论文泛读84使用BERT适配器的Lexicon增强中文序列标记
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读84使用BERT适配器的Lexicon增强中文序列标记相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter》
一、摘要
词典信息和经过训练的模型(例如BERT)由于其各自的优势而被组合用于探索中文序列标记任务。但是,现有方法仅通过浅层和随机初始化的序列层融合词汇特征,而没有将其集成到BERT的底层。在本文中,我们提出了用于中文序列标签的Lexicon增强BERT(LEBERT),它通过Lexicon适配器层将外部词典知识直接集成到BERT层中。与现有方法相比,我们的模型有助于在BERT的较低层进行深度词典知识融合。在十个中文数据集上的三个任务的实验,包括命名实体识别,分词和词性标注,表明LEBERT获得了最新的结果。
二、结论
在本文中,我们提出了一种新的方法来集成词典特征和汉语序列标注的关联规则,该方法使用词典适配器直接在关联规则的变换层之间注入词典信息。与模型级融合方法相比,LEBERT允许在BERT级深入融合词汇特征和BERT表示。大量实验表明,该算法在三个中文序列标注任务的十个数据集上取得了良好的性能。
三、模型
现有的汉语序列标注模型
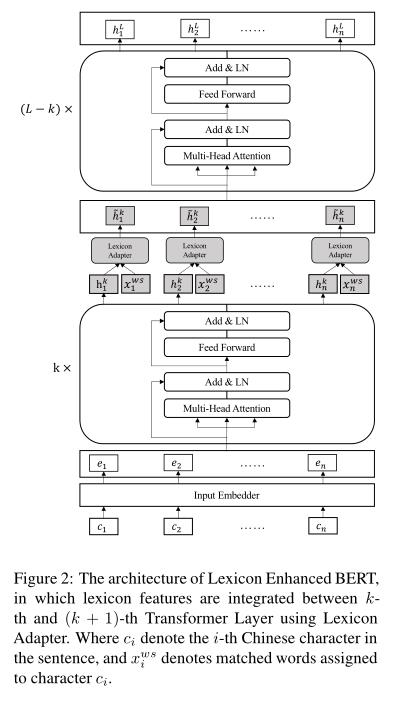
研究了LEBERT在三个中文序列标签任务上的有效性,包括中文NER、中文分词和中文词性标注。在10个基准数据集上的实验结果说明了我们模型的有效性,其中在所有数据集上的每个任务都实现了最先进的性能。
本文的模型:与BERT相比,LEBERT有两个主要区别。首先,假设中文句子被转换成一个字符-单词对序列,LEBERT将字符和词典特征都作为输入。第二,一个词典适配器连接在转换器层之间,允许词典知识有效地集成到BERT中。
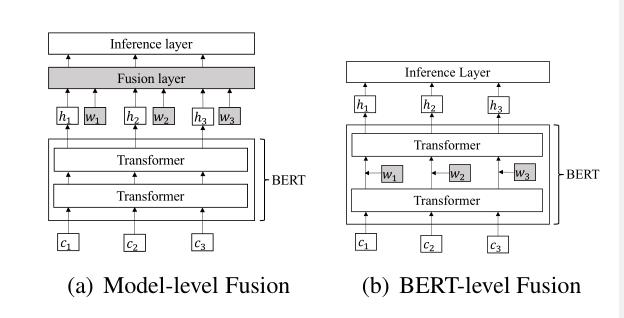
对比模型:使用了四个对比模型

在三类十个数据集中,效果取得了明显的提高。
以上是关于论文泛读84使用BERT适配器的Lexicon增强中文序列标记的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读200通过适配器使用预训练语言模型进行稳健的迁移学习