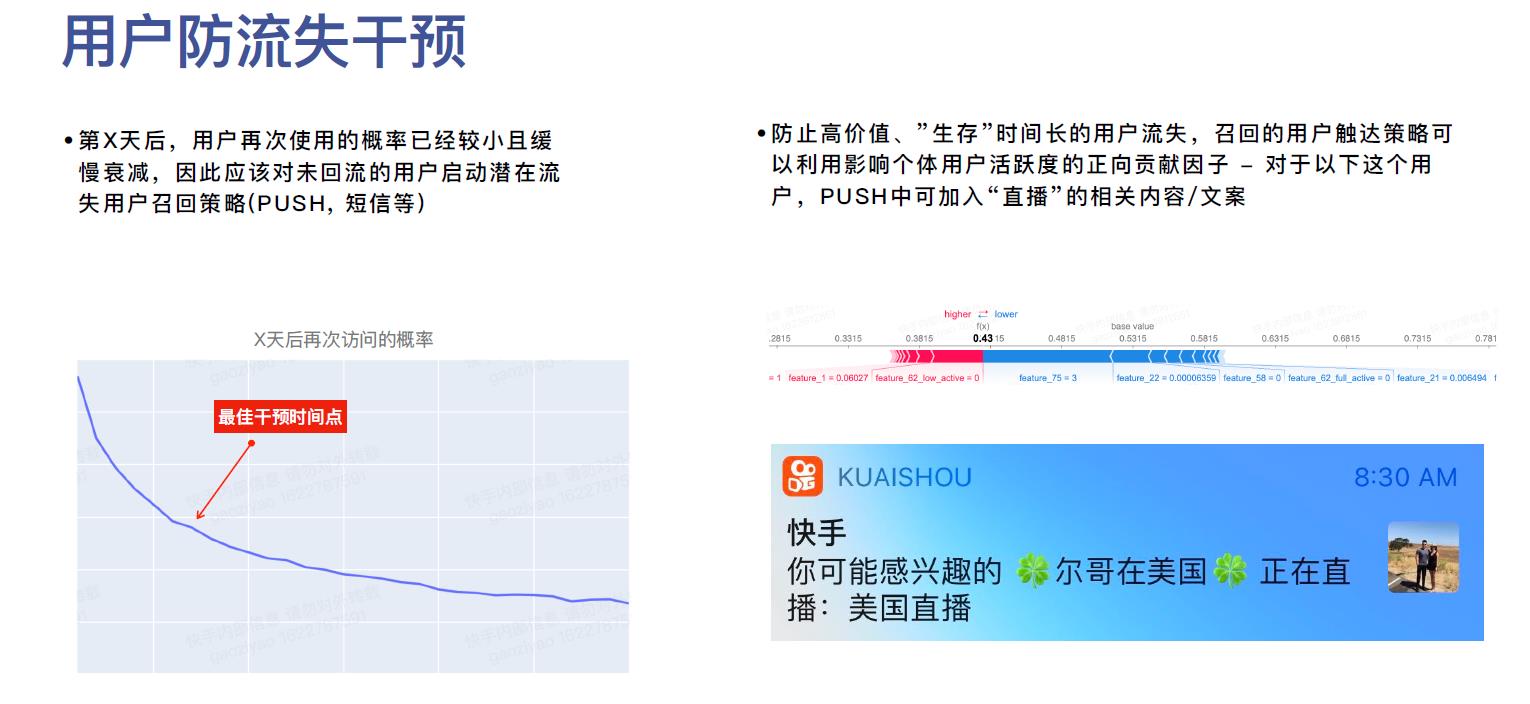
1.5 ⽤户活跃度影响因⼦建模后如何应用?
这里给笔者的一个启发是,用SHAP值来作为单个个体的个性化推荐/内容的推荐,也是一个有意思的角度与思路,关联可参考:
机器学习模型可解释性进行到底 —— SHAP值理论(一)
机器学习模型可解释性进行到底 —— 从SHAP值到预测概率(二)
2 KwaiSurvival框架的测试
地址:https://github.com/kwaiDA/KwaiSurvival
看上去是个给力的开源项目。
2.1 三个deep模型
三个模型:
- DeepSurv- Personalized Treatment Recommender System Using A Cox Proportional Hazards Deep Neural Network —— DeepSurv
- DeepHit- A Deep Learning Approach to Survival Analysis with Competing Risks—— DeepHit
- Deep Neural Networks for Survival Analysis Based on a Multi-Task Framework—— DeepMultiTasks

关于DeepSurv 相关的其他开源项目: - jaredleekatzman/DeepSurv
-liupei101/TFDeepSurv
-DeepSurv: personalized treatment recommender system using a Cox proportional hazards deep neural network
-czifan/DeepSurv.pytorch
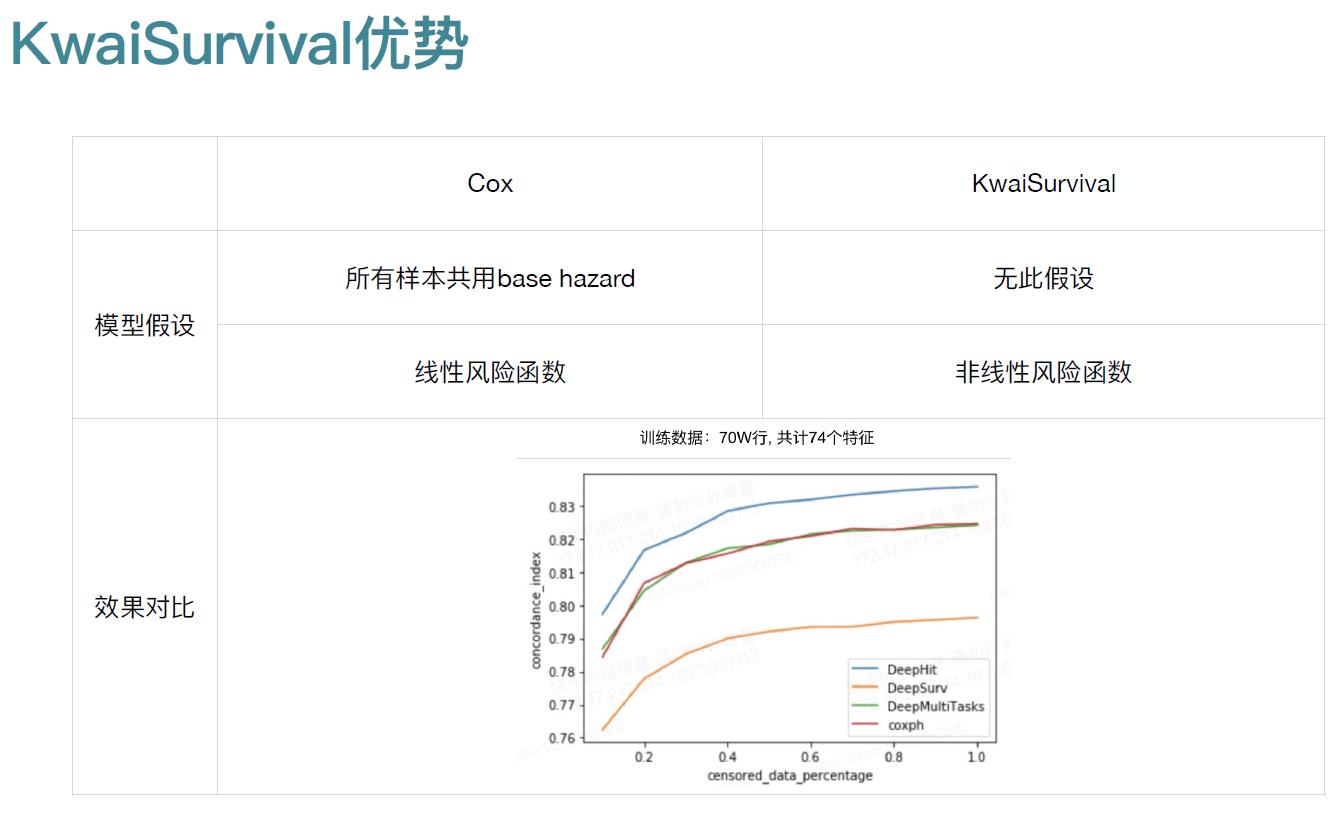
2.2 一致性检验Harrell’concordance index:C-index
参考:临床研究中常用的评价指标AUC和C-index
C-index的计算方法是把所研究的资料中的所有研究对象随机地两两组成对子,以生存分析为例,两个病人如果生存时间较长的一位其预测生存时间长于另一位,或预测的生存概率高的一位的生存时间长于另一位,则称之为预测结果与实际结果相符,称之为一致。
C-index在0.5-1之间(任意配对随机情况下一致与不一致刚好是0.5的概率)。0.5为完全不一致,说明该模型没有预测作用,1为完全一致,说明该模型预测结果与实际完全一致。一般情况下C-index在0.50-0.70为准确度较低:在0.71-0.90之间为准确度中等;而高于0.90则为高准确度。
C-index与AUC的区分:
C-index是一个可以用于判断各种模型区分能力的指标,针对二分类logistic回归模型,C-index可简化为:某疾病病人的预测患病概率大于对照的预测患病概率的可能性。经过证明,针对二分类模型的C-index等价于ROC曲线下面积(AUC)。
AUC主要反映二分类logistic回归模型的预测能力,但C-index可以评价各种模型预测结果的准确性,
可以简单这样理解:C-index是AUC的扩展,AUC是C-index的一种特殊情况。
2.3 代码测试——如何造数据
截至2021/7/9 还没有测试数据。。

没有数据,本想看看里面的代码能不能有些启发,造一些;
But关于数据样式没怎么提及,只能曲线救国,找到了jaredleekatzman/DeepSurv中的数据拿来测试了。
2.4 tf2.2安装的问题
pip install --pre tensorflow==2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
笔者在win10的机器上,升级了以下tf-cpu的版本,有报错:
ImportError:DLL load failed:找不到指定模块
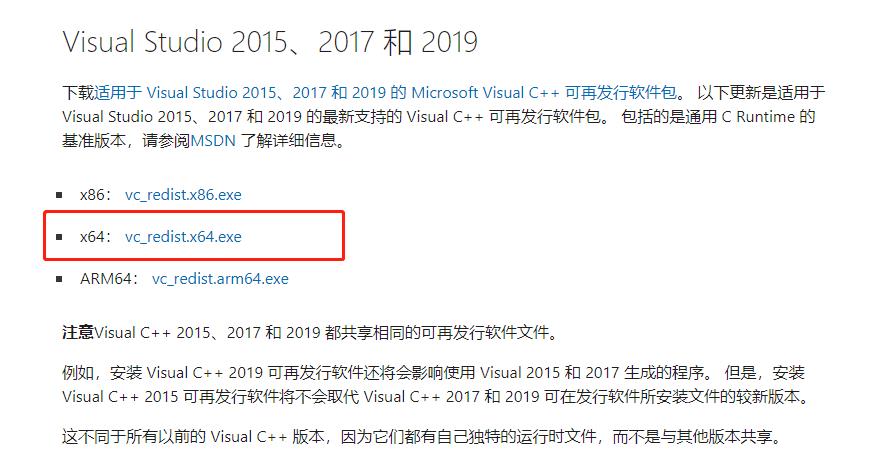
下载+安装一下下面的组件就可以正常使用了:Visual Studio 2015、2017 和 2019链接地址
2.5 模型保存
截至7/9 代码里没有更新模型保存模块,
但是呢,代码里又有自定义loss / Transform,save会报错:
NotImplementedError: Layer Total_Loss has arguments in `__init__` and therefore must override `get_config`.
之前没太遇到,参考了:
https://www.cnblogs.com/flyuz/p/11834038.html
https://blog.csdn.net/qq_39269347/article/details/111464049
https://www.cnblogs.com/hecong/p/13631393.html
这里就需要对三个模型源文件中的自定义loss / Transform简单加一下函数
2.5.1 DeepSurv
需在class Total_Loss新增get_config
class Total_Loss(tf.keras.layers.Layer):
def __init__(self, **kwargs):
# self.alpha = alpha
# self.beta = beta
super(Total_Loss, self).__init__(**kwargs)
def call(self, inputs, **kwargs):
y_pred, event= inputs
partial_hazard = tf.math.exp(y_pred)
log_cum_partial_hazard = tf.math.log(tf.math.cumsum(partial_hazard))
event_likelihood = (y_pred - log_cum_partial_hazard) * event
neg_likelihood = -1.0 * tf.reduce_sum(event_likelihood)
self.add_loss(neg_likelihood, inputs=True)
self.add_metric(neg_likelihood, aggregation="mean", name="nll_loss")
return neg_likelihood
def get_config(self):
# matt 20210709
#config = {"num_outputs":self.num_outputs}
base_config = super(Total_Loss, self).get_config()
return dict(list(base_config.items()) )
2.5.2 DeepHit
需在class Total_Loss新增get_config
class Total_Loss(tf.keras.layers.Layer):
def __init__(self, alpha, beta, **kwargs):
self.alpha = alpha
self.beta = beta
super(Total_Loss, self).__init__(**kwargs)
def get_config(self):
# matt 20210709
config = {"alpha":self.alpha,'beta':self.beta}
base_config = super(Total_Loss, self).get_config()
return dict(list(base_config.items()) + list(config.items()) )
def call(self, inputs, **kwargs):
y_true, nll_mat, rank_mat, event, y_pred = inputs
............................(此处还有很多代码)......................
2.5.3 DeepMultiTasks
第三个我不确定,因为我发现,我的数据一直没有跑通过。。。
class Total_Loss(tf.keras.layers.Layer):
def __init__(self,MAX_MAT_COL, **kwargs):
# self.alpha = alpha
# self.beta = beta
self.MAX_MAT_COL = MAX_MAT_COL
super(Total_Loss, self).__init__(**kwargs)
def call(self, inputs, **kwargs):
# Total_Loss()([inputs_label, inputs_nllmat, inputs_event, outputs])
y_true, nll_mat, event, y_pred = inputs
# tf.print(y_pred)
# if sum(sum(np.isnan(nll_mat)))!=0:
# print("break")
# nll loss
#tf.print('\\n ---- nll_mat',nll_mat)
tf.print('\\n ----y_pred',y_pred)
# y_pred [[-nan(ind) -nan(ind) -nan(ind) ... -nan(ind) -nan(ind) -nan(ind)]
tmp = tf.reduce_sum((nll_mat * tf.cast(tf.reshape(y_pred, [-1, self.MAX_MAT_COL+1]), dtype=tf.float32)), axis=1,
keepdims=True)
# if sum(sum(np.isnan(tmp)))!=0:
# print("break")
#tf.print(tmp)
log_likelihood_loss = - tf.reduce_mean(tf.math.log(tmp))
#tf.print(log_likelihood_loss)
# tf.print("break")
total_loss = log_likelihood_loss
self.add_loss(total_loss, inputs=True)
self.add_metric(total_loss, aggregation="mean", name="nll_loss")
return total_loss
def get_config(self):
# matt 20210709
config = {"MAX_MAT_COL":self.MAX_MAT_COL}
base_config = super(Total_Loss, self).get_config()
return dict(list(base_config.items()) + list(config.items()) )
## transform layer
class Transform(tf.keras.layers.Layer):
def __init__(self, **kwargs):
# self.alpha = alpha
# self.beta = beta
super(Transform, self).__init__(**kwargs)
def get_config(self):
# matt 20210709
#config = {"num_outputs":self.num_outputs}
base_config = super(Transform, self).get_config()
return dict(list(base_config.items()) )
def call(self, inputs, **kwargs):
y_pred, triangle = inputs
prediction = tf.matmul(y_pred, triangle)
tf.print(prediction.shape)
tf.print(triangle.shape)
# tf.print('break')
temp = tf.exp(prediction)
tf.print(temp.shape)
Z = tf.reduce_sum(temp, axis=1, keepdims=True)
#tf.print(Z.shape)
result = tf.divide(temp, Z)
#tf.print(result.shape)
return result
# if result[0] == result[0]:
# return result
# else:
# return y_pred
2.6 模型训练 + 预测
以我测试通的来看:
df = pd.read_csv('test/KwaiSurvival/demo/example_data.csv')
label = 'Time'
event = 'Event'
# 初始化 - 第一个模型 DeepSurv
ds = DeepSurv(df,label, event)
# 训练
epochs = 100
ds.train( epochs)
# 模型保存 - 这里代码没写,感觉这版代码是个实验版本的
ds.model.save('test/KwaiSurvival/path_to_my_model_DeepSurv.h5')
# 预测
scores = ds.predict_score(ds.X) # 1019 ,4
2.7 concordance_eval 评估与KM曲线
# concordance_eval 整体数据评估+检验
ds.concordance_eval( X = None, event_times = None, event_observed = None)
ds.concordance_eval( X = ds.X, event_times = ds.label, event_observed = ds.event)
# 局部数据评估+检验
ds.concordance_eval( X = df.iloc[:4,:4].to_numpy(), event_times = df[label][:4], event_observed = df[event][:4])
这里可以参考2.2 一致性检验Harrell’concordance index:C-index
可以针对整体 / 局部检验一致性
survival function 预测以及KM曲线:
# 完成DeepSurv模型对于X数据集的survival function 预测
survival_function = ds.predict_survival_func( ds.X)
survival_function.shape # 100*1019
# 第1000个数据的,KM曲线 - 上面的可视化
ds.plot_survival_func(ds.X, 1000)
会输出一个矩阵:100*1019
从predict_survival_func函数中这句得知:
data = ds.df.groupby(label, as_index=False).agg({event: 'sum', 'partial_hazard': "sum"}).sort_values(label,
ascending=False)
这里的100代表所有的时间点,也就是:len(set(ds.label)),
1019代表所有X个样本
也就是1019个样本,在所有时间点的留存率,是呈现递减的方式的
3 DeepMultiTasks 一直报错
这边笔者今天时间有限,就只是简单debug,自己没解决问题,所以先留个坑在这。。
看看什么时候有空再会看
所以我发现用我的假数据训练会出现:
4/4 [==============================] - 0s 7ms/step - loss: nan - nll_loss: nan
Epoch 10/10
loss为nan
然后检查了一下,发现这里有问题:
tmp = tf.reduce_sum((nll_mat * tf.cast(tf.reshape(y_pred, [-1, self.MAX_MAT_COL+1]), dtype=tf.float32)), axis=1,
keepdims=True)
于是发现y_pred == output的计算出现问题,一直是nan:
[[-nan(ind) -nan(ind) -nan(ind) ... -nan(ind) -nan(ind) -nan(ind)]
于是得回看一下整个model的有问题的,贴一下局部的:def nn_struct(self, elements, activation):函数:
output = tf.keras.layers.BatchNormalization()(inputs_X)
output = tf.keras.layers.Dense(self.MAX_MAT_COL, activation='linear')(output)
outputs = Transform()([output, self.triangle])
my_loss = Total_Loss(self.MAX_MAT_COL)([inputs_label, inputs_nllmat, inputs_event, outputs])
model = tf.keras.models.Model(inputs=[inputs, inputs_label, inputs_nllmat, inputs_event],
outputs=[outputs, my_loss])
这里Transform输出outputs的时候可能就有报错了,这个是开源项目的自定义layer,来看一下call函数:
def call(self, inputs, **kwargs):
y_pred, triangle = inputs
prediction = tf.matmul(y_pred, triangle)
tf.print(prediction.shape)
tf.print(triangle.shape)
# tf.print('break')
temp = tf.exp(prediction)
tf.print(temp.shape)
Z = tf.reduce_sum(temp, axis=1, keepdims=True)
#tf.print(Z.shape)
result = tf.divide(temp, Z)
#tf.print(result.shape)
return result
可能是前面传过来的时候就有问题了?这里还没细究,暂时追查到这,猜想几种可能:
- 可能是我的数据问题?
- attention这里有地方出现了问题
- attention之前有问题
- 。。。。。。(不知道。。)
当然,整体来看,我发现github源码中这里也各种tf.print不知道,是不是项目组自己也发现有这个问题了?然后解决了,但是没更新成功运行的版本?
有点猜不到了。。
以上是关于生存分析——快手的基于深度学习框架的集成⽣存分析软件KwaiSurvival的主要内容,如果未能解决你的问题,请参考以下文章
跟着开源项目学因果推断——FixedEffectModel 固定效应模型(十七)