[人工智能-深度学习-25]:卷积神经网络CNN - CS231n解读 - 卷积层详解
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-25]:卷积神经网络CNN - CS231n解读 - 卷积层详解相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:[人工智能-深度学习-25]:卷积神经网络CNN - CS231n解读 - 卷积层详解_文火冰糖(王文兵)的博客-CSDN博客
目录
第2章 卷积核的局部连接性:卷积核与输入数据体之间的连接方式
第1章 卷积神经网络概述
卷积层是构建卷积神经网络的核心层,它产生了网络中大部分的计算量。
首先讨论的是,在没有大脑和生物意义上的神经元之类的比喻下,卷积层到底在计算什么呢?
卷积层的参数是有一些可学习(不是固定值,而是W,B参数,是通过反向求导来修正的)的滤波器集合构成的。
每个滤波器在空间上(宽度和高度)都比较小,但是深度和输入数据一致。

举例来说,卷积神经网络第一层的一个典型的滤波器的尺寸可以是5x5x3(宽高都是5像素,深度是3是因为图像应为颜色通道,所以有3的深度)。在前向传播的时候,让每个滤波器都在输入数据的宽度和高度上滑动(更精确地说是卷积),然后计算整个滤波器和输入数据任一处的内积。当滤波器沿着输入数据的宽度和高度滑过后,会生成一个2维的激活图(activation map),激活图给出了在每个空间位置处滤波器的反应。
直观地来说,网络会让滤波器(卷积核)学习到当它看到某些类型的视觉特征时就激活,具体的视觉特征可能是某些方位上的边界,或者在第一层上某些颜色的斑点,甚至可以是网络更高层上的蜂巢状或者车轮状图案。
在每个卷积层上,我们会有一整个集合的滤波器(比如12个),每个都会生成一个不同的二维激活图。将这些激活映射在深度方向上层叠起来就生成了输出数据。
以大脑做比喻:如果你喜欢用大脑和生物神经元来做比喻,那么输出的3D数据中的每个数据项可以被看做是神经元的一个输出,而该神经元只观察输入数据中的一小部分,并且和空间上左右两边的所有神经元共享参数(因为这些数字都是使用同一个滤波器得到的结果)。
现在开始讨论神经元的连接,它们在空间中的排列,以及它们参数共享的模式。
第2章 卷积核的局部连接性:卷积核与输入数据体之间的连接方式
局部连接:在处理图这样的高维度(三个维度,每个维度的size很大)输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的(导致过多可调参数,每个连接就是一个参数)。

相反,我们让每个神经元只与输入数据的一个局部区域连接,而不是与所有的输入相连。
该局部连接的空间大小叫做神经元的感受野(receptive field),它的尺寸是一个超参数(其实就是滤波器的空间尺寸)。
在深度(通道)方向上,这个连接的大小总是和输入量的深度相等。
需要再次强调的是,我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。
备注:这里的深度,不是输出深度,即卷积核神经元的个数;而是指输入深度,神经元W矩阵的深度。
例1:假设输入数据体尺寸为[32x32x3](比如CIFAR-10的RGB图像),如果感受野(或滤波器尺寸)是5x5,那么卷积层中的每个神经元会有输入数据体中[5x5x3]区域的权重,共5x5x3=75个权重(还要加一个偏差参数)。注意这个连接在深度维度上的大小必须为3,和输入数据体的深度一致。
例2:假设输入数据体的尺寸是[16x16x20],感受野尺寸是3x3,那么卷积层中每个神经元和输入数据体就有3x3x20=180个连接。再次提示:在空间上连接是局部的(3x3),但是在深度上是和输入数据体一致的(20)。
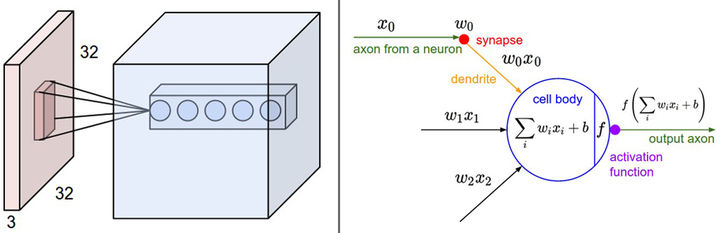
左边:
红色的是输入数据体(比如CIFAR-10中的图像),蓝色的部分是第一个卷积层中的神经元。
卷积层中的每个神经元都只是与输入数据体的一个局部在空间上相连,但是与输入数据体的所有深度维度全部相连(所有颜色通道)。在深度方向上有多个神经元(本例中5个),它们都接受输入数据的同一块区域(感受野相同)。至于深度列的讨论在下文中有。
右边:
神经网络章节中介绍的神经元保持不变,它们还是计算权重和输入的内积,然后进行激活函数运算,只是它们的连接被限制在一个局部空间。
第3章 卷积层的输出方式
3.1 概述参数概述
上章讲解了卷积层中每个神经元与输入数据体之间的连接方式,但是尚未讨论输出数据体中神经元的数量,以及它们的排列方式。
有3个超参数控制着输出数据体的尺寸:
深度(depth),步长(stride)和零填充(zero-padding)。
下面是对它们的讨论:

- 首先是输出数据体的深度,它是一个超参数:它和使用的滤波器的数量一致,而每个滤波器在输入数据中寻找一些不同的东西(不一样的特征)。举例来说,如果第一个卷积层的输入是原始图像,那么在深度维度上的不同神经元将可能被不同方向的边界,或者是颜色斑点激活。我们将这些沿着深度方向排列、感受野相同的神经元集合称为深度列(depth column),也有人使用纤维(fibre)来称呼它们。
- 其次是步长:在滑动滤波器的时候,必须指定步长。当步长为1,滤波器每次移动1个像素。当步长为2(或者不常用的3,或者更多,这些在实际中很少使用),滤波器滑动时每次移动2个像素。这个操作会让输出数据体在空间上变小。
- 在下文可以看到,有时候将输入数据体用0在边缘处进行填充是很方便的。这个零填充(zero-padding)的尺寸是一个超参数。零填充有一个良好性质,即可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高都相等)。
3.2 卷积层输出尺寸计算
卷积层输出尺寸是有多种因素决定的:输入图片的大小、卷积核的大小、卷积核的深度(个数)、卷积移动的步长。
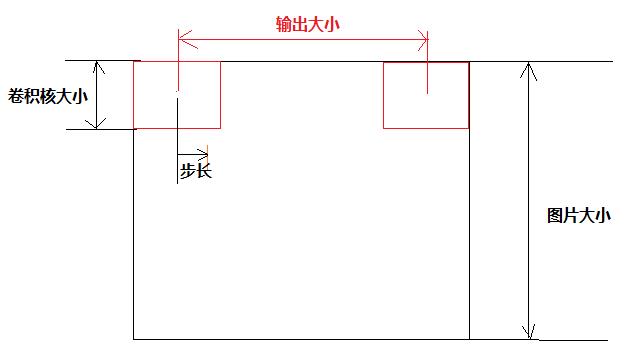
假设输出数据体在空间上的尺寸可以通过输入数据体尺寸(W),卷积层中神经元的感受野尺寸(F),步长(S)和零填充的数量(P)的函数来计算。(译者注:这里假设输入数组的空间形状是正方形,即高度和宽度相等)输出数据体的空间尺寸为:(W-F +2P)/S+1。
比如输入是7x7,滤波器是3x3,步长为1,填充为0,那么就能得到一个5x5的输出。如果步长为2,输出就是3x3。下面是例子:

空间排列的图示。
在本例中只有一个空间维度(x轴),神经元的感受野尺寸F=3,输入尺寸W=5,零填充P=1。
左边:神经元使用的步长S=1,所以输出尺寸是(5-3+2)/1+1=5。
右边:神经元使用的步长S=2,则输出尺寸是(5-3+2)/2+1=3。
注意当步长S=3时是无法使用的,因为它无法整齐地穿过数据体。从等式上来说,因为(5-3+2)=4是不能被3整除的。
本例中,神经元的权重是[1,0,-1],显示在图的右上角,偏差值为0。这些权重是被所有黄色的神经元共享的(参数共享的内容看下文相关内容)。
(1)使用零填充:
在上面左边例子中,注意输入维度是5,输出维度也是5。之所以如此,是因为感受野是3并且使用了1的零填充。如果不使用零填充,则输出数据体的空间维度就只有3,因为这就是滤波器整齐滑过并覆盖原始数据需要的数目。一般说来,当步长时,零填充的值是,这样就能保证输入和输出数据体有相同的空间尺寸。这样做非常常见,在介绍卷积神经网络的结构的时候我们会详细讨论其原因。
(2)步长的限制:
注意这些空间排列的超参数之间是相互限制的。举例说来,当输入尺寸,不使用零填充则,滤波器尺寸,这样步长就行不通,因为
,结果不是整数,这就是说神经元不能整齐对称地滑过输入数据体。因此,这些超参数的设定就被认为是无效的,一个卷积神经网络库可能会报出一个错误,或者修改零填充值来让设置合理,或者修改输入数据体尺寸来让设置合理,或者其他什么措施。在后面的卷积神经网络结构小节中,读者可以看到合理地设置网络的尺寸让所有的维度都能正常工作,这件事可是相当让人头痛的。而使用零填充和遵守其他一些设计策略将会有效解决这个问题。
真实案例:Krizhevsky构架赢得了2012年的ImageNet挑战,其输入图像的尺寸是[227x227x3]。在第一个卷积层,神经元使用的感受野尺寸,步长,不使用零填充。因为(227-11)/4+1=55,卷积层的深度,则卷积层的输出数据体尺寸为[55x55x96]。55x55x96个神经元中,每个都和输入数据体中一个尺寸为[11x11x3]的区域全连接。在深度列上的96个神经元都是与输入数据体中同一个[11x11x3]区域连接,但是权重不同。有一个有趣的细节,在原论文中,说的输入图像尺寸是224x224,这是肯定错误的,因为(224-11)/4+1的结果不是整数。这件事在卷积神经网络的历史上让很多人迷惑,而这个错误到底是怎么发生的没人知道。我的猜测是Alex忘记在论文中指出自己使用了尺寸为3的额外的零填充。
第4章 参数共享
在卷积层中使用参数共享是用来控制参数的数量。
就用上面的例子,在第一个卷积层就有55x55x96= 290,400个神经元,每个有11x11x3=364个参数和1个偏差。将这些合起来就是290400x364=105,705,600个参数。单单第一层就有这么多参数,显然这个数目是非常大的。
作一个合理的假设:如果一个特征在计算某个空间位置(x,y)的时候有用,那么它在计算另一个不同位置(x2,y2)的时候也有用。基于这个假设,可以显著地减少参数数量。换言之,就是将深度维度上一个单独的2维切片看做深度切片(depth slice),比如一个数据体尺寸为[55x55x96]的就有96个深度切片,每个尺寸为[55x55]。在每个深度切片上的神经元都使用同样的权重和偏差。在这样的参数共享下,例子中的第一个卷积层就只有96个不同的权重集了,一个权重集对应一个深度切片,共有96x11x11x3=34,848个不同的权重,或34,944个参数(+96个偏差)。在每个深度切片中的55x55个权重使用的都是同样的参数。在反向传播的时候,都要计算每个神经元对它的权重的梯度,但是需要把同一个深度切片上的所有神经元对权重的梯度累加,这样就得到了对共享权重的梯度。这样,每个切片只更新一个权重集。
注意,如果在一个深度切片中的所有权重都使用同一个权重向量,那么卷积层的前向传播在每个深度切片中可以看做是在计算神经元权重和输入数据体的卷积(这就是“卷积层”名字由来)。这也是为什么总是将这些权重集合称为滤波器(filter)(或卷积核(kernel)),因为它们和输入进行了卷积。

Krizhevsky等学习到的滤波器例子。这96个滤波器的尺寸都是[11x11x3],在一个深度切片中,每个滤波器都被55x55个神经元共享。
注意参数共享的假设是有道理的:如果在图像某些地方探测到一个水平的边界是很重要的,那么在其他一些地方也会同样是有用的,这是因为图像结构具有平移不变性。所以在卷积层的输出数据体的55x55个不同位置中,就没有必要重新学习去探测一个水平边界了。
注意有时候参数共享假设可能没有意义,特别是当卷积神经网络的输入图像是一些明确的中心结构时候。这时候我们就应该期望在图片的不同位置学习到完全不同的特征。一个具体的例子就是输入图像是人脸,人脸一般都处于图片中心。你可能期望不同的特征,比如眼睛特征或者头发特征可能(也应该)会在图片的不同位置被学习。在这个例子中,通常就放松参数共享的限制,将层称为局部连接层(Locally-Connected Layer)。
Numpy例子:为了让讨论更加的具体,我们用代码来展示上述思路。假设输入数据体是numpy数组X。那么:
- 一个位于(x,y)的深度列(或纤维)将会是X[x,y,:]。
- 在深度为d处的深度切片,或激活图应该是X[:,:,d]。
卷积层例子:假设输入数据体X的尺寸X.shape:(11,11,4),不使用零填充(),滤波器的尺寸是,步长。那么输出数据体的空间尺寸就是(11-5)/2+1=4,即输出数据体的宽度和高度都是4。那么在输出数据体中的激活映射(称其为V)看起来就是下面这样(在这个例子中,只有部分元素被计算):
- V[0,0,0] = np.sum(X[:5,:5,:] * W0) + b0
- V[1,0,0] = np.sum(X[2:7,:5,:] * W0) + b0
- V[2,0,0] = np.sum(X[4:9,:5,:] * W0) + b0
- V[3,0,0] = np.sum(X[6:11,:5,:] * W0) + b0
在numpy中,*操作是进行数组间的逐元素相乘。权重向量W0是该神经元的权重,b0是其偏差。在这里,W0被假设尺寸是W0.shape: (5,5,4),因为滤波器的宽高是5,输入数据量的深度是4。注意在每一个点,计算点积的方式和之前的常规神经网络是一样的。同时,计算内积的时候使用的是同一个权重和偏差(因为参数共享),在宽度方向的数字每次上升2(因为步长为2)。要构建输出数据体中的第二张激活图,代码应该是:
- V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1
- V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1
- V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1
- V[3,0,1] = np.sum(X[6:11,:5,:] * W1) + b1
- V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1 (在y方向上)
- V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1 (或两个方向上同时)
我们访问的是V的深度维度上的第二层(即index1),因为是在计算第二个激活图,所以这次试用的参数集就是W1了。在上面的例子中,为了简洁略去了卷积层对于输出数组V中其他部分的操作。还有,要记得这些卷积操作通常后面接的是ReLU层,对激活图中的每个元素做激活函数运算,这里没有显示。
小结: 我们总结一下卷积层的性质:
- 输入数据体的尺寸为
- 4个超参数:
- 滤波器的数量
- 滤波器的空间尺寸
- 步长
- 零填充数量
- 输出数据体的尺寸为 ,其中:
-
- (宽度和高度的计算方法相同)
- 由于参数共享,每个滤波器包含个权重,卷积层一共有个权重和个偏置。
- 在输出数据体中,第个深度切片(空间尺寸是),用第个滤波器和输入数据进行有效卷积运算的结果(使用步长
),最后在加上第
个偏差。
对这些超参数,常见的设置是,,。同时设置这些超参数也有一些约定俗成的惯例和经验,可以在下面的卷积神经网络结构章节中查看。
卷积层演示:下面是一个卷积层的运行演示。因为3D数据难以可视化,所以所有的数据(输入数据体是蓝色,权重数据体是红色,输出数据体是绿色)都采取将深度切片按照列的方式排列展现。输入数据体的尺寸是,卷积层参数。就是说,有2个滤波器,滤波器的尺寸是,它们的步长是2.因此,输出数据体的空间尺寸是(5-3+2)/2+1=3。注意输入数据体使用了零填充,所以输入数据体外边缘一圈都是0。下面的例子在绿色的输出激活数据上循环演示,展示了其中每个元素都是先通过蓝色的输入数据和红色的滤波器逐元素相乘,然后求其总和,最后加上偏差得来。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120804058
以上是关于[人工智能-深度学习-25]:卷积神经网络CNN - CS231n解读 - 卷积层详解的主要内容,如果未能解决你的问题,请参考以下文章
[人工智能-深度学习-37]:卷积神经网络CNN - 重构神经网络的疑惑与思考?
[人工智能-深度学习-26]:卷积神经网络CNN - 为啥要卷积神经网络以及卷积神经网络的应用
[人工智能-深度学习-28]:卷积神经网络CNN - 网络架构与描述方法
25- 卷积神经网络(CNN)原理 (TensorFlow系列) (深度学习)