论文泛读167使用 BERT 语言模型的大规模新闻分类:Spark NLP 方法
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读167使用 BERT 语言模型的大规模新闻分类:Spark NLP 方法相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Large-Scale News Classification using BERT Language Model: Spark NLP Approach》
一、摘要
基于 NLP 的大数据分析的兴起增加了大规模文本处理的计算负担。NLP 面临的问题是非常高维的文本,因此需要很高的计算资源。MapReduce 允许大型计算的并行化,并可以提高文本处理的效率。本研究旨在基于深度学习方法研究大数据处理对 NLP 任务的影响。我们通过微调 BERT 使用的预训练模型对大量新闻主题文本进行分类。本研究使用了五个具有不同数量参数的预训练模型。为了衡量这种方法的效率,我们将 BERT 的性能与 Spark NLP 的管道进行了比较。结果表明,与使用 Spark NLP 的 BERT 相比,不使用 Spark NLP 的 BERT 具有更高的准确率。使用 BERT 的所有模型的准确率平均值和训练时间为 0.9187 和 35 分钟,而使用 Spark NLP 管道的 BERT 为 0.8444 和 9 分钟。更大的模型会占用更多的计算资源,并且需要更长的时间来完成任务。然而,与没有 Spark NLP 的 BERT 相比,使用 Spark NLP 的 BERT 的准确率仅平均下降了 5.7%,而训练时间则显着减少了 62.9%。
二、结论
BERT模型是完成新闻分类等大规模自然语言处理任务的好模型。模型越大,精度越高,但完成任务需要更多时间。我们用来训练和测试模型的数据集越大,它将影响完成任务所需的时间。当我们想要使用BERT-Large模型并处理大量数据时,使用Spark NLP会给我们带来优势。在本研究中,我们发现使用具有Spark自然语言处理的BERT比使用不具有Spark自然语言处理的BERT更有效。使用带有Spark NLP的BERT,与不带Spark NLP的BERT相比,下降精度平均值为5.7%,训练时间下降平均值为62.9%。在不久的将来,我们计划通过探索更多的架构和预训练模型来扩展和改进我们的框架,以提高分类性能和计算资源。此外,我们想探索训练前文本预处理的效果。
三、model-Spark NLP
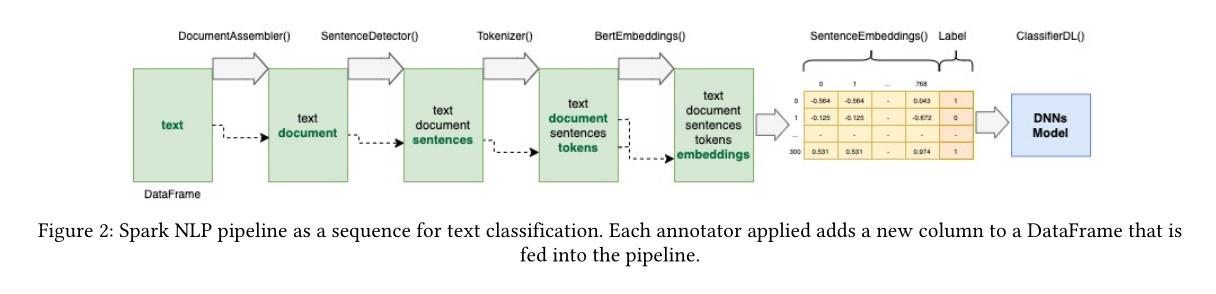
Spark NLP是建立在Apache Spark和Spark ML之上的开源库。Apache Spark是Hadoop生态系统的一个组成部分,Hadoop生态系统是一个受欢迎的大数据平台,因为它能够处理流式数据。
使用文本处理和来自BERT预训练模型的单词嵌入在Spark NLP中建立了一个文本分类模型,Spark NLP中的每个阶段都是以序列的形式在管道中实现的。
以上是关于论文泛读167使用 BERT 语言模型的大规模新闻分类:Spark NLP 方法的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读95一石二鸟:窃取模型并从基于BERT的API推断属性
论文泛读200通过适配器使用预训练语言模型进行稳健的迁移学习
论文泛读200通过适配器使用预训练语言模型进行稳健的迁移学习