BigDL:用于大数据的分布式深度学习框架
Posted AI菜鸟成长日志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BigDL:用于大数据的分布式深度学习框架相关的知识,希望对你有一定的参考价值。
摘要
在本文中,作者提出了用于大数据平台和大数据工作流的分布式深度学习框架BigDL。它是基于Apache Spark实现的,允许用户将其深度学习应用程序编写为标准的Spark程序(以分布式方式直接在大型数据集群上运行)。它提供了一个富有表现力的“数据分析集成”("data-analytics integrated")的深度学习编程模型,以便用户可以在统一的编程范例下轻松地构建端到端分析+人工智能流程("analytics + AI pipelines");通过使用Spark(例如,shuffle, broadcast, and in-memory data persistence)中的现有原语实现类似AllReduce的操作,它还提供一种高效的“参数服务器”("parameter server")式体系结构,以实现高度可扩展、数据并行的分布式训练。自从它的开源版本发布以来,BigDL用户已经在Spark上建立了许多分析和深度学习应用程序(例如,目标检测、seq2seq生成、视觉相似性、神经推荐、欺诈检测等)。
1.引言
最近人工智能的突破已经将深度学习带到了新一代数据分析的前沿;随着需求和使用模型的扩展,不可避免地出现了超出现有深度学习框架(例如,Caffe、Torch、TensorFlow、MXNet、Chainer等)的新系统和体系结构。尤其是,组织越来越需要将深度学习技术(如计算机视觉、自然语言处理、生成性对抗网络等)应用到其大型数据平台和流水线上。深层学习和大数据分析的这种新兴的融合是由若干重要技术和行业趋势驱动的:
数据规模驱动深度学习过程。今天,用户正在构建更深、更复杂的神经网络,以利用他们能够访问的大量数据。在实践中,大数据(例如,Apache Hadoop或Apache Spark)集群被普遍部署为全局数据平台,其中存储所有生产数据并使所有用户可用。因此,通常在存储和共享数据的大数据集群上直接运行机器学习算法会比将数据复制到单独的基础设施更为有效。
现实中深层学习应用是一个复杂的大数据流水线,除了模型训练/推理外,还需要大量的数据处理(如清理、转换、增强、特征提取等)。因此,将深层学习功能无缝地集成到运行在相同基础设施上的现有大数据工作流中(对于开发和工作流管理)要简单得多,而且效率也更高,特别是最近的bigDL的改进将深层学习训练时间从几周减少到几小时甚至几分钟。
深度学习日益被大数据和数据科学界采用。不幸的是,主流的数据工程师和数据科学家通常不是深度学习专家;随着深度学习的使用扩展并扩展到更大的部署,如果这些用户可以继续使用熟悉的软件工具和编程模型(例如,Spark或甚至SQL)以及现有大型数据集群,将会更加容易构建其深度学习应用。
因此BigDL问世了,这是一个用于大型数据平台和工作流的分布式深度学习框架。它是基于Apache Spark之上的一个库,并允许用户将其大规模的深度学习应用程序(包括模型训练、微调和推理)编写为标准Spark程序,该程序可以直接在现有的大数据(Hadoop或Spark)集群上运行。BigDL为深度学习技术(神经网络操作、层、损失和优化器)提供了全面的支持;特别是,用户可以以分布式方式直接运行Spark上的其他框架(如TensorFlow、Keras、Caffe和Torch)中定义的现有模型。
BigDL还提供深层学习技术到大数据生态系统的无缝集成。BigDL程序不仅可以直接与Spark框架中的不同组件(例如,DataFrames、Spark Streaming、ML Pipelines等)交互,还可以直接运行在各种大型数据框架中(例如,Apache Storm、ApacheFlink、Apache Kafka等)。自2016年12月30日首次开放源码以来,BigDL已经使许多社区用户能够在Spark和大型数据平台上构建其深度学习应用程序(例如,对象检测、seq2seq生成、视觉相似性、神经推荐、欺诈检测等)。
2.编程模型
BigDL是在Apache Spark上实现的,Apache Spark是广泛使用的用于大数据分析的集群计算引擎。Spark为关系处理、流媒体、图形处理(16)和机器学习(Python、Scala或Java)提供了一套全面的库;因此,可以使用Spark和BigDL轻松地构建端到端的“数据分析集成”深度学习和人工智能流水线(在统一编程范式下),如下代码所示。Spark和BigDL上的端到端文本分类流水线(包括数据加载、标记化、字向量化、训练、预测等)。
spark = SparkContext(appName="text_classifier", …)
//load input data: (text, label) pairs
texts_rdd = spark.textFile("hdfs://...")
//convert text to list of words
words_rdd = texts_rdd.map(lambda text, label:
([w for w in to_words(text)], label))
//load GloVe embedding
w2v = news20.get_glove_w2v(dim=…)
//convert word list to list of vertors using GloVe embeddings
vector_rdd = words_rdd.map(lambda word_list, label:
([to_vec(w, w2v) for w in word_list], label))
//convert (list of vertors, label) pair to Sample
sample_rdd = vector_rdd.map(lambda vector_list, label:
to_sample(vector_list, label))
//construct neural network model
model = Sequential().add(Recurrent().add(LSTM(…)))
.add(Linear(…))
.add(LogSoftMax())
//train the model
loss = ClassNLLCriterion()
optim_method = Adagrad()
optimizer = Optimizer(model=model, training_rdd=sample_rdd,
criterion=loss, optim_method= optim_method, …)
optimizer.set_train_summary(summary = TrainSummary(…))
trained_model =optimizer.optimize()
//model prediction
test_rdd = …
prediction_rdd = trained_model.predict(test_rdd)
2.1. Spark
Spark在内存存储抽象中提供了弹性分布式数据集(RDD),这是一个不可分割的跨集群划分的Python或Scala/Java对象的集合,并且可以被转换为通过数据并行功能操作符(如MAP、过滤器和Read)派生新的RDD。因此,用户可以高效地加载非常大的数据集,并使用Spark以分布式方式处理加载的数据,然后将处理后的数据馈送到"analytics + AI"管道中。例如,代码1中的第1~6行说明了如何从Hadoop分布式文件系统(HDFS)加载输入数据(文章文本及其相关标签),并将每个文本字符串转换为一个单词列表。
2.2. 数据转换(Data transformation)
Spark通过在RDD上组合多个数据并行运算符来支持通用数据流(DAG),其中每个顶点表示RDD,每个边表示RDD运算符的转换。通过在Spark中构造数据流(DAG),用户可以容易地转换输入数据(例如,图像增强、字向量化等),然后这些数据可以被神经网络模型使用。例如,代码1中的第7~11行说明了如何应用GloVe单词嵌入( word embedding)将每个单词转换为向量。
N维数组:在BigDL中,我们将用于神经网络计算的基本数据元素建模为N维数值(int8、float32等)数组。这些数组分别由numpy.ndarry和Bigdl Teonsor表示(分别与Bigdl Python和Scala/JavaAPI相似)。
Sample:BigDL模型训练和预测中使用的每个记录都被建模为Sample,其中包含输入特性和可选的标签。每个输入特征是一个或多个N维数组,而每个标签要么是标量(float32)值,要么是一个或多个N维数组。例如,代码1中的第12~14行显示了如何将转换后的数据转换为Sample的RDD,稍后将由BigDL模型训练使用。
2.3. 模型构建(Model Construction)
与Torch和Keras类似,BigDL使用神经网络模型的数据流(dataflow)表示,其中数据流图(dataflow graph)中的每个顶点表示神经网络层(如ReLu, Spatial Convolution和LSTM)。BigDL然后使用层的语义进行模型评估(向前)和梯度计算(向后)。例如,代码1中的第15~18行说明了文本分类示例中使用的模型定义。
2.4. 模型训练(Model training)
然后,转换后的输入数据(Sample RDD)和构建的模型(Model)可以传递给BigDL中的Optimizer,后者自动跨集群执行分布式模型训练,如代码1中的第19~25行所示。
Optimizer:在BigDL中,分布式训练过程由Optimizer抽象建模,该抽象运行多个迭代Spark作业,以使得使用特定优化方法(如SGD、AdaGrad、Adam等)的损失最小化(损失可以由用户指定的Criterion所定义)。
Visualization:为了便于用户理解模型训练的行为,BigDL中的优化器可以配置为生成TrainSummary,该TrainSummary包含各种汇总数据(例如,损失、权重等),如代码1中的第24行所示;然后汇总数据可以在例如Tensor或JupytorNotebook中可视化。
2.5. 模型推理(Model Inference)
BigDL还允许用户直接使用Spark中的现有模型(由Caffe、Keras、TensorFlow、Torch或BigDL预先训练),以便以分布式方式(使用RDD转换)直接执行模型预测,如代码1中的第26~28行所示。
ModelBroadcast:BigDL提供ModelBroadcast抽象以管理Spark作业中跨集群的预训练模型的部署;BigDL中的模型预测操作(预测)使用ModelBroadcast在每个机器上缓存模型的单个副本(通过利用Spark中的广播机制),并在同一台机器上管理不同的任务的克隆模型和共享权重。
2.6. Spark DataFrame and ML Pipeline
除了RDD之外,Spark还提供了高级DataFrame抽象,它是具有特定模式(类似于关系数据库中的表)的行的分布式集合,并且实现了数据并行关系运算符,如过滤器和连接,以便进行高效的结构化数据分析。在DataFrame之上,Spark引入了类似于SciKit-Learn的高级ML PipeLine,它允许用户将机器学习工作流构建为数据上的转换图(例如,特征提取、规范化、模型训练等)。BigDL还提供与高级Spark DataFrame和ML PipeLine API(使用其DLModel和DLEstimator抽象)的本地集成。
3. 执行模型(Execution Model)
与其他大数据系统(例如MapReduce[30])类似,Spark集群由单个驱动程序节点和多个工作节点组成,如图1所示。驱动程序节点负责协调Spark作业中的任务(例如,调度和分发),而工作节点负责实际计算和物理数据存储。为了以容错方式自动并行化跨集群的大规模数据处理,Spark提供了函数计算模型,其中通过粗粒度操作符转换不可变的RDD(即,对所有数据项应用相同的操作)。
图1。Spark作业包含许多Spark任务;驱动程序节点负责将任务调度和分派给运行实际Spark任务的工作节点。
另一方面,深层神经网络的有效和分布式训练将需要非常不同的操作(如细粒度数据访问和就地数据转化计算)。在本节中,将详细描述BigDL如何直接在Spark的数据并行和功能计算模型(以及用于模型推断的各种优化)之上支持高效和可伸缩的分布式训练。
3.1. 数据并行训练(Data-parallel training)
为了在整个集群中训练深度神经网络模型,BigDL使用同步小批量SGD( mini-batch SGD)在Spark上提供数据并行训练,这被证明与异步训练相比具有更好的可伸缩性和效率(在时间到质量方面)。BigDL中的分布式训练被实现为迭代过程,如代码2所示;每个迭代运行两个Spark作业,以首先使用当前小批量计算梯度,然后对神经网络模型的参数进行单个更新。
for (i <- 1 to N) {
//"model forward-backward" job
for each task in the Spark job:
read the latest weights
get a random batch of data from local Sample partition
compute errors (forward on local model replica)
compute gradients (backward on local model replica)
//"parameter synchronization" job
aggregate (sum) all the gradients
update the weights per specified optimization method
}
代码2。BigDL提供了高效、数据并行、同步的小批量SGD,其中每个迭代运行两个Spark作业,用于“模型正向-反向”和“参数同步”。
如第2节所述,BigDL将训练数据建模为SampleRDD,这些SampleRDD被自动分区,并可能跨Spark集群缓存在内存中。此外,为了实现数据并行训练,BigDL还构造了模型的RDD,每个RDD都是原始神经网络模型的复制。如图3所示,模型和SampleRDD在整个集群中被共同分区和共同定位;因此,在模型训练的每次迭代中,单个“模型前后向”Spark作业可以将函数zip运算符应用于模型和SampleRDD的分区,并针对每个模型副本并行计算梯度(使用位于同一位置的Sample分区中的一小批数据),如图3所示。
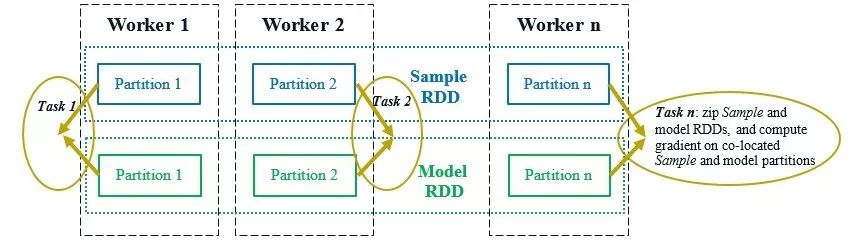
图3.模型的前向后向的spark作业,它并行计算每个模型副本的局部梯度。
3.2. 参数同步(Parameter synchronization)
参数同步是数据并行训练(在速度和可伸缩性方面)的性能关键操作。为了支持有效的参数同步,现有的深度学习框架通常实现参数服务器架构或AllReduce操作,遗憾的是,这些操作不能直接由BigData系统提供的功能计算模型支持。 在BigDL中,已经调整了Spark中可用的原语(例如,shuffle, broadcast, in-memory cache等)以实现高效的AllReduce类操作,以便模拟参数服务器体系结构的功能(如图4所示)。
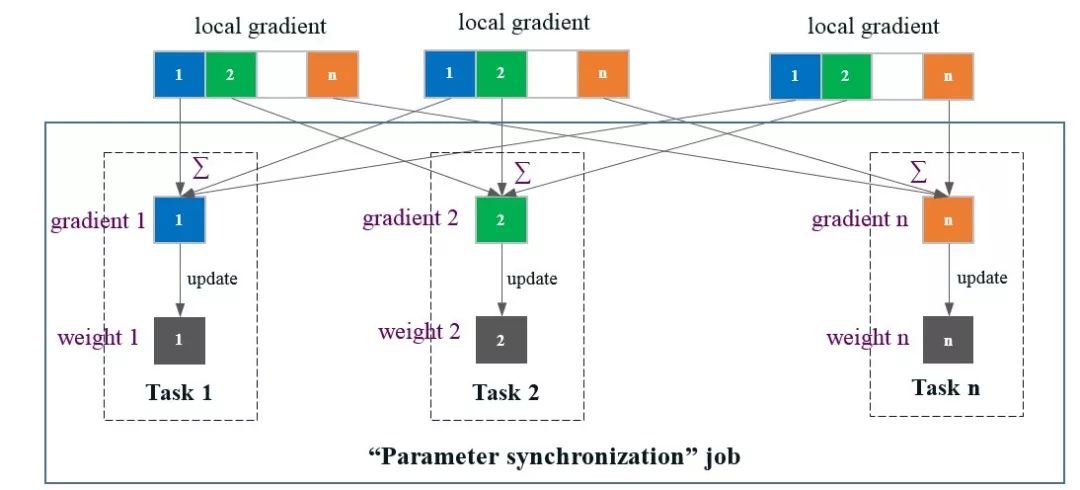
图4。BigDL中的参数同步。每个局部梯度(由“模型前后向”作业中的任务计算)被均匀地分成N个分区;然后,“参数同步”作业中的每个任务n聚集这些局部梯度并更新第n个分区的权重。
Spark作业具有N个任务,每个任务在BigDL中分配从1到N的唯一ID。在“模型向前-向后”作业中的每个任务计算局部梯度之后(如3.1节所述),它均匀地将局部梯度划分为N个分区,如图4所示。
接下来,启动另一个“参数同步”作业;“参数同步”作业中的每个任务n负责管理参数的第n个分区,就像参数服务器(如图5所示)。具体地说,梯度的第n个分区(来自前一个“模型前后向”作业的所有任务)首先被改组为任务n,然后任务n聚集(和)这些梯度,并将更新应用于权重的第n个分区(使用特定的优化方法),如图4所示。
图5。“参数同步”Spark作业管理参数的第n个分区(类似于参数服务器)。
之后,“参数同步”作业中的每个任务n广播更新的权重的第n个分区;因此,在下一次迭代的“模型前后向”作业中的任务可以在下一训练步骤开始之前读取所有权重的最新值。
上面描述的shuffle和任务侧广播操作是在Spark中分布式内存存储之上实现的:shuffle的梯度和广播的权重都在内存中缓存,这可以由Spark任务以极低的延迟远程读取。
3.3. 任务调度(Task scheduling)
尽管BigDL提供了高效的“参数服务器”式体系结构,但它具有与现有深度学习框架根本不同的实现。特别地,现有的深层学习框架通常被部署为多个长期运行的、潜在的有状态任务,它们彼此交互(以阻塞方式支持同步的小批量SGD),用于模型计算和参数同步。
相比之下,BigDL运行一系列短期Spark作业(例如,如前几节所述,每小批处理两个作业),作业中的每个任务都是无状态且无阻塞的。因此,BigDL程序可以及时地自动适应动态资源变化(例如,抢占、故障、增量扩展、资源共享等)。另一方面,Spark中的任务调度可能成为大型集群分布式训练的潜在瓶颈。例如,图6显示,对于ImageNet Inception v1训练,BigDL中启动任务(作为平均计算时间的一部分)的开销(虽然对于100~200个任务来说很低)在接近500个任务时可以增长到10%以上。为了解决这个问题,BigDL将在每个工作者上启动单个多线程任务,以便在大型集群(例如,最多256台服务器,如上面图7所示)上实现高可伸缩性。
为了扩展到更大数量(例如,500)的worker,可以潜在地利用模型训练的迭代性质(其中重复执行相同的操作)。例如,由Drizzle(用于Spark的低延迟执行引擎)引入的组调度能够帮助同时调度多个迭代(或一组)计算,从而即使存在大量任务,也能够大大减少调度开销,如RISELab所标示的,如图6所示。
图6。BigDL中ImageNet Inception v1训练的任务调度和分派(作为平均计算时间的一部分)的开销。
4. 总结
本文描述了BigDL,包括它的编程模型、执行模型。它结合了大型数据和HPC(高性能计算)体系结构的优点,为用户提供表达能力、“数据分析集成”(“data-analytics integrated”)的深度学习编程模型,以建立他们的分析+AI流水线(analytics + AI),以及直接在spark的大型数据平台之上的高效率的“参数服务器”式体系结构。标签数据并行训练。
BigDL正在进行中,但我们的初步经验是令人鼓舞的。自从它最初的开源版本(2016年12月30日)以来,它已经在Github上获得了2400多个明星;并且它使许多用户能够构建新的分析和深度学习应用程序,这些应用程序可以直接运行在现有的Hadoop和/或Spark集群之上。
以上是关于BigDL:用于大数据的分布式深度学习框架的主要内容,如果未能解决你的问题,请参考以下文章