论文泛读182一种可区分的语言模型对文本分类器的攻击
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读182一种可区分的语言模型对文本分类器的攻击相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《A Differentiable Language Model Adversarial Attack on Text Classifiers》
一、摘要
用于自然语言处理的大型基于 Transformer 的模型的稳健性是一个重要问题,因为它们的功能和广泛采用。理解和提高这些模型鲁棒性的一种方法是探索对抗性攻击场景:检查输入的小扰动是否可以欺骗模型。
由于文本数据的离散性,广泛用于计算机视觉的基于梯度的对抗方法本身并不适用。克服这个问题的标准策略是开发令牌级别的转换,它不考虑整个句子。
在本文中,我们提出了一种新的黑盒句子级攻击。我们的方法对预训练的语言模型进行微调以生成对抗性示例。建议的可微损失函数取决于替代分类器分数和通过深度学习模型计算的近似编辑距离。
我们表明,在计算指标和人工评估方面,所提出的攻击在各种 NLP 问题上都优于竞争对手。此外,由于使用了微调的语言模型,生成的对抗样本很难被检测到,因此当前的模型并不健壮。因此,很难防御提议的攻击,而其他攻击则不然。
二、结论
由于输入数据的离散性和损失函数的不可微性,为自然语言处理构建对抗性攻击是一个具有挑战性的问题。我们的想法是将从一个掩蔽语言模型(MLM)中取样与调整其参数相结合,以产生真正的对抗性例子。为了调整MLM的参数,我们使用了基于两个可微替代的损失函数——序列之间的距离和被攻击的分类器。这导致了建议的DILMA方法。如果我们只从MLM取样,我们会得到一个简单的基线取样傻瓜。
为了评估分类序列上对抗攻击的效率,我们提出了一种结合WER和目标分类器精度的度量。对于不同的自然语言处理数据集,我们的方法表现出良好的性能。此外,与竞争方法相反,我们的方法战胜了用于防御敌对攻击的常用策略。人类和语言评估也显示了提议的攻击的充分性。
三、model
DILMA架构的培训包括以下步骤。步骤1:从输入x的预训练语言模型(LM)生成器中获取逻辑P。步骤2:使用Gumbel-Softmax估计器从多项式分布P中采样x0。为了提高发电质量,我们可以多次采样。第三步:得到替代概率C(x0)和近似编辑距离DL(x0,x)。第四步:计算损失,做一个倒传。步骤5:使用计算的梯度更新LM的参数。
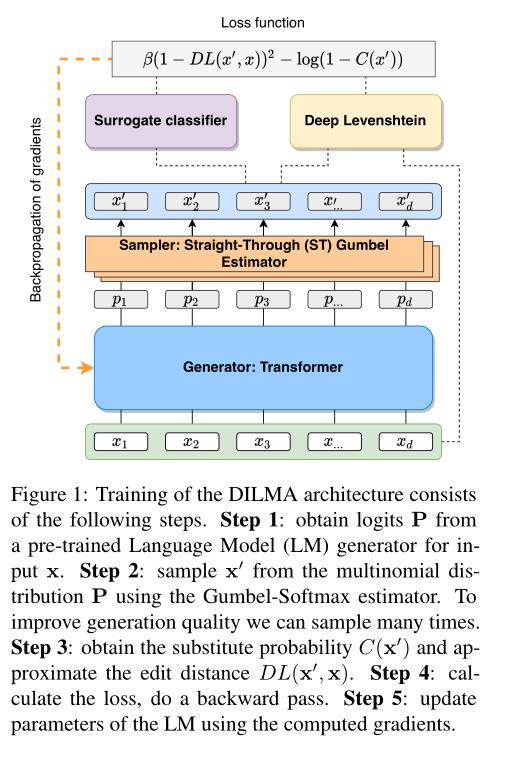
损失函数(loss function):
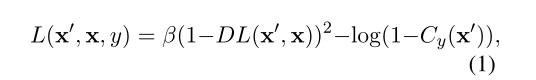
DILMA算法:

以上是关于论文泛读182一种可区分的语言模型对文本分类器的攻击的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读167使用 BERT 语言模型的大规模新闻分类:Spark NLP 方法