25- 卷积神经网络(CNN)原理 (TensorFlow系列) (深度学习)
Posted 处女座_三月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了25- 卷积神经网络(CNN)原理 (TensorFlow系列) (深度学习)相关的知识,希望对你有一定的参考价值。
知识要点
-
卷积神经网络的几个主要结构:
-
卷积层(Convolutions):
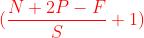
-
Valid :不填充,也就是最终大小为卷积后的大小.
-
Same:输出大小与原图大小一致,那么N 变成了N+2P. padding-零填充.
-
-
池化层(Subsampling), 主要对卷积层学习到的特征图进行亚采样处理:
-
最大池化:Max Pooling, 取窗口内的最大值作为输出
-
平均池化:Avg Pooling, 取窗口内的所有值的均值作为输出
-
-
全连接层(Full connection)
-
卷积层+激活层+池化层可以看成是CNN的特征学习/特征提取层,而学习到的特征(Feature Map)最终应用于模型任务,需要先对所有 Feature Map 进行扁平化.
-
-
激活函数
-
softmax, relu, selu, sigmoid
-
-
- filters , 卷积核, 必须是4维的tensor(卷积核的高度和宽度, 输入图片的通道数, 卷积核的个数)
- strides, 步长, 卷积核在图片的各个维度的移动步长, (1, 1, 1)
- padding, 0填充, 'valid'和'same', valid 表示不填充, same表示输入图片和输出图片的大小保持一致, (会自动计算)
- 显示卷积过程中的图像:
# 边缘检测
input_img = tf.constant(cat_gray.reshape(1, 456, 730, 1), dtype = tf.float32)
filters = tf.constant(np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]]
).reshape(3, 3, 1, 1), dtype = tf.float32)
strides = [1, 1, 1, 1]
conv2d = tf.nn.conv2d(input = input_img, filters= filters, strides= strides, padding= 'SAME')
plt.figure(figsize= (10, 8))
plt.imshow(conv2d.numpy().reshape(456, 730), cmap = 'gray')一 卷积神经网络(CNN)原理
1.1 卷积神经网络的组成
1.1.1 简介
-
卷积神经网络由一个或多个卷积层、池化层以及全连接层等组成。与其他深度学习结构相比,卷积神经网络在图像等方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他浅层或深度神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
我们来看一下卷积网络的整体结构什么样子。
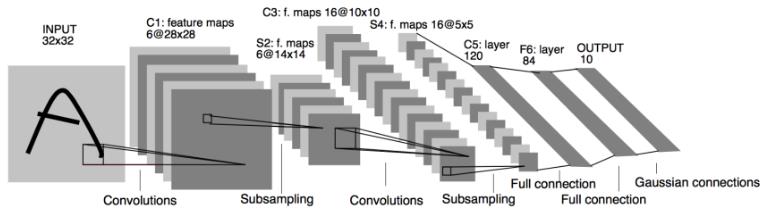
其中包含了几个主要结构
-
卷积层(Convolutions)
-
池化层(Subsampling)
-
全连接层(Full connection)
-
激活函数
1.1.2 卷积层
-
目的: 卷积运算的目的是提取输入的不同特征,某些卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
-
参数:
-
size: 卷积核/过滤器大小,选择有1 *1, 3* 3, 5 * 5
-
padding:零填充,Valid 与Same
-
stride: 步长,通常默认为1
-
-
计算公式

1.1.3 卷积运算过程
对于之前介绍的卷积运算过程,我们用一张动图来表示更好理解些。一下计算中,假设图片长宽相等,设为N, 一个步长, 3 X 3 卷积核运算。
假设是一张5 X 5 的单通道图片,通过使用3 X 3 大小的卷积核运算得到一个 3 X 3大小的运算结果(图片像素数值仅供参考)
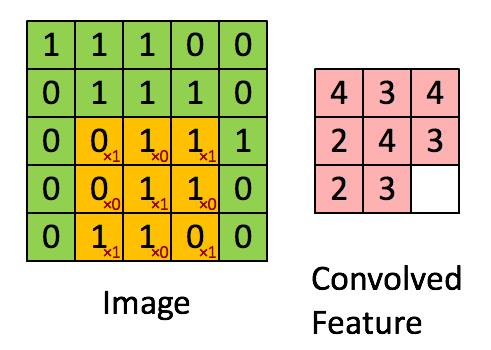
我们会发现进行卷积之后的图片变小了,假设N为图片大小,F为卷积核大小
相当于: 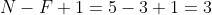
如果我们换一个卷积核大小或者加入很多层卷积之后,图像可能最后就变成了1 X 1 大小,这不是我们希望看到的结果。并且对于原始图片当中的边缘像素来说,只计算了一遍,二对于中间的像素会有很多次过滤器与之计算,这样导致对边缘信息的丢失。
缺点:
-
图像变小
-
边缘信息丢失
1.1.4 padding-零填充
零填充:在图片像素的最外层加上若干层0值,若一层,记做p =1。
-
为什么增加的是0?
因为0在权重乘积和运算中对最终结果不造成影响,也就避免了图片增加了额外的干扰信息。
这张图中,还是移动一个像素,并且外面增加了一层0。那么最终计算结果我们可以这样用公式来计算: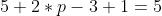 , P为1,那么最终特征结果为5。实际上我们可以填充更多的像素,假设为2层,则
, P为1,那么最终特征结果为5。实际上我们可以填充更多的像素,假设为2层,则 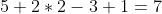 ,这样得到的观察特征大小比之前图片大小还大。所以我们对于零填充会有一些选择,该填充多少?
,这样得到的观察特征大小比之前图片大小还大。所以我们对于零填充会有一些选择,该填充多少?
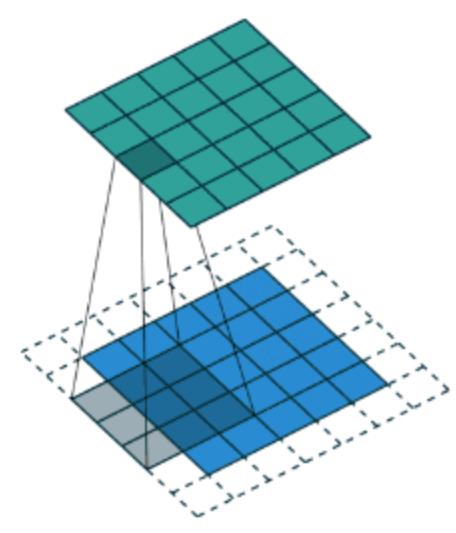
1.1.5 Valid and Same卷积
有两种形式,所以为了避免上述情况,大家选择都是Same这种填充卷积计算方式
-
Valid :不填充,也就是最终大小为:

-
Same:输出大小与原图大小一致,那么N 变成了N+2P:

那也就意味着,之前大小与之后的大小一样,得出下面的等式
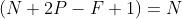
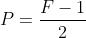
所以当知道了卷积核的大小之后,就可以得出要填充多少层像素。
1.1.6 奇数维度的过滤器 (卷积核)
通过上面的式子,如果F不是奇数而是偶数个,那么最终计算结果不是一个整数,造成0.5,1.5.....这种情况,这样填充不均匀,所以也就是为什么卷积核默认都去使用奇数维度大小
-
1 *1,3* 3, 5 *5,7* 7
-
另一个解释角度
-
奇数维度的过滤器有中心,便于指出过滤器的位置
-
当然这个都是一些假设的原因,最终原因还是在F对于计算结果的影响。所以通常选择奇数维度的过滤器,是大家约定成俗的结果,可能也是基于大量实验奇数能得出更好的结果。
1.1.7 stride-步长
以上例子中我们看到的都是每次移动一个像素步长的结果,如果将这个步长修改为2,3,那结果如何?
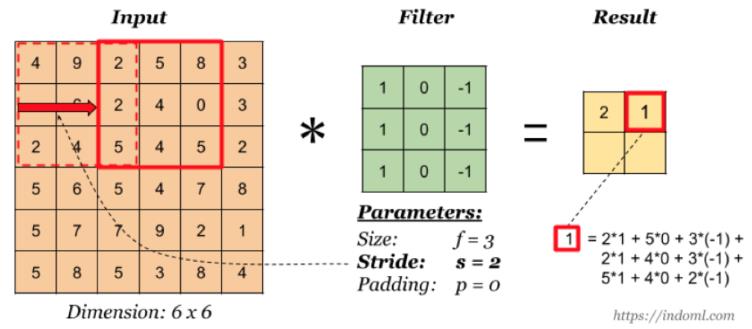
这样如果以原来的计算公式,那么结果: 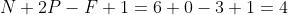
但是移动2个像素才得出一个结果,所以公式变为: 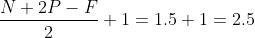 ,如果相除不是整数的时候,向下取整,为2。这里并没有加上零填充。
,如果相除不是整数的时候,向下取整,为2。这里并没有加上零填充。
所以最终的公式就为:
- 对于输入图片大小为N,过滤器大小为F,步长为S,零填充为P:
1.2 多通道卷积
当输入有多个通道(channel)时(例如图片可以有 RGB 三个通道),卷积核需要拥有相同的channel 数, 每个卷积核 channel 与输入层的对应 channel 进行卷积,将每个 channel 的卷积结果按位相加得到最终的 Feature Map。
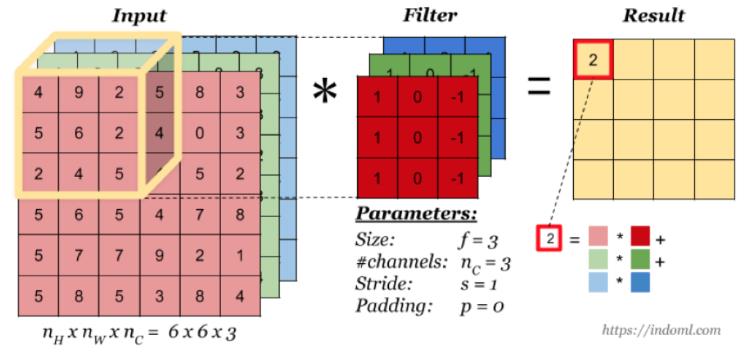
1.2.1 多卷积核
当有多个卷积核时,可以学习到多种不同的特征,对应产生包含多个 channel 的 Feature Map, 例如上图有两个 filter,所以 output 有两个 channel。这里的多少个卷积核也可理解为多少个神经元。相当于我们把多个功能的卷积核的计算结果放在一起,比如水平边缘检测和垂直边缘检测器。
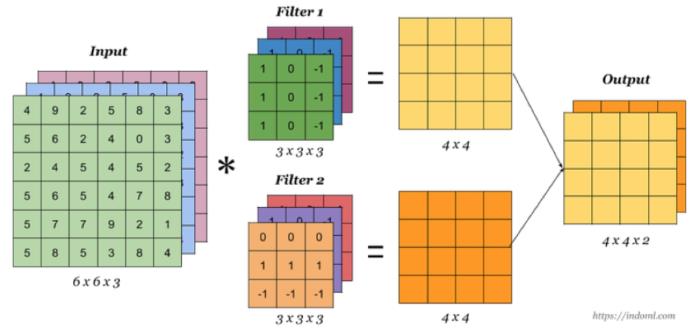
1.2.2 卷积总结
我们来通过一个例子看一下结算结果,以及参数的计算
-
假设我们有10 个Filter,每个Filter3 X 3 X 3(计算RGB图片),并且只有一层卷积,那么参数有多少?
计算:每个Filter参数个数为: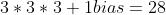 个权重参数,总共28 * 10 = 280个参数,即使图片任意大小,我们这层的参数也就这么多。
个权重参数,总共28 * 10 = 280个参数,即使图片任意大小,我们这层的参数也就这么多。
-
假设一张200 *200* 3的图片,进行刚才的Filter,步长为1,最终为了保证最后输出的大小为200 * 200,需要设置多大的零填充
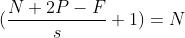
1.2.3 设计单个卷积Filter的计算公式
假设神经网络某层l的输入:
-
inputs:
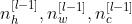
-
卷积层参数设置:
-
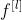 :filter的大小
:filter的大小 -
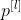 :padding的大小
:padding的大小 -
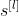 :stride大小
:stride大小 -
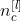 :filter的总数量
:filter的总数量
-
-
outputs:
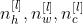
所以通用的表示每一层:
-
每个Filter:

-
权重Weights:
-
应用激活函数Activations:
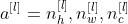
-
偏差bias:
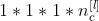 ,通常会用4维度来表示
,通常会用4维度来表示
之前的式子我们就可以简化成,假设多个样本编程向量的形式:
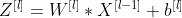
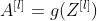
1.3 池化层(Pooling)
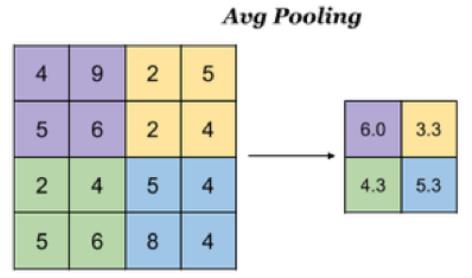
池化层主要对卷积层学习到的特征图进行亚采样(subsampling)处理,主要由两种:
-
最大池化:Max Pooling, 取窗口内的最大值作为输出
-
平均池化:Avg Pooling, 取窗口内的所有值的均值作为输出
意义在于:
-
降低了后续网络层的输入维度,缩减模型大小,提高计算速度
-
提高了Feature Map 的鲁棒性,防止过拟合
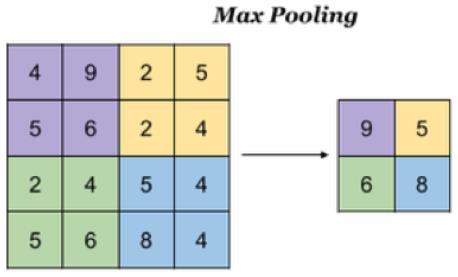
对于一个输入的图片,我们使用一个区域大小为2 *2,步长为2的参数进行求最大值操作。同样池化也有一组参数,f, s,得到2* 2的大小。当然如果我们调整这个超参数,比如说3 * 3,那么结果就不一样了,通常选择默认都是f = 2 * 2, s = 2
池化超参数特点:不需要进行学习,不像卷积通过梯度下降进行更新。
如果是平均池化则:
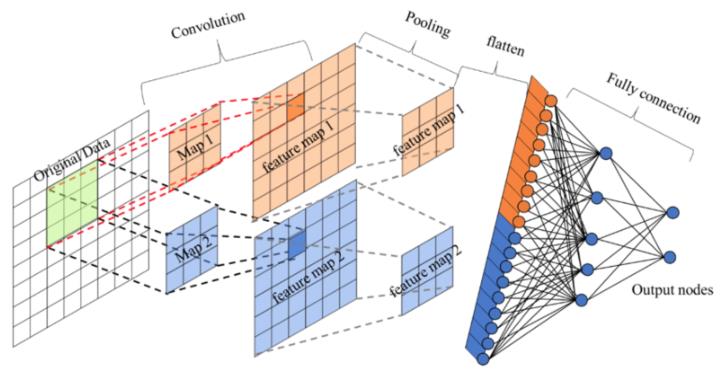
1.4 全连接层
卷积层+激活层+池化层可以看成是CNN的特征学习/特征提取层,而学习到的特征(Feature Map)最终应用于模型任务(分类、回归):
-
先对所有 Feature Map 进行扁平化(flatten, 即 reshape 成 1 x N 向量)
-
再接一个或多个全连接层,进行模型学习
二 图像数据与边缘检测
2.1 为什么需要卷积神经网络
在计算机视觉领域,通常要做的就是指用机器程序替代人眼对目标图像进行识别等。那么神经网络也好还是卷积神经网络其实都是上个世纪就有的算法,只是近些年来电脑的计算能力已非当年的那种计算水平,同时现在的训练数据很多,于是神经网络的相关算法又重新流行起来,因此卷积神经网络也一样流行。
-
1974年,Paul Werbos提出了误差反向传导来训练人工神经网络,使得训练多层神经网络成为可能。
-
1979年,Kunihiko Fukushima(福岛邦彦),提出了Neocognitron, 卷积、池化的概念基本形成。
-
1986年,Geoffrey Hinton与人合著了一篇论文:Learning representations by back-propagation errors。
-
1989年,Yann LeCun提出了一种用反向传导进行更新的卷积神经网络,称为LeNet。
-
1998年,Yann LeCun改进了原来的卷积网络,LeNet-5。
2.2 图像特征数量对神经网络效果压力
假设下图是一图片大小为28 * 28 的黑白图片时候,每一个像素点只有一个值(单通道)。那么总的数值个数为 784个特征。

那现在这张图片是彩色的,那么彩色图片由RGB三通道组成,也就意味着总的数值有28 28 3 = 2352个值。

从上面我们得到一张图片的输入是2352个特征值,即神经网路当中与若干个神经元连接,假设第一个隐层是10个神经元,那么也就是23520个权重参数。
如果图片再大一些呢,假设图片为1000 *1000* 3,那么总共有3百万数值,同样接入10个神经元,那么就是3千万个权重参数。这样的参数大小,神经网络参数更新需要大量的计算不说,也很难达到更好的效果,大家就不倾向于使用多层神经网络了。
所以就有了卷积神经网络的流行,那么卷积神经网络为什么大家会选择它。那么先来介绍感受野以及边缘检测的概念。
2.3 感受野
1962年Hubel和Wiesel通过对猫视觉皮层细胞的研究,提出了感受野(receptive field)的概念, Fukushima基于感受野概念提出的神经认知机(neocognitron)可以看作是卷积神经网络的第一个实现网络。
单个感受器与许多感觉神经纤维相联系,感觉信息是通过许多感受神经纤维发放总和性的空间与时间类型不同的冲动,相当于经过编码来传递。
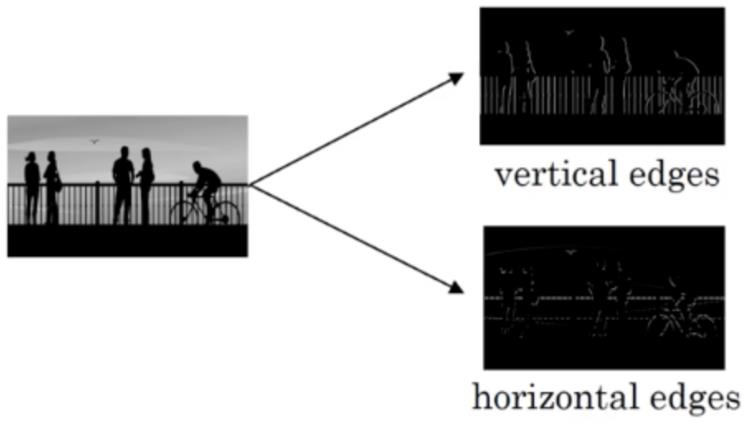
2.4 边缘检测
为了能够用更少的参数,检测出更多的信息,基于上面的感受野思想。通常神经网络需要检测出物体最明显的垂直和水平边缘来区分物体。比如
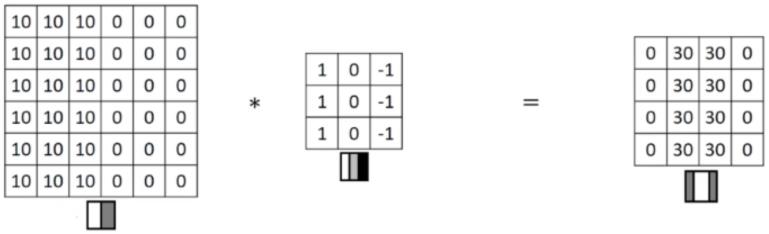
看一个列子,一个 6×6的图像卷积与一个3×3的过滤器(Filter or kenel)进行卷积运算(符号为 *),* 也可能是矩阵乘法所以通常特别指定是卷积的时候代表卷积意思。
-
相当于将 Filter 放在Image 上,从左到右、从上到下地(默认一个像素)移动过整个Image,分别计算 ImageImage 被 Filter 盖住的部分与 Filter的逐元素乘积的和
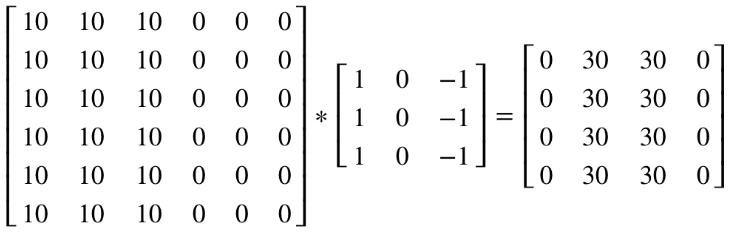
在这个6×6 的图像中,左边一半像素的值全是 10,右边一半像素的值全是 0,中间是一条非常明显的垂直边缘。这个图像与过滤器卷积的结果中,中间两列的值都是 30,两边两列的值都是 0,即检测到了原 6×66×6 图像中的垂直边缘。
注:虽然看上去非常粗,是因为我们的图像太小,只有5个像素长、宽,所以最终得到结果看到的是两个像素位置,如果在一个500 x 500的图当中,就是一个竖直的边缘了。
随着深度学习的发展,我们需要检测更复杂的图像中的边缘,与其使用由人手工设计的过滤器,还可以将过滤器中的数值作为参数,通过反向传播来学习得到。算法可以根据实际数据来选择合适的检测目标,无论是检测水平边缘、垂直边缘还是其他角度的边缘,并习得图像的低层特征。
三 图片卷积实操
3.1 均值滤波
# 登月图
moon = plt.imread('./moonlanding.png')
print(moon.shape) # (474, 630)
plt.figure(figsize=(10, 8))
plt.imshow(moon, cmap = 'gray')
# 均值滤波 # 平滑处理, 用卷积直接扫描
input_img = tf.constant(moon.reshape(1, 474, 630, 1), dtype = tf.float32)
filters = tf.constant(np.array([[1/9, 1/9, 1/9], [1/9, 1/9, 1/9], [1/9, 1/9, 1/9]]).reshape(3, 3, 1, 1),
dtype = tf.float32)
strides = [1, 1, 1, 1]
conv2d = tf.nn.conv2d(input = input_img, filters= filters, strides= strides, padding= 'SAME')
plt.figure(figsize= (10, 8))
plt.imshow(conv2d.numpy().reshape(474, 630), cmap = 'gray')
# 高斯滤波 # 平滑处理, 用卷积直接扫描
input_img = tf.constant(moon.reshape(1, 474, 630, 1), dtype = tf.float32)
filters = tf.constant(np.array([[1/9, 2/9, 1/9], [2/9, 3/9, 2/9], [1/9, 2/9, 1/9]]
).reshape(3, 3, 1, 1), dtype = tf.float32)
strides = [1, 1, 1, 1]
conv2d = tf.nn.conv2d(input = input_img, filters= filters, strides= strides, padding= 'SAME')
plt.figure(figsize= (10, 8))
plt.imshow(conv2d.numpy().reshape(474, 630), cmap = 'gray')
# 均值滤波 # 平滑处理, 用卷积直接扫描
input_img = tf.constant(moon.reshape(1, 474, 630, 1), dtype = tf.float32)
filters = tf.constant(np.array([[9/9, 9/9, 9/9, 9/9, 9/9], [9/9, 9/9, 9/9, 9/9, 9/9],
[9/9, 9/9, 9/9, 9/9, 9/9], [9/9, 9/9, 9/9, 9/9, 9/9],
[9/9, 9/9, 9/9, 9/9, 9/9]]).reshape(5, 5, 1, 1), dtype = tf.float32)
strides = [1, 1, 1, 1]
conv2d = tf.nn.conv2d(input = input_img, filters= filters, strides= strides, padding= 'SAME')
plt.figure(figsize= (10, 8))
plt.imshow(conv2d.numpy().reshape(474, 630), cmap = 'gray')
3.2 边缘检测
cat = plt.imread('./cat.jpg')
plt.figure(figsize= (12, 8))
plt.imshow(cat)
# 把猫变成黑白图片
cat_gray = cat.mean(axis = 2)
plt.figure(figsize= (12, 8))
plt.imshow(cat_gray, cmap = 'gray')
# 边缘检测
input_img = tf.constant(cat_gray.reshape(1, 456, 730, 1), dtype = tf.float32)
filters = tf.constant(np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]]
).reshape(3, 3, 1, 1), dtype = tf.float32)
strides = [1, 1, 1, 1]
conv2d = tf.nn.conv2d(input = input_img, filters= filters, strides= strides, padding= 'SAME')
plt.figure(figsize= (10, 8))
plt.imshow(conv2d.numpy().reshape(456, 730), cmap = 'gray')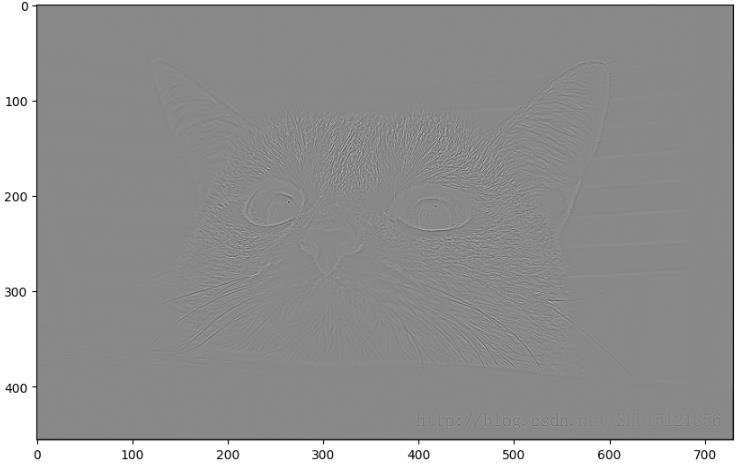
3.3 锐化效果
# 边缘检测
input_img = tf.constant(cat_gray.reshape(1, 456, 730, 1), dtype = tf.float32)
filters = tf.constant(np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]]
).reshape(3, 3, 1, 1), dtype = tf.float32)
strides = [1, 1, 1, 1]
conv2d = tf.nn.conv2d(input = input_img, filters= filters, strides= strides, padding= 'SAME')
plt.figure(figsize= (10, 8))
plt.imshow(conv2d.numpy().reshape(456, 730), cmap = 'gray')
europe = plt.imread('./欧式.jpg')
plt.figure(figsize=(10, 8))
plt.imshow(europe)
print(europe.shape) # (582, 1024, 3)
# 彩色图片
# 把每个通道当做一张图 # transpose通过索引调换维度位置
input_img = tf.constant(europe.reshape(1, 582, 1024, 3).transpose([3, 1, 2, 0]), dtype = tf.float32)
filters = tf.constant(np.array([[1/9, 1/9, 1/9], [1/9, 1/9, 1/9], [1/9, 1/9, 1/9]]
).reshape(3, 3, 1, 1), dtype = tf.float32)
strides = [1, 1, 1, 1]
conv2d = tf.nn.conv2d(input = input_img, filters= filters, strides= strides, padding= 'SAME')
print(conv2d.shape) # (3, 582, 1024, 1)
plt.figure(figsize= (10, 8))
plt.imshow(conv2d.numpy().reshape(3, 582, 1024).transpose([1, 2, 0])/255)
以上是关于25- 卷积神经网络(CNN)原理 (TensorFlow系列) (深度学习)的主要内容,如果未能解决你的问题,请参考以下文章