深度学习第48讲:自然语言处理之情感分析
Posted 机器学习实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习第48讲:自然语言处理之情感分析相关的知识,希望对你有一定的参考价值。
情感分析也叫观点挖掘,是基于人们对产品、服务、组织、个人、问题、事件、话题和属性等文本资料挖掘人们的观点、倾向、情绪、态度和评价的一种分析方法。早在在深度学习兴起之前,就已经有了众多可解决情感分析的 NLP 技术,但随着 NLP 领域开始应用深度学习技术,深度学习再情感分析中也有着广泛的应用。
基于语料粒度的不同,可以将情感分析细分到文档级、语句级和 aspect level。文档级的情感分析以整个文档为单位,但前提是文档需要有明确的态度,即观点要鲜明。而语句级的情感分析则是对文档内的语句单独进行情感分析。aspect level 情感分析相较于文档级和语句级则更加细粒化,它的任务是提取和总结人们对某实体的观点以及实体(也被称为目标)的特征。例如一篇产品评论,aspect level 情感分析的目的是分别总结对产品不同方面的积极和消极观点,虽然对产品的总体情感可能是倾向积极的或消极的。
目前基于深度学习的情感分析主要方法:
本篇笔者以 kaggle 电影评论数据集为例,展示基于深度学习的情感分析过程。
训练数据展示如下: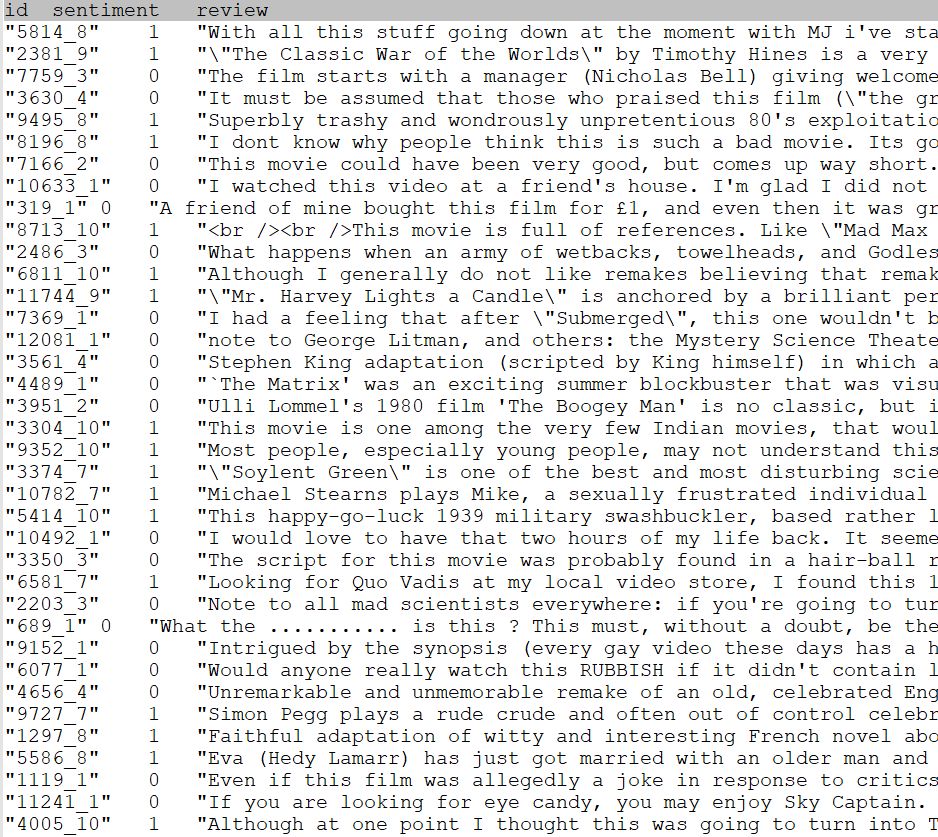
其中数据每一条记录就是一个电影评论,1代表正面评价,0代表负面评价。所以,从本质上看,这就是一个相对简单的本文二分类问题。
原始评论文本的清洗
读入训练集和测试集如下:
import numpy as np
import pandas as pd
import warnings warnings.filterwarnings('ignore') train = pd.read_csv('./data/labeledTrainData.tsv/labeledTrainData.tsv', header=0, delimiter=" ", quoting=3) test = pd.read_csv('./data/testData.tsv/testData.tsv', header=0, delimiter=" ", quoting=3) print('trainset shape is', train.shape) print('testset shape is', test.shape)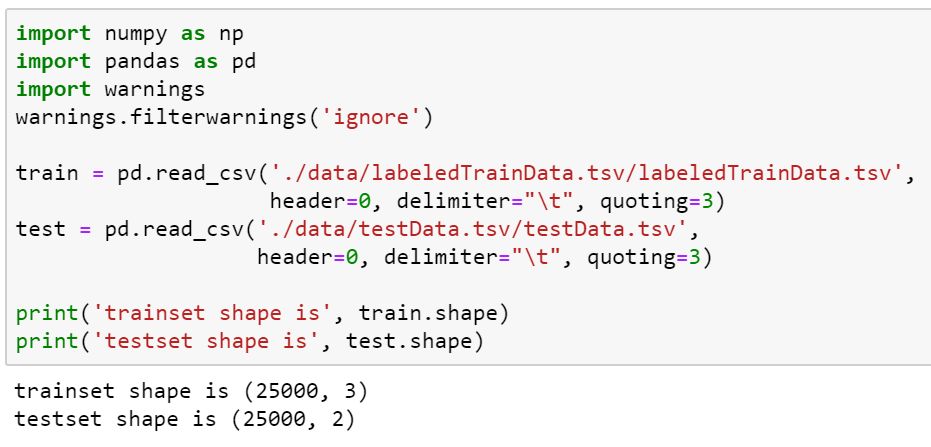
查看训练集和测试集数据:
尝试查看一条完整的评论样本:
train['review'][0]
可以发现原始的评论文本中有大量的html标记符号,所以我们使用 BeautifulSoup 的解析库对其进行清理:
from bs4 import BeautifulSoup example = BeautifulSoup(train['review'][0]) print(example.get_text()) 清洗的示例文本如下:
然后我们可以通过正则表达式清除掉一些标点等非字母字符:
import re letters_only = re.sub('[^A-Za-z]', ' ', example.get_text()) print(letters_only)
然后我们将评论文本中的大写字母都转为小写,并将文本转化为单词列表:
lower_case = letters_only.lower() words = lower_case.split() print(words)
此时文本中还包含了大量的停用词,我们可以使用nltk中的停用词库进行筛选:
from nltk.corpus import stopwords words = [word for word in words if word not in stopwords.words("english")]
' '.join(words)
最后我们可以定义文本清洗函数来总结整个清洗过程:
def review_to_words(raw_review):
# 1. Remove HTML review_text = BeautifulSoup(raw_review).get_text() # 2. Remove non-letters letters_only = re.sub("[^a-zA-Z]", " ", review_text) # 3. Convert to lower case, split into individual words words = letters_only.lower().split() # 4. In Python, searching a set is much faster than searching stops = set(stopwords.words("english")) # 5. Remove stop words meaningful_words = [w for w in words if not w in stops] # 6. Join the words back into one string separated by space, # and return the result. return( " ".join(meaningful_words))对训练数据进行遍历批量清洗评论:
clean_train_reviews = [] num_reviews = train["review"].size
for i in range(num_reviews):
if( (i+1)%1000 == 0 ): print("Review %d of %d
" % (i+1, num_reviews)) clean_train_reviews.append(review_to_words(train['review'][i]))文本的标记化
经过清洗的数据还需要经序列和标记化处理才能够拿来建模处理。本文使用 keras 中的文本和序列预处理模块进行处理:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences max_features = 6000
tokenizer = Tokenizer(num_words=max_features) tokenizer.fit_on_texts(clean_train_reviews) tokenized_train = tokenizer.texts_to_sequences(clean_train_reviews) tokenized_train[0]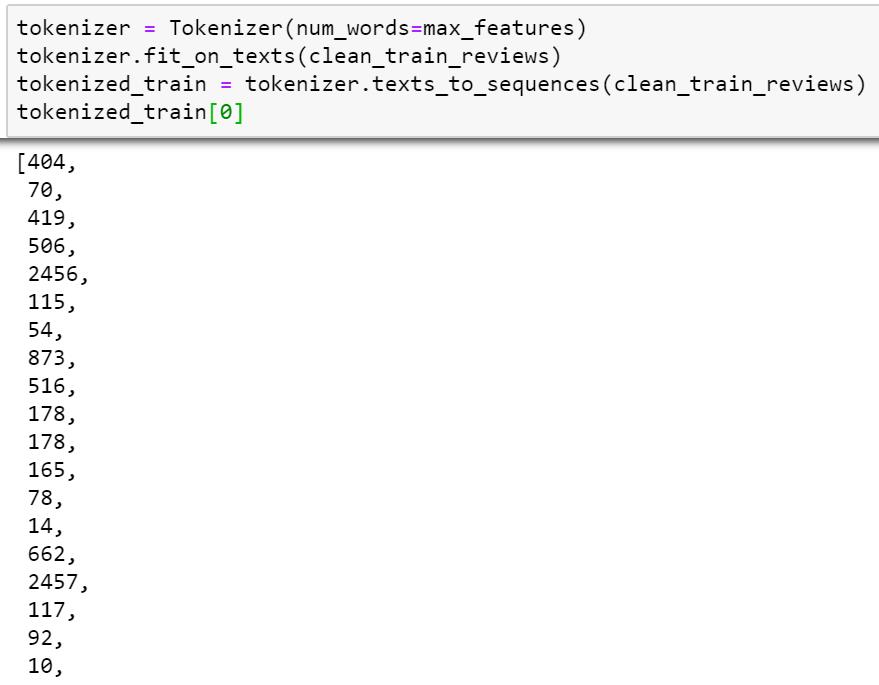
然后使用pad_sequence方法将一维序列转化为二维序列:
maxlen = 400
X_train = pad_sequences(tokenized_train, maxlen=maxlen) X_train.shape
构建深度学习模型
序列化和标记化处理完了之后就可以进行建模了,使用keras搭建模型如下:
from keras.layers import Dense, Input, LSTM, Embedding, Dropout, Activation
from keras.layers import Bidirectional, GlobalMaxPool1D
from keras.models import Modelfrom keras import initializers, regularizers, constraints, optimizers, layers
from keras.utils import to_categorical inp = Input(shape=(maxlen, )) embed_size = 128x = Embedding(max_features, embed_size)(inp) x = LSTM(60, return_sequences=True, name='lstm_layer')(x) x = GlobalMaxPool1D()(x) x = Dropout(0.2)(x) x = Dense(50, activation="relu")(x) x = Dropout(0.2)(x) x = Dense(1, activation="sigmoid")(x) model = Model(inputs=inp, outputs=x) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])模型概览如下:
然后将标签进行分类化处理就可以开始模型训练了:
train['sentiment'] = to_categorical(train['sentiment'], num_classes=2) batch_size = 32
epochs = 5
model.fit(X_train, train['sentiment'], batch_size=batch_size, epochs=epochs, validation_split=0.2)训练示例如下:
5轮之后的训练集准确率达到0.97,验证集相对较低,只有0.86,所以还存在一定的提升空间。关于基于深度学习的情感分析模型搭建过程就介绍到这,模型的提升和细化各位可自行尝试。
参考资料:
https://www.kaggle.com/c/word2vec-nlp-tutorial
https://github.com/luwill/Attention_Network_With_Keras
https://www.jiqizhixin.com/articles/Deep-Learning-for-Sentiment-Analysis
往期精彩:
一个数据科学从业者的学习历程

长按二维码.关注机器学习实验室
以上是关于深度学习第48讲:自然语言处理之情感分析的主要内容,如果未能解决你的问题,请参考以下文章