浏览器中实现深度学习?有人分析了7个基于JS语言的DL框架,发现还有很长的路要走 Posted 2021-04-19 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器中实现深度学习?有人分析了7个基于JS语言的DL框架,发现还有很长的路要走相关的知识,希望对你有一定的参考价值。
本文中,作者基于WWW’19 论文提供的线索,详细解读了在浏览器中实现深度学习的可能性、可行性和性能现状。具体而言,作者重点分析了 7 个最近出现的基于javascript
深度学习(Deep Learning,DL)是一类利用多层非线性处理单元(称为神经元)进行特征提取和转换的机器学习算法。每个连续层使用前一层的输出作为输入。近十年来,深度学习技术的进步极大地促进了人工智能的发展。大量的人工智能应用,如图像处理、目标跟踪、语音识别和自然语言处理,都对采用 DL 提出了迫切的要求。因此,各种 DL 框架(Frameworks)和库(Libraries),如 TensorFlow、Caffe、CNTK 等,被提出并应用于实践。目前,这些应用程序可以在诸如 Windows、Linux、MacOS/ios android
最近,关于 DL 的一种应用趋势是应用程序直接在客户端中执行 DL 任务,以实现更好的隐私保护和获得及时的响应。其中,
在 Web 浏览器中实现 DL
,成为了人工智能社区关于客户端 DL 支持的重要研究目标。浏览器中的 DL 是用 JavaScript 实现的,依靠浏览器引擎来执行。基于 DL 的 Web 应用程序可以部署在所有平台的浏览器中,而不管底层硬件设备类型(PC、智能手机和可穿戴设备)和操作系统(Windows、Mac、iOS 和 Android)。这就使得在浏览器中实现 DL 具有非常良好的适配性能和普适性能,不会对客户端的选择有诸多限制。另外,html
不过,是不是我们现在就可以随心所欲的在浏览器中运行 DL 的模型或算法了?我们已经成功迈入在浏览器中实现深度学习的时代了么?尽管上面介绍的内容似乎意味着使在浏览器中运行 DL 任务成为可能,但是目前对于可以执行哪些 DL 任务以及 DL 在浏览器中的工作效果却缺少深入的研究和分析。更重要的是,考虑到 Web 应用程序与本机应用程序性能的长期争论,开发基于 DL 的 Web 应用程序时也存在同样的问题。在这篇文章中,我们以北京大学研究人员发表在 WWW’19(The World Wide Web Conference 2019)中的文章《Moving Deep Learning intoWeb Browser: How Far CanWe Go?》[1]作为参考主线,具体分析和探讨在浏览器中实现深度学习的问题。
在这一章节中,我们以文献 [1] 为参考主线,重点探讨现有的框架提供了哪些特性来支持在浏览器中实现各种 DL 任务。我们首先介绍了进行分析的几个框架,然后从两个方面比较了这些框架的特性:提供的功能和开发人员的支持。对于所提供的功能,主要检查每个框架是否支持 DL 应用程序开发中常用的一些基本功能。而对于开发人员支持,主要讨论一些可能影响开发和部署 DL 应用程序效率的因素。
为了选择最新的浏览器支持的 DL 框架,作者在 GitHub 上搜索关键字“deep learning framework”,并用 JavaScript 语言过滤结果。然后
选择了 GitHub 上星数超过 1000 的前 7 个框架[1]
。对每个框架的具体介绍如下:
TensorFlow.js[2] :2018 年 3 月由 Google 发布,是一个 inbrowser 机器学习库,支持使用 JavaScript 在浏览器中定义、训练和运行模型。TensorFlow.js 由 WebGL 提供支持,并提供用于定义模型的高级 API。TensorFlow.js 支持所有 Keras 层(包括 Dense、CNN、LSTM 等)。因此,很容易将原生 TensorFlow 和 Keras 预先训练的模型导入到浏览器中并使用 Tensorflow.js。
ConvNetJS[3] :是一个 Javascript 库,最初由斯坦福大学的 Andrej Karpathy 编写。ConvNetJS 目前支持用于分类和回归的常用神经网络模型和代价函数。此外,它还支持卷积网络和强化学习。然而遗憾的是,尽管 ConvNetJS 可能是在 TensorFlow.js 之前最著名的框架,但其在 2016 年 11 月后已经不再维护了。
Keras.js[4]:抽象出许多框架作为后端支撑,包括 TensorFlow、CNTK 等。它支持导入 Keras 预先训练的模型进行推理。在 GPU 模式下,Keras.js 的计算由 WebGL 执行。然而,这个项目也已经不再活跃。
WebDNN[5]:由东京大学发布的 WebDNN 号称是浏览器中最快的 DNN 执行框架。它只支持推理(训练)任务。该框架支持 4 个执行后端:WebGPU、WebGL、WebAssembly 和 Fallback pure JavaScript 实现。WebDNN 通过压缩模型数据来优化 DNN 模型,以加快执行速度。
brain.js[6]:是一个用于神经网络的 JavaScript 库,它取代了不推荐使用的 “brain” 库。它为训练任务提供 DNN、RNN、LSTM 和 GRU。该库支持将训练好的 DL 模型的状态用 JSON 序列化和加载。
synaptic[7]:这是一个不依赖于 JavaScript 架构的神经网络库,基本上支持任何类型的一阶甚至二阶 RNN。该库还包括一些内置的 DL 架构,包括多层感知器、LSTM、液态机(Liquid state machines)和 Hopfield 网络。
Mind[8]:这是一个灵活的神经网络库。核心框架只有 247 行代码,它使用矩阵实现来处理训练数据。它支持自定义网络拓扑和插件,以导入 mind 社区创建的预训练模型。然而,这个项目也已经不再活跃。
大多数框架都支持在浏览器中完成训练和推理任务。然而,Keras.js 和 WebDNN 不支持在浏览器中训练 DL 模型,它们只支持加载预训练的模型来执行推理任务。
有些框架并不是针对通用 DL 任务的,所以它们支持的网络类型有所不同。具体来说,TensorFlow.js、Keras.js 和 WebDNN 支持三种网络类型:DNN、CNN 和 RNN。但 ConvNetJS 主要支持 CNN 任务,不支持 RNN。brain.js 和 synaptic 主要支持 RNN 任务,不支持 CNN 网络中使用的卷积和池化操作。Mind 只支持基本的 DNN。
所有框架都支持以层(Layer)为单位构建神经网络。TensorFlow.js 的层 API 支持 49 种不同的层,包括密集层、卷积层、池化层、RNN、归一化等。其他框架支持的层类型较少,这也与它们所支持的网络类型有关。需要注意的是,TensorFlow.js 的核心 API 是 以类似于原生 TensorFlow 的方式实现的,它结合了各种操作来构建计算图。synaptic 是 一个架构无关的框架,支持构建任何类型的一阶甚至二阶 RNN 网络。
TensorFlow.js 为开发者提供了关于激活 / 优化器的最多种类的选择。对于激活函数,其他框架只支持基本的 sigmoid 或 ReLU。对于优化器,其他框架主要支持基本的随机梯度下降(SGD)。
TensorFlow.js 是唯一支持 GPU 加速训练任务的框架。TensorFlow.js、Keras.js 和 WebDNN 支持使用 GPU 来加速推理任务。WebDNN 还支持更先进的技术—WebGPU,但 WebGPU 只被 Safari 的技术预览版所支持。
文档。 TensorFlow.js、ConvNetJS、WebDNN 和 synaptic 提供的文档已经完成。Keras.js 的文档并不完整,brain.js 只有几篇教程。
演示。 所有的框架都为开发者提供了入门的 demo。TensorFlow.js 提供了最丰富的 demo,涵盖了广泛的用例。
从其他框架导入模型。 TensorFlow.js、Keras.js 和 WebDNN 支持在 Python 中从原生 DL 框架中导入模型,并且它们都提供了用于转换模型的 Python 脚本。TensorFlow.js 支持由 TensorFlow 和 Keras 训练的模型。Keras.js 支持 Keras 模型。WebDNN 支持从 TensorFlow、Keras、Caffe 和 Pytorch 导入模型。在支持使用其他 DL 框架的预训练模型的情况下,可以大大减少开发工作量。
API 保存 / 加载模型。 所有支持浏览器中训练任务的框架都有保存模型的 API。所有框架都有用于加载模型的 API。
支持服务器端(Node.js)。 所有框架都支持 Node.js。这样的功能使得浏览器内部的计算可以卸载到远程服务器上。
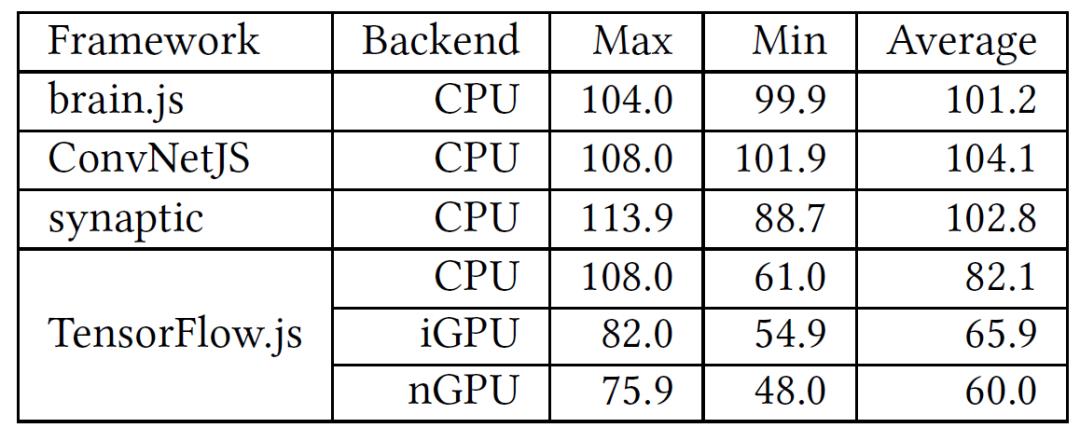
库大小。 表 1 中列出了需要加载到浏览器中的库文件的大小。ConvNetJS 是最小的,只有 33KB。TensorFlow.js 和 brain.js 的文件大小非常大,分别为 732KB 和 819KB。小型库更适合在浏览器中加载应用,因为所有的文件都要按需下载。
表 1. 基于 JavaScript 的框架在浏览器中支持深度学习的情况
本节重点讨论
现有框架的复杂度和后端处理器(CPU 或 GPU)对浏览器运行训练和推理任务时性能的影响
。
如前所述,不同框架支持的网络类型是不一样的。在实验中采用最基本的全连接神经网络作为模型。对于运行 DL 任务的数据集,使用经典的 MNIST 手写数字识别数据库。待训练的模型有 784 个输入节点和 10 个输出节点。为了研究模型复杂度对性能的影响,对模型进行了不同的配置设置。参数包括:1)神经网络的隐藏层数(深度),范围在 [1,2,4,8];2)每个隐藏层的神经元数(宽度),范围在[64,128,256]。深度和宽度的范围是基于“客户端 DL 模型应该是小尺寸,以便能够在客户端上运行” 的假设而设定的。在训练过程中,批处理大小始终设置为 64。
为了研究 CPU 和 GPU 的性能差异,使用一台 Hasee T97E 笔记本电脑,它的独立显卡是 Nvidia 1070 Max-Q(配备 8GB GPU 内存)。CPU 为 Intel i7-8750H,其中包含 Intel HD Graphics 630,使得实验中也能够使用集成显卡来验证性能。在下文中,用 nGPU 和 iGPU 分别表示独立 Nvidia 显卡和集成 Intel 显卡的 GPU。所有的实验都在 Ubuntu 18.04.01 LTS(64 位)上的 Chrome 浏览器(版本:71.0.3578.10 dev 64 位)上运行,且使用各个框架最新发布的版本。
对于每个 DL 任务,实验中构建了一个网页,可以通过 URL 中的参数来改变 DL 模型的配置。作者在 Chrome 浏览器上运行每个 DL 任务,并记录完成任务的时间。由于每个实验通常需要运行不同配置下的几十个任务,作者开发了一个 Chrome 浏览器扩展版本:可以迭代运行所有页面,并在一个任务完成之后更改配置。该扩展版本的浏览器还能够监控网页的系统资源使用情况。
作者选取了支持在浏览器中进行训练的 brain.js、ConvNetJS、synaptic 和 TensorFlow.js 四个 JavaScript 框架进行实验,比较它们完成训练任务的性能。除了 Tensor-Flow.js 能通过 WebGL 使用 GPU 外,其他框架都是基于 CPU 训练模型的。作者使用每个框架对定义的模型进行训练,获得训练一批模型的平均时间。图 1 给出了不同模型复杂度的结果。由于 synaptic 的训练时间大约是其他框架的几十倍到几百倍,为了更好的展示,作者在图中省略了 synaptic 的结果,但实际上它的结果与其他框架是相似的。
一般来说,训练时间会随着网络规模的增大而增加,因为对于较大的网络,需要更多的计算量来完成训练过程。比较不同框架在 CPU 后台的训练时间,我们可以看到 ConvNetJS 是所有框架中所有网络配置下速度最快的。作者分析,可能的原因是 ConvNetJS 的设计比较简单,这也可以从它的库文件大小反映出来。在速度方面 Brain.js 紧随其后,与 ConvNetJS 的性能差距约为 2 倍,而 Tensorflow.js 与 ConvNetJS 的性能差距约为两到三倍。在对比 ConvNetJS 与 TensorFlow.js 的训练时间时,作者发现当深度和宽度增加时,性能差距会逐渐缩小,这说明与 ConvNetJS 相比 Tensor-Flow.js 的计算之外的开销相对较大。此外,随着网络宽度的增加而导致的性能差距要比随着网络深度增加而导致的性能差距要大,这意味着 TensorFlow.js 比 ConvNetJS 更适合于处理大规模矩阵计算。
CPU 后端的训练时间随着网络规模的增大而变长,但 GPU(iGPU 和 nGPU)后端的训练结果却不尽相同。对于计算能力较弱的 iGPU 和能够满足较大规模矩阵计算的 nGPU,训练时间并没有显著增加。但在从 4 个隐层、每层 128 个神经元到 8 个隐层、每层 256 个神经元的过程中,iGPU 的训练时间明显增加。作者分析,其原因可能是在本实验设定的网络规模下,训练过程没有达到 GPU 的能力瓶颈。虽然 nGPU 的矩阵计算能力优于 iGPU,但 nGPU 的训练时间比 iGPU 长。作者分析这种结果可能是由于调用 WebGL 访问 GPU 的时间开销过大造成的,实际上单纯 GPU 的实时计算时间要短得多。
图 1. 在不同模型复杂度下,一个批次的平均训练时间(ms),Y 轴为对数刻度。
表 2 中给出了在训练过程中每个框架的 CPU 利用率的统计数据。110% 是 CPU 利用率的上限。由于 JavaScript 引擎是单线程的,因此不能使用多核处理器的功能,它只能最大限度地提高单核的使用率。之所以 CPU 利用率超过 100%,是因为其他内核和用户空间组件偶尔会在其他线程中同时运行。在 CPU 后端,TensorFlow.js 有时无法最大化单个核心的利用率,其平均 CPU 利用率仅为 82.1%。同时,作者发现在 GPU(iGPU 和 nGPU)后端运行训练任务时,由于大部分计算都在 GPU 上,所以 CPU 的利用率并不高。iGPU 上的训练比 nGPU 上训练的 CPU 利用率要高 5-7% 左右。
作者选择了 6 个 JavaScript 框架来比较它们运行推理任务的性能。TensorFlow.js、Keras.js 和 WebDNN 支持使用 GPU 进行加速,但 brain.js、ConvNetJS 和 synaptic 只支持使用 CPU 进行推理。在模型使用方面,brain.js、ConvNetJS、synaptic 和 TensorFlow.js 支持保存自己训练的模型,而 Keras.js 和 WebDNN 只支持从其他深度学习框架导入预训练的模型。因此,对于 brain.js、ConvNetJS、synaptic 和 TensorFlow.js 直接使用框架本身保存的模型。对于 Keras.js 和 WebDNN,则需要使用 Keras 训练的模型,然后将模型转换为相应的格式。理论上,训练得到的 DL 模型的参数值应该是不同的,但绝对值不会影响推理时间。所以只需要给不同框架的所有模型分配相同的参数值即可。推理任务包括加载一个预先训练好的模型,然后给定一个样本输入,模型输出结果。此外,在 GPU 后端,有一个预热过程,推理的第一个样本通常用于激活 GPU 处理器。因此,作者将推理过程分解为模型加载、预热和推理三个阶段,并研究性能细节。
由于篇幅所限,作者在下面的分析中省略了模型深度为 8 的结果,因为随着深度的增加,趋势是相似的。另外,由于 synaptic 的模型加载时间和推理时间仍然比其他框架长很多,为了更好的展示,作者没有在图中给出 synaptic 的结果。
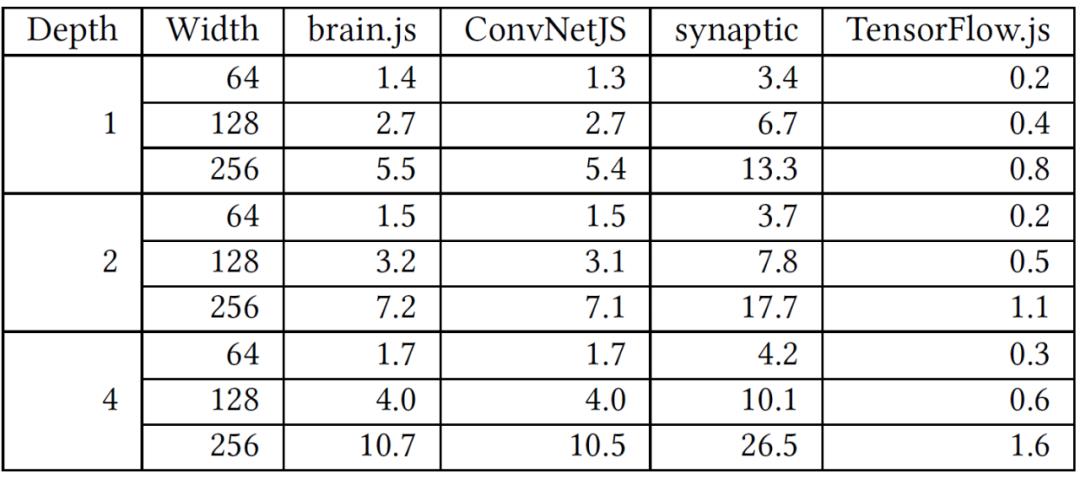
首先研究不同框架使用的模型文件的大小。由于通常需要从远程服务器下载用于推理的模型,模型文件的大小越小意味着下载时间越短。表 3 给出了所有推理实验中使用的模型文件的大小。ConvNetJS 和 brain.js 使用类似的 JSON 编码,所以它们的模型文件大小几乎相同。synaptic 的模型文件也使用 JSON 编码,但其大小是所有框架中最大的。由于 TensorFlow.js、Keras.js 和 WebDNN 使用的模型文件都是由 Keras 模型转换而来,所以它们的模型文件大小是一样的,作者只在表 3 中显示 TensorFlow.js。由于从 Keras 转换而来的模型被压缩后保存为二进制文件,所以大小可以大大缩小,只有 JSON 中模型文件的 1/7 左右。
然后,我们比较加载不同框架的模型所花费的时间,如图 2 所示。对于 CPU 后端,同一框架的不同模型的加载时间与表 3 中描述的模型文件的大小成正比。但是,不同框架的模型加载时间有显著差异。ConvNetJS 是最快的。Brain.js、TensorFlow.js 和 Keras.js 的模型加载时间在幅度上是一致的。有趣的是,当宽度增加时,ConvNetJS、brain.js 和 synaptic 的加载时间增加特别明显。这个结果是由它们选择使用 JSON 来编码模型所造成的。在所有框架中,synaptic 的模型加载时间最慢,比 ConvNetJS 长 100 多倍到 1000 多倍。无论模型大小,TensorFlow.js 的模型加载时间几乎没有变化。
在不同的模型复杂度下,GPU(iGPU 和 nGPU)后端的加载时间变化不大。但是,不同框架之间的差异还是很大的。TensorFlow.js 是最快的。与在 CPU 后端加载模型相比,Keras.js 加载大型模型的速度较快,但 WebDNN 的加载时间较长。此外,可以看到 iGPU 和 nGPU 的模型加载时间没有区别。
接下来,我们检查 GPU(iGPU 和 nGPU)后端预热时间的差异。如图 3 所示,Keras.js 还是遥遥领先,可以在 3 毫秒内完成所有任务的预热。Tensorflow.js 第二,WebDNN 最差。整体而言,iGPU 后端的预热时间比 nGPU 要短。
图 3. 不同模型复杂度下 GPU 上的模型预热时间(ms),y 轴为对数刻度。
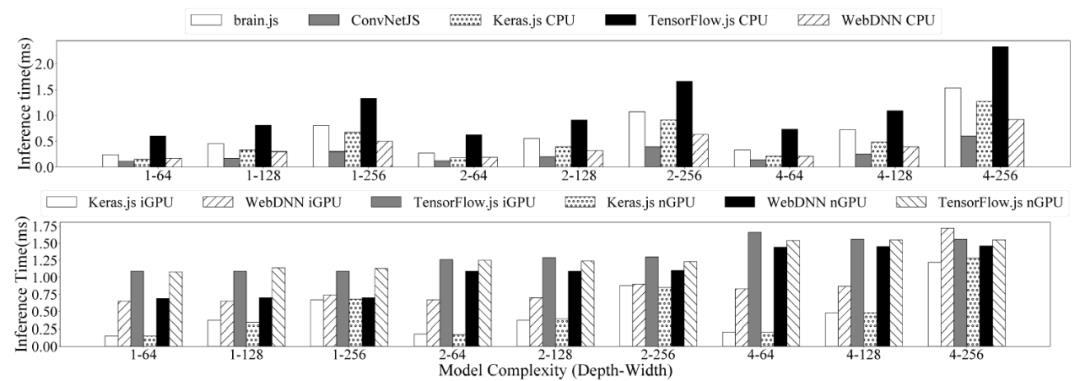
图 4 给出了对一个样本进行推理的平均时间。几乎所有的推理任务都能在 1.5ms 内完成(除了 synaptic,其中时间最短的为 6.68ms)。在作者设定的模型大小范围内,GPU 强大的计算能力并没有造成任何影响。在所有的模型大小中,ConvNetJS 占据了所有的第一位,其次是 CPU 后台的 WebDNN。
图 4. 在不同的模型复杂度下,一个样本的平均推理时间(ms)。
WebDNN 在 GPU(nGPU 和 iGPU)后端的推理时间比 CPU 后端的推理时间长。至于 TensorFlow.js,在 CPU 后端运行对于较小模型的推理速度更快,而 GPU 后端对于较大模型的推理速度更快。Keras.js 在 CPU 和 GPU 后端的推理时间基本一致。我们可以观察到,对于 CPU 后端的所有框架,当模型变得复杂时,推理时间会增加。特别是当宽度增加时,时间会急剧增加(随着模型宽度增加一倍,时间增加约 2 倍)。训练任务情况类似。这样的结果也反映出这些框架在 CPU 后端的前向传播过程中没有对大规模矩阵运算进行优化。GPU 后端的 TensorFlow.js 和 WebDNN 并没有出现这个问题,但后端为 GPU 的 Keras.js 仍然存在这个问题。
根据以上结果我们可以看到,在浏览器能够胜任的小规模全连接神经网络中,ConvNetJS 在训练和推理方面的表现都是最好的。不过,由于 ConvNetJS 已经不再维护,功能较少,开发者可能还是需要寻找替代品。Tensorflow.js 是唯一可以利用 GPU(nGPU 和 iGPU)加速训练过程的框架。它功能丰富,性能与 ConvNetJS 相当。所以 TensorFlow.js 对于训练和推理都是一个不错的选择。作者不建议在小规模的模型上使用 GPU 作为后端,因为 GPU 计算能力的优势并没有得到充分利用。
最后,为什么 ConvNetJS 在这些框架中的所有任务都有最好的性能。对于流程逻辑相同的同一模型,性能差异很可能由不同的实现细节来解释。为此,作者在完成相同训练任务时比较了 ConvNetJS 和 TensorFlow.js 的函数调用堆栈(Function Call Stack)。令人惊讶的是,ConvNetJS 的调用堆栈深度只有 3,而 TensorFlow.js 是 48。这样的结果表明,不同框架之间性能差异的一个可能原因是深度调用堆栈,这会消耗大量的计算资源。
我们在上文已经分析了目前主要的浏览器 DL 框架结构、特点,也通过实验证明了不同框架的效果。那么,在浏览器中运行 DL 和原生平台上运行 DL 的性能差距有多大?作者比较了 TensorFlow.js 和 Python 中的原生 TensorFlow 的性能,两者都是由 Google 发布和维护的,并且有类似的 API,因此所比较的结果是足够公平的。
作者使用 Keras 官方提供的预训练模型来衡量 TensorFlow.js 和原生 TensorFlow 在这些经典模型上完成推理任务时的性能。
3.1.1 TensorFlow.js 的局限性和浏览器约束
Keras 官方提供了 11 个预训练模型。虽然在原生 TensorFlow 上运行这些模型时是一切正常的,但当作者在浏览器中使用 TensorFlow.js 运行它们时却遇到了一系列错误。作者认为,这些错误是由于 TensorFlow.js 本身的限制以及浏览器施加的限制所造成的。例如,对于 NasNet Large 模型,浏览器会抛出以下错误信息 “truncatedNormal is not a valid Distribution "。对于 ResNet V3 模型,浏览器会抛出错误信息"Unknown layer: Lambda"。出现这两个错误的原因是 TensorFlow.js 仍在开发中,到目前为止只提供了对有限的转换模型的支持。许多用户定义的操作算子 TensorFlow.js 是不支持的,例如,TensorFlow.js 不支持使用 RNN 中控制流操作算子的模型。当尝试使用 VGG16 或 VGG19 时,浏览器会抛出"GL OUT OF MEMORY " 的错误信息,这意味着 GPU 内存溢出。VGG16 模式适用于超过 1GB 的 GPU 内存,不过实验中使用笔记本的 GPU 内存是 8GB(Nvidia 1070 Max-Q),所以应该不是由内存所导致的问题。作者分析,这样的错误是由于浏览器的限制造成的。
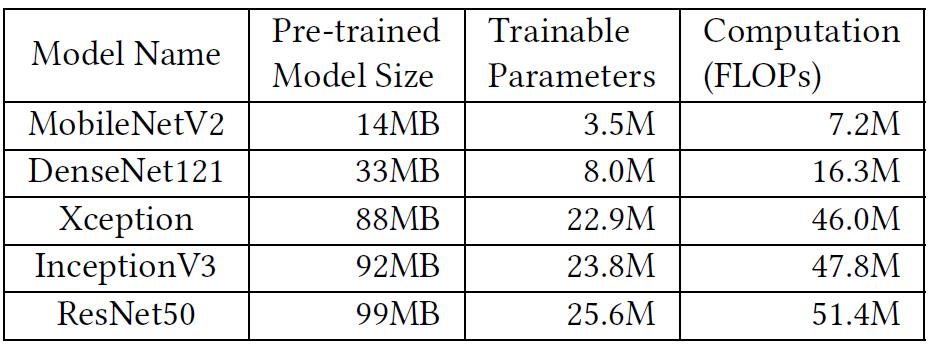
在尝试了所有的模型后,作者得到了 5 个可以正确转换并在浏览器上运行的模型。这些模型的信息列在表 4 中。可训练参数的数量由 tensorflow.keras 的 build-in summary()方法获得,计算复杂度 (Floating Operations) 由 tensorflow.profiler.profile()方法获得。
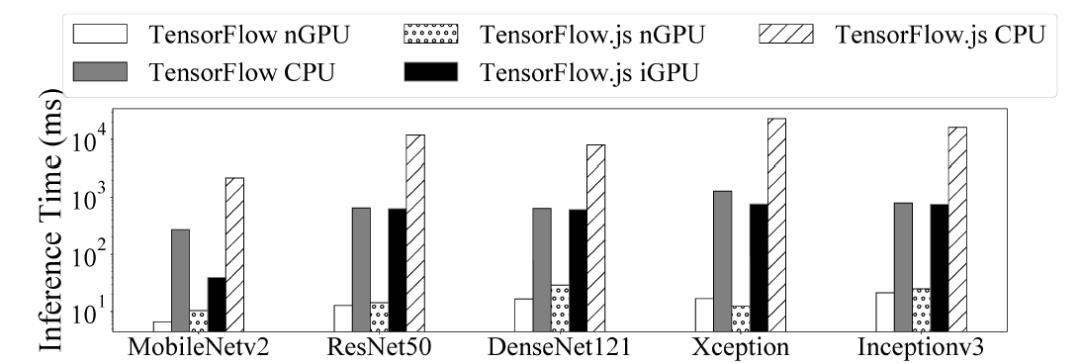
图 5 给出了每个模型的推理时间。可以看出,TensorFlow.js 在 nGPU 上的推理时间与原生 TensorFlow 的相当(慢 1 倍 - 2 倍)。iGPU 后端的 TensorFlow.js 的性能比 CPU 后端的原生 TensorFlow 还要好。作者分析,考虑到集成显卡和 CPU 的计算能力,这一结果并不奇怪。然而,由于原生 DL 框架不支持集成显卡加速,通过浏览器执行的 DL 框架可以在集成显卡的应用中获益良多,毕竟,现在的设备中集成显卡已经是非常常见的了。
在客户端 DL 的实时性要求下,如果用户想要达到 10FPS(每秒帧数)的体验,就需要考虑使用更强大的独立显卡。而通过 iGPU 加速的移动网络模型也能满足要求。如果要求是达到 1FPS,iGPU 也完全可以满足。但如果只能使用 CPU,那么在浏览器中运行这些很常见的模型看起来就太过于沉重了。
图 5. 预训练的 Keras 模型的推理时间,y 轴为对数刻度。
最后,为了深入探索不同因素是如何影响 DL 在浏览器和原生框架上的性能差距的,作者建立了一个基于决策树的预测模型,具体研究各种因素的重要性。
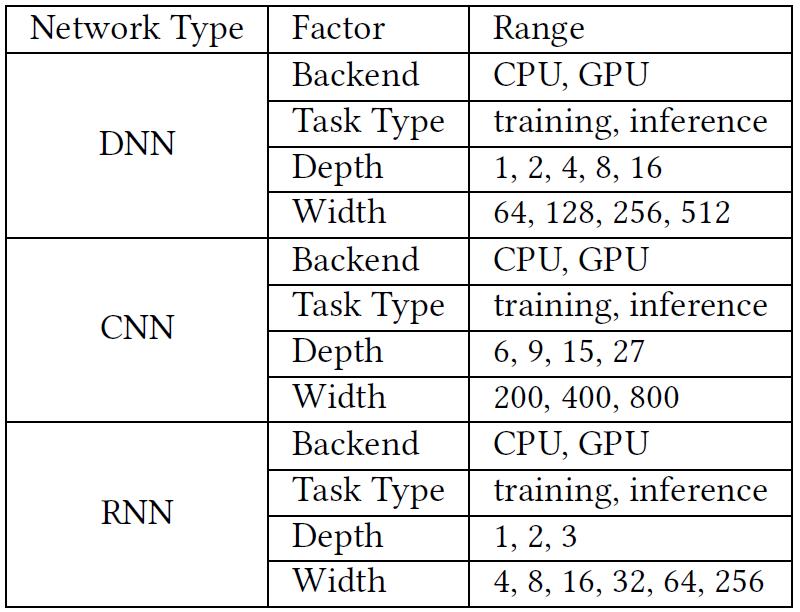
作者考虑 4 个影响 DL 在浏览器和原生平台上性能差距的因素,如表 5 所示,包括后端(CPU 或 GPU)、任务类型(训练或推理)以及模型的深度和宽度。在 DNN 和 RNN 模型中,宽度是指每层神经元的数目。在 CNN 模型中,宽度是指卷积层中使用的核数。对于 DNN、CNN 和 RNN,作者从 Tensorflow.js 官方样本示例中选取模型。DNN 和 CNN 模型用于识别 MNIST 数据集上的手写数字,RNN 模型用于从尼采的著作中生成文本。根据 Tensorflow.js 官方样本的数值集合确定深度和宽度的范围。
在本文实验中,作者使用不同配置的 TensorFlow.js 和原生 TensorFlow 运行 DNN、CNN 和 RNN 模型。作者将每个配置的执行时间衡量为两个平台上训练任务的每批平均时间和推理任务的每个样本平均时间。作者使用 TensorFlow.js 上的执行时间与原生 TensorFlow 上的执行时间之比来量化性能差距。
使用 sklearn 运行决策树算法来预测 TensorFlow.js 和原生 TensorFlow 之间的执行时间比。使用决策树描述贡献因素的相对重要性。直观地讲,靠近决策树根部的因素比靠近叶子的因素对时间比的影响更大,这是因为决策树是根据熵 - 信息增益标准(the Entropy-Information Gain criterion)选择对节点进行分割的。
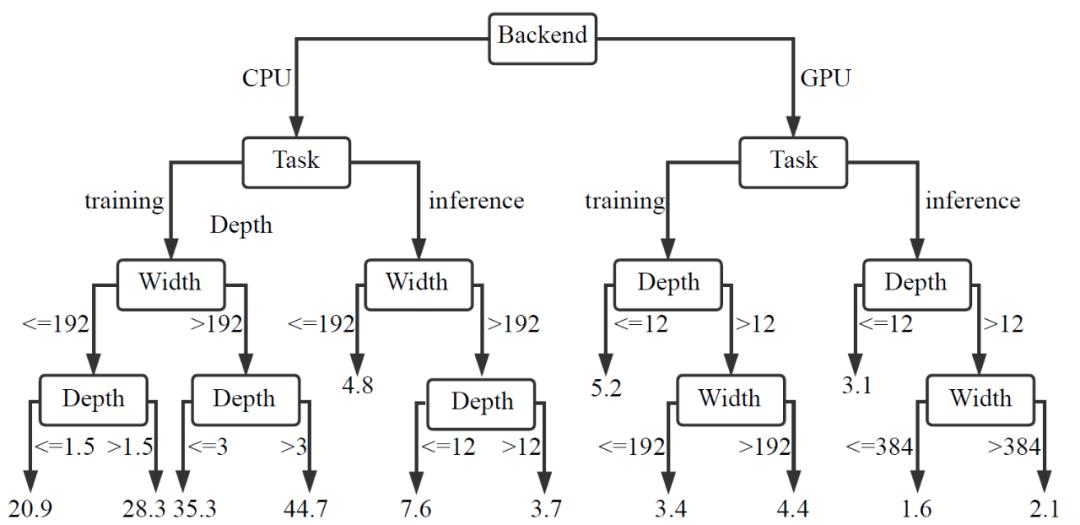
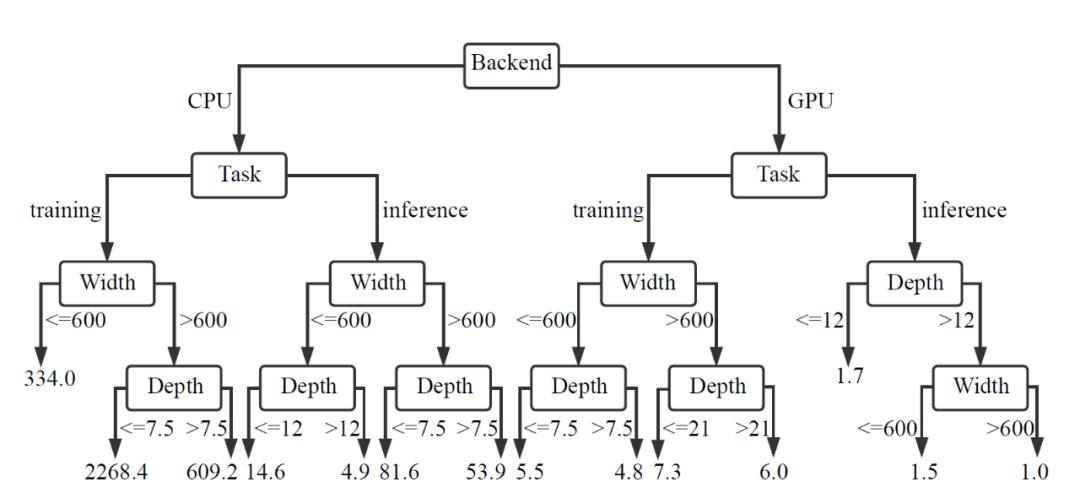
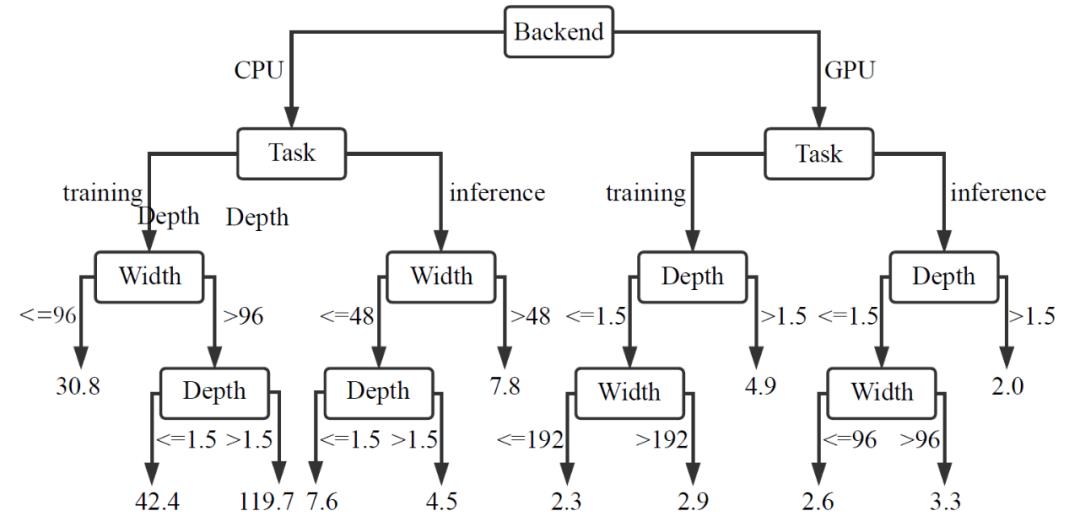
作者首先为所有因素生成一棵完全生长的、未经修剪的决策树。这样一来,每个叶子只包含一个配置。然后,将树的深度设置为因子的数量,以防止在一条路径上多次使用一个因子。图 6 显示了 DNN、CNN 和 RNN 的决策树。
图 6. 使用决策树来分析 TensorFlow.js 与原生 TensorFlow 在 DNN、CNN 和 RNN 模型上的时间比。
作者使用决策树算法来预测的总的结论是:
在几乎所有的配置中,TensorFlow.js 的执行时间都比原生 TensorFlow 长
。
首先,后端是造成不同的模型、平台性能差距的最重要因素。由图 6 中的实验结果可以看出,总的来说 CPU 后端的执行时间比 GPU 后端要长得多。例如,当深度超过 3、宽度超过 192 的 DNN 模型运行在 GPU 后端而不是 CPU 后端时,训练任务的比率从 44.7 下降到 4.4。最极端的例子发生在 CNN 上,在 CPU 后端,比率范围从低于 5 到超过 2200(当深度小于 7.5,宽度超过 600 时)。但是,当在 GPU 后端执行深度超过 12、宽度超过 600 的推理任务时,TensorFlow.js 执行速度与原生 TensorFlow 一样快。这是因为当模型足够大时,CNN 能够有效利用 GPU 强大的计算能力。
第二个重要因素是三个模型的任务类型。执行训练任务的比率较高,而推理任务的表现差距较小。例如,对于 CPU 后端的 DNN 模型,训练任务 TensorFlow.js 平均比原生 TensorFlow 慢 33.9 倍,推理任务 TensorFlow.js 执行速度比原生 TensorFlow 平均慢 5.8 倍。
最后,DNN 和 RNN 的决策树都表明,深度和宽度的重要性取决于任务在哪个后端执行。在 CPU 后端,宽度的重要性大于深度的重要性,而深度在 GPU 后端扮演更重要的角色。然而,在 CNN 的情况下,对于训练任务来说,宽度比深度对性能差距的影响更大。表 6 总结了上述实验的研究结果。
TensorFlow.js 是一个使用 JavaScript 进行机器学习开发的库,TensorFlow.js 的中文教程网址如下:https://tensorflow.google.cn/js,教程通过完整的端到端示例详细展示了如何使用 TensorFlow.js。TensorFlow.js 提供了图像分类、对象检测、姿态估计、文本恶意检测、语音指令识别、人脸识别、语义分割等丰富的开箱即用的模型。
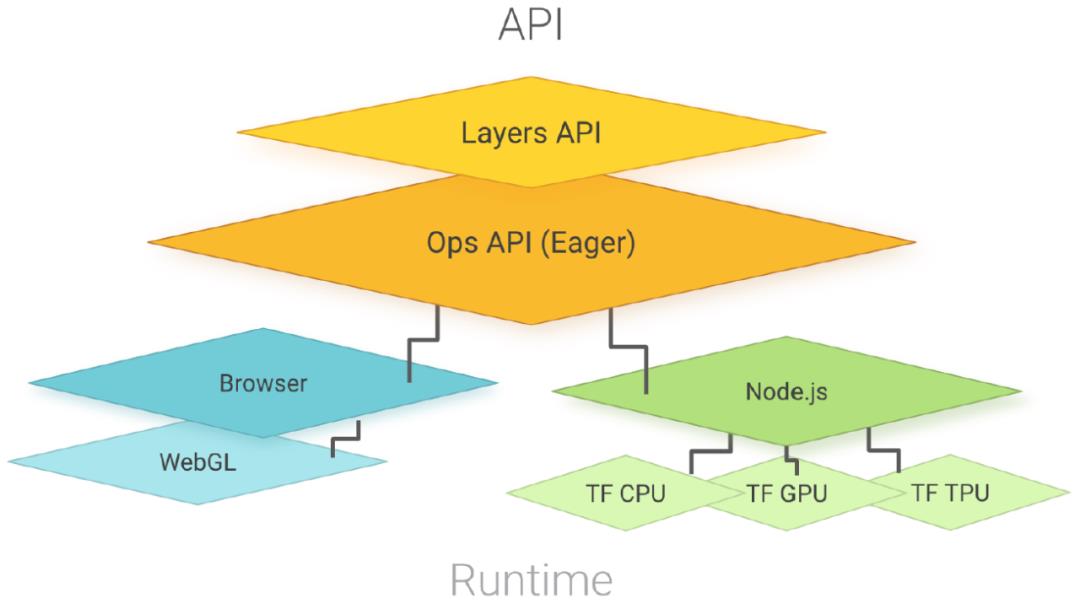
TensorFlow.js 的 API 主要是以 TensorFlow 为蓝本,并添加一些针对 JS 环境的例外。和 TensorFlow 一样,其核心数据结构是 Tensor。TensorFlow.js API 提供了从 JS 数组创建张量的方法,以及对张量进行操作的数学函数。图 7 给出 TensorFlow.js 的结构示意图。TensorFlow.js 由两组 API 组成:提供了低层次的线性代数操作(如矩阵乘法、张量加法等)的 Ops API 和被设计为在浏览器和服务器端运行的 TensorFlow.js。在浏览器内部运行时,它通过 WebGL 利用设备的 GPU 来实现快速并行化浮点计算。在 Node.js 中,TensorFlow.js 与 TensorFlow C 库绑定,可以完全访问 TensorFlow。TensorFlow.js 还提供了一个较慢的 CPU 实现作为后备(为简单起见图 7 中省略),用纯 JS 实现。这个后备设置可以在任何执行环境中运行,当环境无法访问 WebGL 或 TensorFlow 二进制时,会自动使用。
图 7. TensorFlow.js 的结构示意图。
TensorFlow.js 提供了 Layers API,它尽可能地镜像了 Keras API,包括序列化格式。这实现了 Keras 和 TensorFlow.js 之间的双向门:用户可以在 TensorFlow.js 中加载一个预先训练好的 Keras 模型,对其进行修改、序列化,然后在 Keras Python 中加载回来。
和 TensorFlow 一样,TensorFlow.js 的一个操作代表了一个抽象的计算 (例如矩阵乘法),它独立于它所运行的物理设备。操作调用到内核,内核是数学函数的特定设备实现。为了支持特定设备的内核实现,Tensor-Flow.js 有一个 Backend 的概念。Backend 实现了内核以及方法,如 read() 和 write(),这些方法用于存储支持张量的 TypedArray。张量与支持它们的数据是解耦的,因此像 reshape 和 clone 这样的操作实际上是自由的。
此外,TensorFlow.js 还支持自动微分,提供一个 API 来训练模型和计算梯度。在讨论 TensorFlow.js 中的自动微分问题之前,让我们先来回顾一下常见的自动微分方法。目前有两种常见的自动微分方法:Graph-based 和 eager。Graph-based 引擎提供了一个 API 来构造一个计算图,并在之后执行。在计算梯度时,引擎会静态分析 Graph 来创建一个额外的梯度计算 Graph。这种方式的性能比较好,而且容易实现序列化。而 eager 微分引擎则采取了不同的方式。在 eager 模式下,当一个操作被调用时,立即进行计算,这可以很容易的通过 Print 或使用 debugger 来检查结果。另一个好处是,当模型在执行时,主机语言的所有功能都是可用的。用户可以使用原生的 if 和 while 循环,而不需要使用专门的控制流 API。TensorFlow.js 的设计目标是优先考虑易用性而不是性能,所以 TensorFlow.js 支持 eager 自动微分方法。
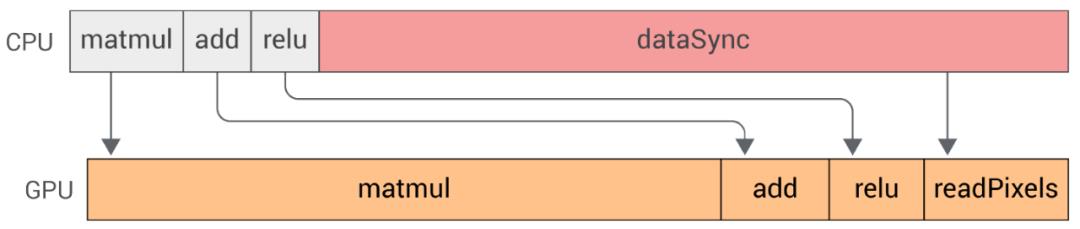
TensorFlow.js 实现了平衡同步函数的简单性和异步函数的优点。例如,像 tf.matMul()这样的操作是同步执行的并返回一个可能未计算的张量。这样用户就可以写出常规的同步代码,便于调试。当用户需要检索支持张量的数据时,TensorFlow.js 提供了一个异步的 tensor.data()函数,该函数返回一个承诺(promise),当操作完成后,该承诺会被解析。因此,异步代码的使用可以本地化到一个 data()的调用。用户还可以选择调用 tensor.dataSync(),这是一个阻塞调用(Blocking Call)。图 8 和图 9 分别说明了在浏览器中调用 tensor.dataSync()和 tensor.data()的时间线。
图 8. 浏览器中同步和阻塞张量的时间轴,dataSync(),主线程阻塞,直到 GPU 完成执行操作。
图 9. 浏览器中对 data()的异步调用的时间轴。当 GPU 执行操作时,主线程被释放,当张量准备好并下载时,解析 data()承诺。
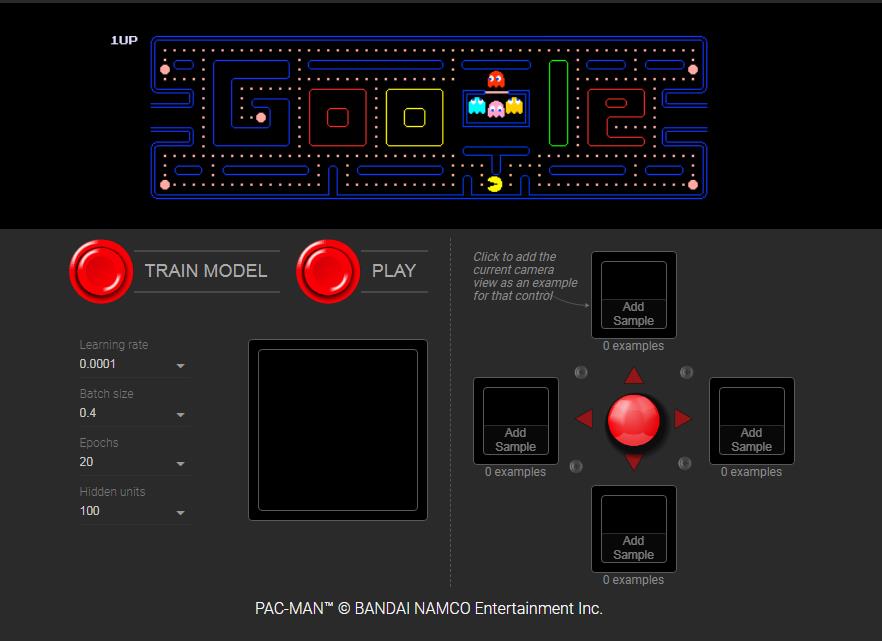
TensorFlow.js 的官网上提供了多个在浏览器中运行的在线演示和示例。比如,下面是一个通过网络摄像头玩 Pacman 游戏,使用一个预先训练好的 MobileNet 模型,并使用内部的 MobileNet 激活训练另一个模型,从用户定义的网络摄像头中预测 4 个不同的类。
下面的示例在 TensorFlow 中对钢琴演奏的 MIDI 进行了 Performance RNN 训练。然后,它被移植到浏览器中,在 TensorFlow.js 环境中仅使用 Javascript 运行。钢琴样本来自 Salamander Grand Piano。TensorFlow.js 的中文网站上还有其它有趣的示例,大家可以直接上去尝试一下。
由斯坦福大学开发的 ConvNetJS 是一个可在浏览器中运行的 Javascript 深度学习框架。尽管它已经不在更新了,我们还是把它放在这里做一个示例性介绍,因为它真的是一款接口好用、简便可操作的 DL 框架,非常适合正在入门深度学习的人。在 PC 端的浏览器中,直接下载 js 即可,convnet.js (http://cs.stanford.edu/people/karpathy/convnetjs/build/convnet.js)或 convnet-min.js (http://cs.stanford.edu/people/karpathy/convnetjs/build/convnet-min.js),二选一。
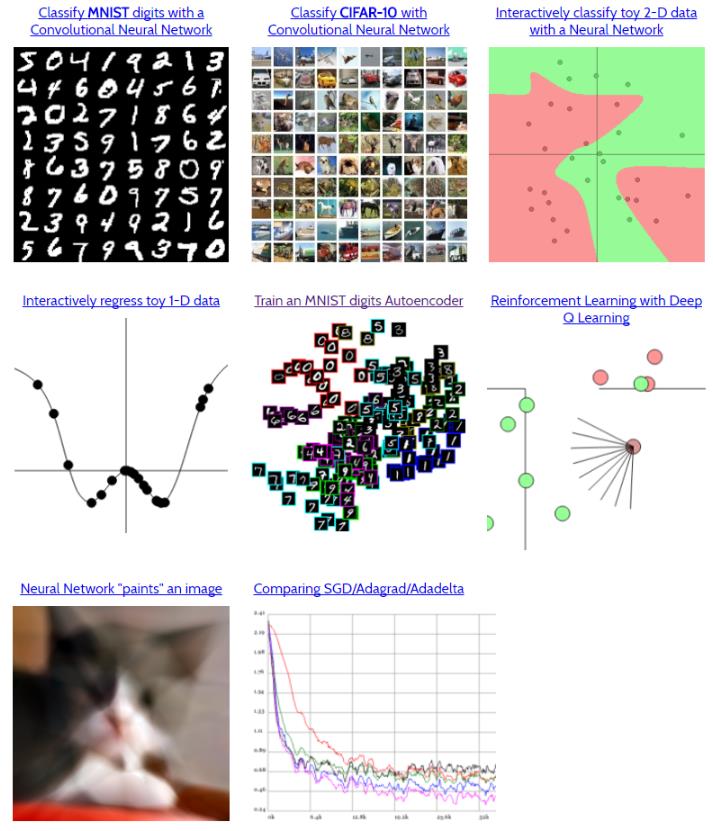
ConvNetJS 的官网上提供了分类 (Classifier)、回归(Regression)、自编码器(AutoEncoder) 等示例。
这些示例并不需要消耗很多资源,在普通 PC 的浏览器中,运行一两分钟就可以初步进行分类等操作。我们从网站上选择了一些分类示例如下。更多的示例可以直接到网站上下载,大家也可以尝试直接用自己的浏览器搭建一个 DL 模型。
最后,我们来介绍一下 Paddle.js。2020 年 5 月,百度飞桨联手百度 APP 技术团队开源了飞桨前端推理引擎 Paddle.js。Paddle.js 是百度 Paddle 的 web 方向子项目,是一个运行在浏览器中的开源深度学习框架,也是国内首个开源的机器学习 Web 在线预测方案。Paddle.js 可以加载训练好 Paddle.js 模型,或者将 Paddle.fluid 模型通过 Paddle.js 的模型转换工具变成浏览器友好的模型进行在线预测使用。
目前,Paddle.js 支持在 webGL2.0 和 webGL1.0 的浏览器上运行。包括 PC 端的 chrome, firefox, safari 以及移动端的 Baidu App, QQ 浏览器等。支持 NCHW 与 NHWC 格式的模型数据计算。Paddle.js 提供了丰富的模型资源库,同时也提供了模型转换工具可将 Paddle 模型变成 Web 可用模型(https://github.com/PaddlePaddle/Paddle.js/blob/master/tools/ModelConverter/README_cn.md)。Paddle.js 支持有限的算子,如果模型中使用了不支持的操作,那么 Paddle.js 将运行失败并提示模型中有哪些算子目前还不支持。
Paddle.js 使用现成的 JavaScript 模型或将其转换为可在浏览器中运行的 paddel 模型。目前,小型 Yolo 模型可在 30ms 内运行完毕,可以满足一般的实时场景需求。Paddel.js 的部署示例如下,Github 上有完整的部署过程说明,大家也可以去试用一下。
本文我们基于 WWW’19 论文提供的线索,详细地了解了在浏览器中实现深度学习的可能性、可行性和性能现状。具体地,重点分析了 7 个最近出现的基于 JavaScript 的 DL 框架,并对比了具体框架支持哪些 DL 任务。文中的实验将不同任务中浏览器 DL 和原生 DL 的性能进行比较。虽然,目前关于浏览器中实现 DL 的研究仍然处于早期阶段,但是,从本文的研究中仍然可以看出浏览器 DL 框架有很多很好的表现。例如,在完成某些任务时 JavaScript 的 DL 性能要优于原生 DL,浏览器 DL 框架能够有效利用集成显卡等等。
当然,目前浏览器中的 DL 框架还有着很大的改进空间,距离大规模的推广和应用还有很大差距。但是,随着硬件设备的不断改进、性能的不断提升,浏览器本身的性能和智能化水平都在不断的提高。相应的,浏览器中的 DL 框架的性能也会越来越好。由上文的分析,我们认为,未来浏览器中 DL 框架的发展可以沿着多个方向:一是,可以提升浏览器中 DL 框架的执行性能,使其能够满足实时性的应用需求;二是,可以不断完善和增加浏览器中 DL 框架所适用的任务场景;三是,可以继续完善上下游的工具链,提升浏览器中 DL 框架的易用性,降低使用成本。
最后,无论对于 AI 还是对于 web 浏览器,浏览器中的 DL 框架的发展都会对其产生深远的影响。我们希望,关于浏览器中实现深度学习的探索工作可以为人工智能时代的 Web 应用的未来提供一点启示。
[1] Yun Ma, Dongwei Xiang, Shuyu Zheng, Deyu Tian, Xuanzhe Liu, Moving Deep Learning into Web Browser: How Far Can We Go? WWW '19: The World Wide Web Conference, May 2019 Pages 1234–1244, https://dl.acm.org/doi/abs/10.1145/3308558.3313639
[2] 2018. TensorFlow.js. https://js.tensorflow.org/.
Smilkov et al., TensorFlow.js: Machine Learning for the Web and Beyond, SysML’19.
[3] 2020. ConvNetJS. https://cs.stanford.edu/people/karpathy/convnetjs/, https://github.com/karpathy/convnetjs.
[4] 2020. Keras.js. https://github.com/transcranial/keras-js.
[5] 2020. MIL WebDNN Benchmark. https://mil-tokyo.github.io/webdnn/#benchmar.
[6] 2020. brain.js. https://github.com/BrainJS.
[7] 2020. synaptic.js. https://github.com/cazala/synaptic.
[8] 2020. Mind. https://github.com/stevenmiller888/mind.
[9] 2020. Paddle.js. https://github.com/paddlepaddle/paddle.js/releases.
仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为
模式识别
、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库
感兴趣加入机器之心全球分析师网络?点击 阅读原文 ,提交申请。
以上是关于浏览器中实现深度学习?有人分析了7个基于JS语言的DL框架,发现还有很长的路要走的主要内容,如果未能解决你的问题,请参考以下文章
《基于深度学习的自然语言处理》中文PDF+英文PDF+学习分析
CentOS中实现基于Docker部署BI数据分析
深度学习时代的图模型,清华发文综述图网络
深度学习第48讲:自然语言处理之情感分析
如何在电子中实现延迟深度链接
如何在深度学习框架中实现LSTM?