如何在深度学习框架中实现LSTM?
Posted 广东互动学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在深度学习框架中实现LSTM?相关的知识,希望对你有一定的参考价值。

长短期记忆(LSTM)是目前循环神经网络最普遍使用的类型,在处理时间序列数据时使用最为频繁。关于 LSTM 的更加深刻的洞察可以看看这篇优秀的博客:http://colah.github.io/posts/2015-08-Understanding-LSTMs/。
目的
本文的主要目的是使读者熟悉在 TensorFlow 上实现基础 LSTM 神经网络的详细过程。我们将选用 MNIST 作为数据集。
MNIST 数据集
MNIST 数据集包括手写数字的图像和对应的标签。我们可以根据以下内置功能从 TensorFlow 上下载并读取数据。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
数据被分成 3 个部分:
1. 训练数据(mnist.train):55000 张图像
2. 测试数据(mnist.test):10000 张图像
3. 验证数据(mnist.validation):5000 张图像
数据的形态
讨论一下 MNIST 数据集中的训练数据的形态。数据集的这三个部分的形态都是一样的。
训练数据集包括 55000 张 28x28 像素的图像,这些 784(28x28)像素值被展开成一个维度为 784 的单一向量,所有 55000 个像素向量(每个图像一个)被储存为形态为 (55000,784) 的 numpy 数组,并命名为 mnist.train.images。
所有这 55000 张图像都关联了一个类别标签(表示其所属类别),一共有 10 个类别(0,1,2...9),类别标签使用独热编码的形式表示。因此标签将作为形态为 (55000,10) 的数组保存,并命名为 mnist.train.labels。
为什么要选择 MNIST?
LSTM 通常用来解决复杂的序列处理问题,比如包含了 NLP 概念(词嵌入、编码器等)的语言建模问题。这些问题本身需要大量理解,那么将问题简化并集中于在 TensorFlow 上实现 LSTM 的细节(比如输入格式化、LSTM 单元格以及网络结构设计),会是个不错的选择。
MNIST 就正好提供了这样的机会。其中的输入数据是一个像素值的集合。我们可以轻易地将其格式化,将注意力集中在 LSTM 实现细节上。
实现
在动手写代码之前,先规划一下实现的蓝图,可以使写代码的过程更加直观。
VANILLA RNN
循环神经网络按时间轴展开的时候,如下图所示:
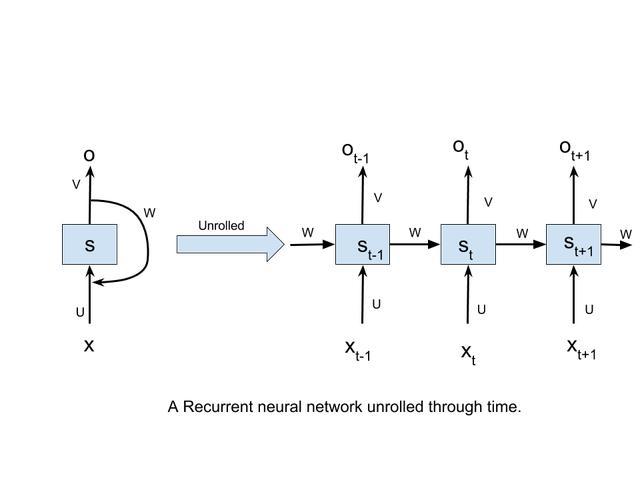
图中,
1.x_t 代表时间步 t 的输入;
2.s_t 代表时间步 t 的隐藏状态,可看作该网络的「记忆」;
3.o_t 作为时间步 t 时刻的输出;
4.U、V、W 是所有时间步共享的参数,共享的重要性在于我们的模型在每一时间步以不同的输入执行相同的任务。
当把 RNN 展开的时候,网络可被看作每一个时间步都受上一时间步输出影响(时间步之间存在连接)的前馈网络。
两个注意事项
为了更顺利的进行实现,需要清楚两个概念的含义:
1.TensorFlow 中 LSTM 单元格的解释;
2. 数据输入 TensorFlow RNN 之前先格式化。
TensorFlow 中 LSTM 单元格的解释
在 TensorFlow 中,基础的 LSTM 单元格声明为:
tf.contrib.rnn.BasicLSTMCell(num_units)
这里,num_units 指一个 LSTM 单元格中的单元数。num_units 可以比作前馈神经网络中的隐藏层,前馈神经网络的隐藏层的节点数量等于每一个时间步中一个 LSTM 单元格内 LSTM 单元的 num_units 数量。下图可以帮助直观理解:
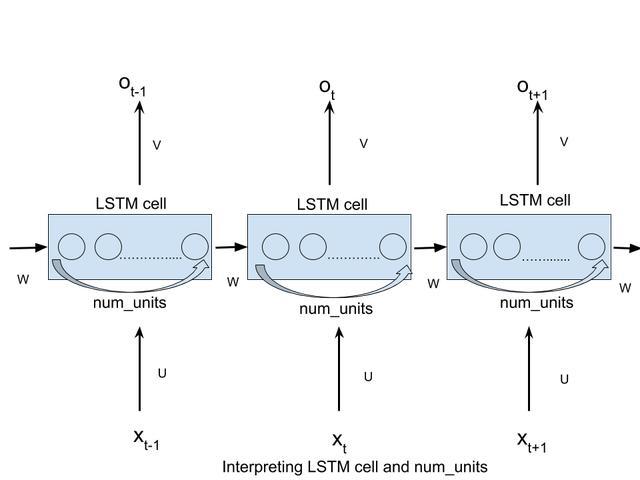
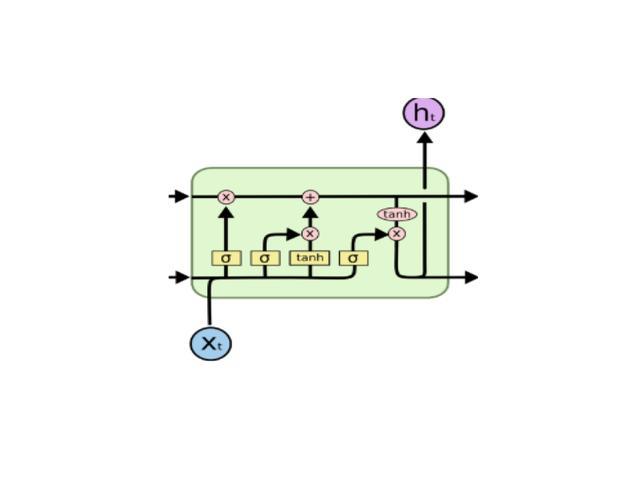
每一个 num_units LSTM 单元都可以看作一个标准的 LSTM 单元:
数据输入 TensorFlow RNN 之前先格式化
在 TensorFlow 中最简单的 RNN 形式是 static_rnn,在 TensorFlow 中定义如下:
tf.static_rnn(cell,inputs)
虽然还有其它的注意事项,但在这里我们仅关注这两个。
inputs 引数接受形态为 [batch_size,input_size] 的张量列表。列表的长度为将网络展开后的时间步数,即列表中每一个元素都分别对应网络展开的时间步。比如在 MNIST 数据集中,我们有 28x28 像素的图像,每一张都可以看成拥有 28 行 28 个像素的图像。我们将网络按 28 个时间步展开,以使在每一个时间步中,可以输入一行 28 个像素(input_size),从而经过 28 个时间步输入整张图像。给定图像的 batch_size 值,则每一个时间步将分别收到 batch_size 个图像。详见下图说明:
由 static_rnn 生成的输出是一个形态为 [batch_size,n_hidden] 的张量列表。列表的长度为将网络展开后的时间步数,即每一个时间步输出一个张量。在这个实现中我们只需关心最后一个时间步的输出,因为一张图像的所有行都输入到 RNN,预测即将在最后一个时间步生成。
现在,所有的困难部分都已经完成,可以开始写代码了。只要理清了概念,写代码过程是很直观的。
代码
在开始的时候,先导入一些必要的依赖关系、数据集,并声明一些常量。设定 batch_size=128 、 num_units=128。
import tensorflow as tffrom tensorflow.contrib import rnn
#import mnist datasetfrom tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("/tmp/data/",one_hot=True)#define constants#unrolled through 28 time steps
time_steps=28#hidden LSTM units
num_units=128#rows of 28 pixels
n_input=28#learning rate for adam
learning_rate=0.001#mnist is meant to be classified in 10 classes(0-9).
n_classes=10#size of batch
batch_size=128
现在设置占位、权重以及偏置变量(用于将输出的形态从 [batch_size,num_units] 转换为 [batch_size,n_classes]),从而可以预测正确的类别。
#weights and biases of appropriate shape to accomplish above task
out_weights=tf.Variable(tf.random_normal([num_units,n_classes]))
out_bias=tf.Variable(tf.random_normal([n_classes]))#defining placeholders#input image placeholder
x=tf.placeholder("float",[None,time_steps,n_input])#input label placeholder
y=tf.placeholder("float",[None,n_classes])
现在我们得到了形态为 [batch_size,time_steps,n_input] 的输入,我们需要将其转换成形态为 [batch_size,n_inputs] 、长度为 time_steps 的张量列表,从而可以将其输入 static_rnn。
#processing the input tensor from [batch_size,n_steps,n_input] to "time_steps" number of [batch_size,n_input] tensors
input=tf.unstack(x ,time_steps,1)
现在我们可以定义网络了。我们将利用 BasicLSTMCell 的一个层,将我们的 static_rnn 从中提取出来。
#defining the network
lstm_layer=rnn.BasicLSTMCell(n_hidden,forget_bias=1)
outputs,_=rnn.static_rnn(lstm_layer,input,dtype="float32")
我们只考虑最后一个时间步的输入,从中生成预测。
#converting last output of dimension [batch_size,num_units] to [batch_size,n_classes] by out_weight multiplication
prediction=tf.matmul(outputs[-1],out_weights)+out_bias
定义损失函数、优化器和准确率。
#loss_function
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=y))#optimization
opt=tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)#model evaluation
correct_prediction=tf.equal(tf.argmax(prediction,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
现在我们已经完成定义,可以开始运行了。
#initialize variables
init=tf.global_variables_initializer()with tf.Session() as sess:
sess.run(init)
iter=1while iter<800:
batch_x,batch_y=mnist.train.next_batch(batch_size=batch_size)
batch_x=batch_x.reshape((batch_size,time_steps,n_input))
sess.run(opt, feed_dict={x: batch_x, y: batch_y})if iter %10==0:
acc=sess.run(accuracy,feed_dict={x:batch_x,y:batch_y})
los=sess.run(loss,feed_dict={x:batch_x,y:batch_y})print("For iter ",iter)print("Accuracy ",acc)print("Loss ",los)print("__________________")
iter=iter+1
需要注意的是我们的每一张图像在开始时被平坦化为 784 维的单一向量,函数 next_batch(batch_size) 必须返回这些 784 维向量的 batch_size 批次数。因此它们的形态要被改造成 [batch_size,time_steps,n_input],从而可以被我们的占位符接受。我们还可以计算模型的准确率:
#calculating test accuracy
test_data = mnist.test.images[:128].reshape((-1, time_steps, n_input))
test_label = mnist.test.labels[:128]print("Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label}))
在运行的时候,模型的测试准确率为 99.21%。
以上是关于如何在深度学习框架中实现LSTM?的主要内容,如果未能解决你的问题,请参考以下文章
深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.