随机森林算法的Python实现
Posted 一加六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了随机森林算法的Python实现相关的知识,希望对你有一定的参考价值。
随机森林主要应用于回归和分类。
它几乎可以将任何数据填进去,下文使用鸢尾花数据进行分类和预测
环境 python3.8
数据集 鸢尾花数据集
def dataset(self):
iris = load_iris()
feature = pd.DataFrame(data=iris.data, columns=iris.feature_names)
target = pd.DataFrame(data=map(lambda item: iris.target_names[item],
iris.target), columns={'target_names'})
feature_train, feature_test, target_train, target_test = \\
train_test_split(feature, target, test_size=0.3)
return feature_train, feature_test, target_train, target_test
实验思路:
首先训练10个基分类器,每个基分类器为一个决策树;在预测时对每个基分类器投票结果进行统计倒排,选取票数最多的结果;其中每棵树的生长情况如下:
如果培训集中的案例数为 N,则随机取样 N 案例 - 但从原始数据中替换。此示例将是种植树的培训集。
如果有 M 输入变量,则指定一个数字 m<<M,以便在每个节点中随机从 M 中选择 m 变量,并且这些 m 上的最佳拆分用于拆分节点。在森林生长过程中,m 值保持不变。
每棵树都尽可能的生长。没有修剪。
查看随机森林官网描述
fit训练
def fit(self, feature=None, label=None):
'''
训练模型,请记得将模型保存至self.models
:param feature: 训练集数据,类型为ndarray
:param label: 训练集标签,类型为ndarray
:return: None
'''
# ************* Begin ************#
n = len(feature)
for i in range(self.n_model):
# 在训练集N随机选取n个样本 #frac=1 样本可重复取 (样本只包含特征数据)
randomSamples = feature.sample(n, replace=True, axis=0)
# 在所有特征M随机选取m个特征 特征无重复 0.75表示选取4*0.75=3个特征
randomFeatures = randomSamples.sample(frac=0.75, replace=False, axis=1)
# 标记该模型选取的特征
tags = self.connect(randomFeatures.columns.tolist())
# 根据样本筛选出索引与之相同的lable即target_name
# 使用loc标签索引获取
randomLable = label.loc[randomSamples.index.tolist(),:]
# for i,j in zip(randomFeatures.index.tolist(),,randomLable.index.tolist()):
# print(i,j)
model = DecisionTreeClassifier()
model = model.fit(randomFeatures, randomLable)
self.models.append({tags: model})
# ************* End **************#
预测
def predict(self, features, target):
'''
:param features: 测试集数据,类型为ndarray
:param target: 测试集实际lable,类型为ndarray
:return: 预测结果,类型为ndarray
'''
# ************* Begin ************#
result = []
vote = []
for model in self.models:
# 获取模型使用的训练特征
modelFeatures = list(model.keys())[0].split('000')[:-1]
# 提取出模型预测需要的标签
test_data = features[modelFeatures]
# 基分类器进行预测
r = list(model.values())[0].predict(test_data)
vote.append(r)
# 将数组转换为矩阵 10行45列
vote = np.array(vote)
# print(vote.shape) # print(vote)
for i in range(len(features)):
# 对每棵树的投票结果进行排序选取最大的
v = sorted(Counter(vote[:, i]).items(),
key=lambda x: x[1], reverse=True)
# 查看投票情况和实际标签对比
print(v, "---",list(target)[i])
result.append(v[0][0])
return result
# ************* End **************#
def connect(self, ls):
s = ''
for i in ls:
s += i + '000'
return s
主函数
if __name__ == '__main__':
Bcf = BaggingClassifier()
featureAndTarget = Bcf.dataset()
Bcf.fit(featureAndTarget[0],featureAndTarget[2])
res = Bcf.predict(features=featureAndTarget[1], target=featureAndTarget[3]['target_names'])
right = 0
for i, j in zip(featureAndTarget[3]['target_names'], res):
if i == j:
right += 1
#print(i + '\\t' + j)
print('准确率为' + str(right / len(res) * 100) + "%")
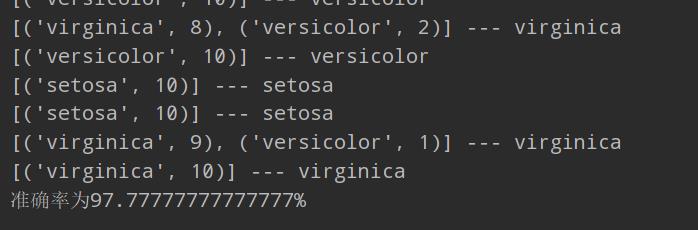
可以看出准确率很高啦,可以调整特征数量m参数,准确率也会不同。
以上是关于随机森林算法的Python实现的主要内容,如果未能解决你的问题,请参考以下文章